标签:分享 用户 vat 不难 weight tput 可视化 字符 简洁
“Attention,Attention,还是Attention,看了三篇顶会论文,现在CVPR、ICCV都这么好发了么,随随便便加个Attention就算了不得的创新点?”这是曾经有段时间实验室大家读paper后很统一的的槽点。
你可能还在通过不断增加卷积层、池化层、全连接层以尽量让自己的网络结构“看起来”和别人的不太一样,也可能还在琢磨怎么从图像分割领域“借”点东西过来应用于图像识别领域。
对于很多科研小白来说,好不容易啃完了50+篇paper,脑子里灵光一闪顿悟了一个写下来手都直打哆嗦的创新点。然后发现了一个比想不到创新点更残酷的事实——一篇小论文里只有一个创新点还远远不够。
其他创新点那就只能尽量靠“凑”。
神经网络本身就有点玄学的味道,你可不知道加进去哪味佐料就能炼出来一颗神丹妙药。而这味“Attention”原料经很多神经网络的专业炼丹师妙手验证,它确实百搭又好用。
所以当你还在为小论文的创新点抓耳挠腮一筹莫展时,不妨试试神经网络结构里的百搭小助手---Attention注意力机制。

随着TensorFlow 2.0发布,Keras实现的深层网络开始备受开发者关注。在TensorFlow 2.0中,Keras可以利用以下三个强大的高层神经网络API实现深度网络。
· sequence API——这是最简单的API,首先调动 model = Sequential()并不断添加层,例如 model.add(Dense(...)) .
· 函数式API——高级API,创建自定义模式,随机输入/输出。此处定义模块要小心谨慎,随便一点微小改动都会影响用户端。定义模型可以使用model = Model(inputs=[...],outputs=[...]) .
· 子类化API——高级API,可以将该模型定义为Python类。这里,在属类中定义模型的前向传递,Keras自动计算后向传递。

图片来源:Keras官方文档 主页
Keras作为一个专为支持快速实验而生的高层神经网咯API,与Tensorflow、Pytorch、Caffe这类深度学习框架相比,它更像是个神经网络接口。尽管它提供的底层弹性和灵活性要逊色于其他几种深度学习框架,然而它的模块高度封装,对用户非常友好,最易上手,用它把想法迅速输出为结果通常来说是不二之选。
所以,当你需要快速创建一个神经网络,并测试你的网络模块添加或删减得是否那么“得当”,不妨尝试使用下Keras这个非常好上手的API。
而上面说的Attention注意力机制,其实类似神经网络是参考人类大脑神经元的工作原理发展而来,Attention注意力模型也是巧妙借鉴了人类在发展过程中对于必要信息的着重关注同时自动忽略非必要信息的视觉注意力提取机制原理。
接下来,本篇将先从介绍“‘序列-序列’模型”入手,然后通过介绍“Attention注意力机制的实质”来表明为什么Attention机制对于序列-序列的模型来说非常重要,最后通过实例用Keras快速实现Attention Layer。

“序列-序列”模型(Sequence to Sequence Model)是深度学习模型的强大分支,旨在解决机器学习领域中最棘手的问题。例如:
· 机器翻译
· 聊天机器人
· 文本摘要
每个问题都分别面临着各自特定的挑战。例如,机器翻译必须处理不同的词序拓扑(即主谓宾语序)。因此,此“序列-序列”模型是解决复杂的神经语言程序学相关问题的必要武器。
“序列-序列”模型是如何应用于英&法机器翻译任务的呢?
“序列-序列”模型有两个组件,一个编码器和一个解码器。编码器将源语句转化为简洁的矢量(称为上下文矢量),其中解码器键入上下文矢量中,并利用解码表示执行计算机翻译。
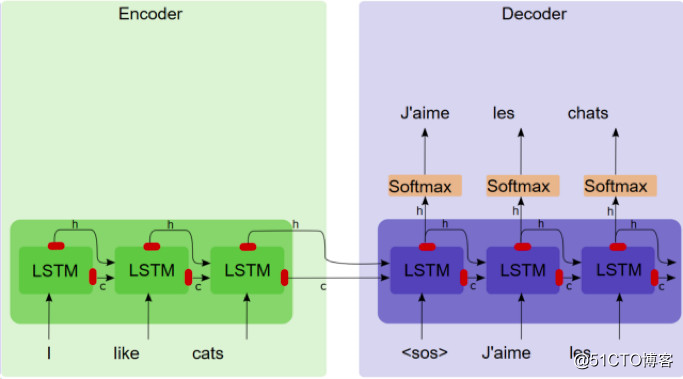
序列到序列模型
这种方法存在什么问题吗?
这种方法存在严重瓶颈。上下文矢量需要将给定源语句中的所有信息编码为包含几百个元素的向量。现在,为了融入相关语境,该矢量需要保留以下信息:
· 关于主语、宾语和谓语动词的信息
· 这些字符之间的交互
这个过程任务相当艰巨,特别是对于长句子而言。因此,需要更好的解决方案,这也是Attention机制被用于解决该瓶颈的初衷所在。

