标签:cat lua 很多 集合 lazy submit 输出 工具 程序启动
1、基本架构
(1)、应用程序
Spark 应用程序由一个驱动器进程和一组执行器进程组成。驱动进程运行 main()函数,位于集群中的一个节点上,它负责三件事:维护 Spark 应用程序的相关信息;回应用户的程序或输入;分析任务并分发给若干执行器进行处理。驱动器是必须的,它是 Spark 应用程序的核心,它在应用程序执行的整个生命周期中维护着所有相关信息。执行器负责执行驱动器分配给它的实际计算工作,这意味着每个执行器只负责两件事:执行由驱动器分配给它的代码,并将该执行器的计算状态报告给运行驱动器的节点。
图 1-1 演示了集群管理器如何控制物理机器并为 Spark 应用程序分配资源,这个集群管理器可以是三个核心集群管理器之中的任意一个:Spark 的独立集群管理器、YARN 或 Mesos。这意味着可以同时在群集上运行多个 Spark 应用程序。
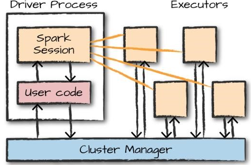
图 1-1
(2)、spark api
Spark 有两套基本的 API:低级“非结构化”API 和更高级别的结构化 API.
(3)、启动spark
编写 Spark 应用程序时,我们需要一种将用户命令和数据发送给 Spark 的方法,通过创建一个 SparkSession
启动 Spark 的本地模式,运行./bin/spark-shell 打开 Scala 控制台来启动一个交互式会话,你也可以使用./bin/pyspark 启动 Python 控制台,这就启动了一个交互式 Spark 应用程序。还有一个向 Spark 提交独立应用程序的命令 spark-submit,你可以将预编译的应用程序提交给 Spark。
当以这种交互模式启动 Spark 时,你相当于隐式地创建了一个 SparkSession 来管理 Spark 应用程序。当你不是通过交互模式而是通过独立应用程序启动 Spark 时,你必须在应用程序代码中显式地创建 SparkSession 对象.
(4)、sparksession
通过名为 SparkSession 的驱动器来控制 Spark 应用程序,你需要创建一个 SparkSession 实例来在群集中执行用户定义的操作,每一个 Spark 应用程序都需要一个 SparkSession 与之对应。在 Scala 和 Python 中,当你启动控制台时,这个 SparkSession 就被实例化为一个名为 spark 的对象。
(5)、dataframe
DataFrame 是最常见的结构化 API,简单来说它是包含行和列的数据表。说明这些列和列类型的一些规则被称为模式(schema)
Spark 有几个核心抽象:Dataset,DataFrame,SQL 表和弹性分布式数据集(RDD)。这些不同的抽象都表示分布式数据集合
(6)、数据分区
为了让多个执行器并行地工作,Spark 将数据分解成多个数据块,每个数据块叫做一个分区。分区是位于集群中的一台物理机上的多行数据的集合,DataFrame 的分区也说明了在执行过程中,数据在集群中的物理分布。如果只有一个分区,即使拥有数千个执行器,Spark 也只有一个执行器在处理数据。类似地,如果有多个分区,但只有一个执行器,那么 Spark 仍然只有那一个执行器在处理数据,就是因为只有一个计算资源单位。
(7)、转换操作
具有窄依赖关系(narrow dependency)的转换操作(我们称之为窄转换)是每个输入分区仅决定一个输出分区的转换。1对1映射
具有宽依赖关系(wide dependency)的转换(或宽转换)是每个输入分区决定了多个输出分区。这种宽依赖关系的转换经常被叫做洗牌(shuffle)操作,它会在整个集群中执行互相交换分区数据的功能。1对多映射
(8)、惰性评估
惰性评估(lazy evaluation)的意思就是等到绝对需要时才执行计算。在 Spark 中,当用户表达一些对数据的操作时,不是立即修改数据,而是建立一个作用到原始数据的转换计划。Spark 会首先将这个计划编译为可以在集群中高效运行的流水线式的物理执行计划,然后等待,直到最后时刻才开始执行代码。这会带来很多好处,因为 Spark 可以优化整个从输入端到输出端的数据流。
(9)、动作操作
转换操作使我们能够建立逻辑转换计划。为了触发计算,我们需要运行一个动作操作(action)。一个动作指示 Spark 在一系列转换操作后计算一个结果。
(10)、用户接口
你可以通过 Spark 的 Web UI 监控一个作业的进度,Spark UI 占用驱动器节点的 4040 端口。如果你在本地模式下运行,你可以通过 http://localhost:4040 访问 Spark Web UI。
2、工具集
Spark 除了提供这些低级 API 和结构化 API,还包括一系列标准库来提供额外的功能。
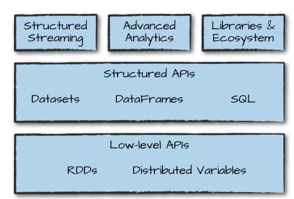
3、结构化API概述
结构化API是处理各种数据类型的工具,可处理非结构化的日志文件、半结构化的CSV文件以及高度结构化的Parquet文件。结构化
API指以下三种核心分布式集合类型的API:
Dataset 类型
DataFrame 类型
SQL 表和视图
Spark 是一个分布式编程模型,用户可以在其中指定转换操作(transformation)。多次转换操作后建立起指令的有向无环图。指令图的执行过程作为一个作业(job)由一个动作操作(action)触发,在执行过程中一个作业被分解为多个阶段(stage)和任务(task)在集群上行。转换操作和动作操作操纵的逻辑结构是 DataFrame 和Dataset,执行一次转换操作会都会创建一个新的 DataFrame 或Dataset,而动作操作则会触发计算,或者将 DataFrame 和 Dataset 转换成本地语言类型。
(1)、Schema数据模式
Schema 定义了 DataFrame 的列名和类型,可以手动定义或者从数据源读取模式(通常定义为模式读取)。
(2)、结构化 Spark 类型概述
Spark 实际上有它自己的编程语言,Spark 内部使用一个名为 Catalyst 的引擎,在计划制定和执行作业的过程中使用 Catalyst 来维护它自己的类型信息,这样就会带来很大的优化空间,这些优化可以显著提高性能。
(3)、DataFrame 与 Dataset 的比较
标签:cat lua 很多 集合 lazy submit 输出 工具 程序启动
原文地址:https://www.cnblogs.com/irvin-chen/p/14122475.html