如果解码器可以访问过去的所有状态,而不只是上下文矢量,那会怎么样?这正是注意力机制所做的事情。每个解码步骤中,解码器都可以任意查看编码器的特定状态。在这里,我们将讨论巴赫达瑙注意机制(Bahdanau Attention)。下图描述了注意力机制的内部工作原理。
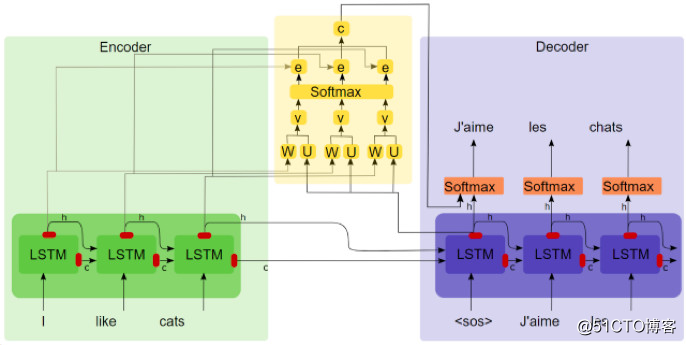
注意机制作用下的序列到序列模型
从图中不难看出,上下文矢量成为了所有编码器过去状态的加权和。事实上Attention机制从数学公式和代码实现上来看就是加权求和,而研究加权求和中权重的合理性配置正是Attention想要解决的问题。

目前的一些注意力机制运作起来会相当麻烦。而Keras注意力机制则采用了更模块化的方法,它在更细的层级上实现注意力机制(即给定解码器RNN/LSTM/GRU的每个解码器步骤)。
可以将Attention Layer用作任何层,例如,定义一个注意力层:
attn_layer = AttentionLayer(name=‘attention_layer‘)([encoder_out,decoder_out])这里提供了一个简单神经机器翻译(NMT)的示例,演示如何在NMT(nmt.py)中利使用注意层,下面给大家介绍些细节。

在这里,简要介绍一下利用注意力机制实现NMT的步骤。
首先定义编码器和解码器输入((源/目标字符)。它们都具有一定规格(批量大小、时间步骤、词汇表大小)。
encoder_inputs = Input(batch_shape=(batch_size,en_timesteps, en_vsize), name=‘encoder_inputs‘)
decoder_inputs = Input(batch_shape=(batch_size, fr_timesteps - 1, fr_vsize),name=‘decoder_inputs‘)定义编码器(注意return_sequences=True )。
encoder_gru =GRU(hidden_size, return_sequences=True, return_state=True, name=‘encoder_gru‘)
encoder_out, encoder_state = encoder_gru(encoder_inputs)定义解码器(注意return_sequences=True)。
decoder_gru =GRU(hidden_size, return_sequences=True, return_state=True, name=‘decoder_gru‘)
decoder_out, decoder_state = decoder_gru(decoder_inputs,initial_state=encoder_state)定义注意力层。输入进注意力层的是encoder_out (编码器输出序列)和 decoder_out (解码器输出序列)。
attn_layer =AttentionLayer(name=‘attention_layer‘)
attn_out, attn_states = attn_layer([encoder_out, decoder_out])连接 attn_out和 decoder_out并将其作为Softmax层的输入。
decoder_concat_input =Concatenate(axis=-1, name=‘concat_layer‘)([decoder_out, attn_out])定义 TimeDistributed Softmax层,并输入 decoder_concat_input。
dense =Dense(fr_vsize, activation=‘softmax‘, name=‘softmax_layer‘)
dense_time = TimeDistributed(dense, name=‘time_distributed_layer‘)
decoder_pred = dense_time(decoder_concat_input)定义全模型。
full_model =Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer=‘adam‘, loss=‘categorical_crossentropy‘)
事实上,这不仅实现了注意力机制,还提供了将注意力机制可视化的方法。因为对于每个解码步骤这一层都返回两个值:
· 注意力上下文矢量(用作解码器Softmax层的额外输入)
· 注意力权重(注意力机制的Softmax输出)
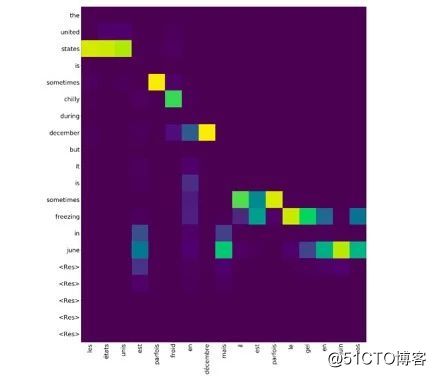
因此,通过可视化注意力权重,就能充分了解注意力在训练/推理过程中所做的事情。下面详细谈论讨论这个过程。

NMT推断需要完成以下步骤:
· 获取编码器输出
· 定义一个解码器,执行解码器的单个步骤(因为我们需要提供该步骤的预测为下一步的输入做准备)
· 使用编码器输出作为解码器的初始状态
· 执行解码,直到得到一个无效的单词/输出<EOS>/固定部署
让我们来看看如何利用该模型获得注意力权重。
for i in range(20):
dec_out, attention, dec_state =decoder_model.predict([enc_outs, dec_state, test_fr_onehot_seq])
dec_ind = np.argmax(dec_out,axis=-1)[0, 0]
...
attention_weights.append((dec_ind,attention))然后,需要将这个注意权重列表传递给 plot_attention_weights(nmt.py)以便获得带有其他参数的注意力热度图。绘图后的输出可能如下所示。
本文使用Keras实现了Attention Layer。对于顺序模型或者其他一些模型来说,注意力机制都非常重要,因为它确实十分百搭。
现有的实现注意力机制的方法要么过于老旧,要么还没有实现模块化。而恰好Keras可以为注意力机制的实现提供了一个不错的解决办法。
看完本文,你不妨赶紧去试试用Keras实现Attention机制是否真如我说的那么简单,说不定你遭遇的paper创新点瓶颈马上就能迎刃而解(Good Luck)。

编译组:杨雨心、柳玥
相关链接:
https://towardsdatascience.com/light-on-math-ml-attention-with-keras-dc8dbc1fad39
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
paper创新点毫无头绪?要不试试这个百搭的Attention?
标签:分享 用户 vat 不难 weight tput 可视化 字符 简洁
原文地址:https://blog.51cto.com/15057819/2567642