标签:resource 大小 集群 阿里 高可用 tab ppm jar 默认端口
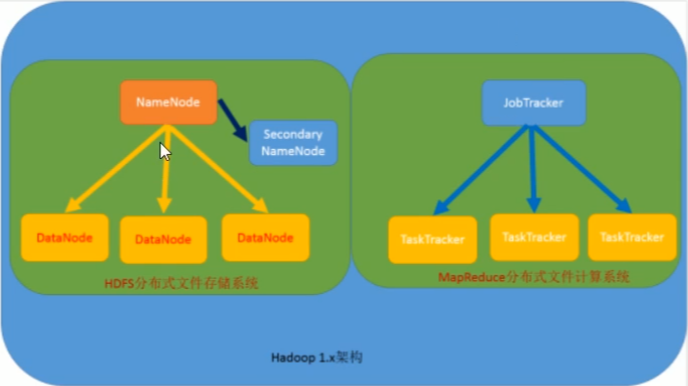
分布式文件系统核心模块:
namenode:集群中的主节点,管理元数据(文件的大小,文件的位置,文件的权限)。
secondaryNameNode:辅助namenode管理元数据信息。
dadanode:集群当中的从节点,主要存储集群中的各种数据。
分布式数据计算核心模块:
jobtracker:接收用户的计算请求,并分配任务给从节点。
tasktracker:负责执行主节点jobtracker分配的任务。
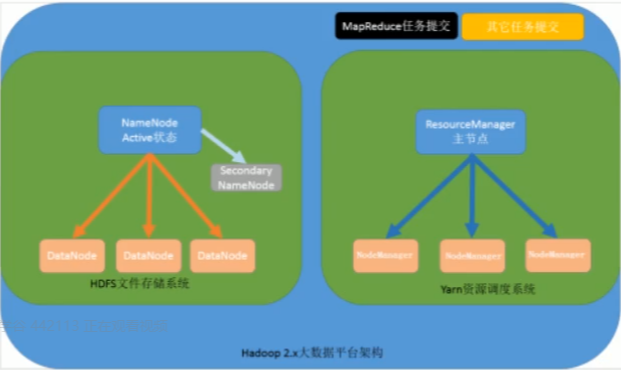
分布式文件系统核心模块:
namenode:集群中的主节点,管理元数据(文件的大小,文件的位置,文件的权限)。
secondaryNameNode:辅助namenode管理元数据信息。
dadanode:集群当中的从节点,主要存储集群中的各种数据。
分布式数据计算核心模块:
resourcemanager:接收用户的计算请求,并负责集群的资源分配。
nodemanager:负责执行主节点appmaster分配的任务。
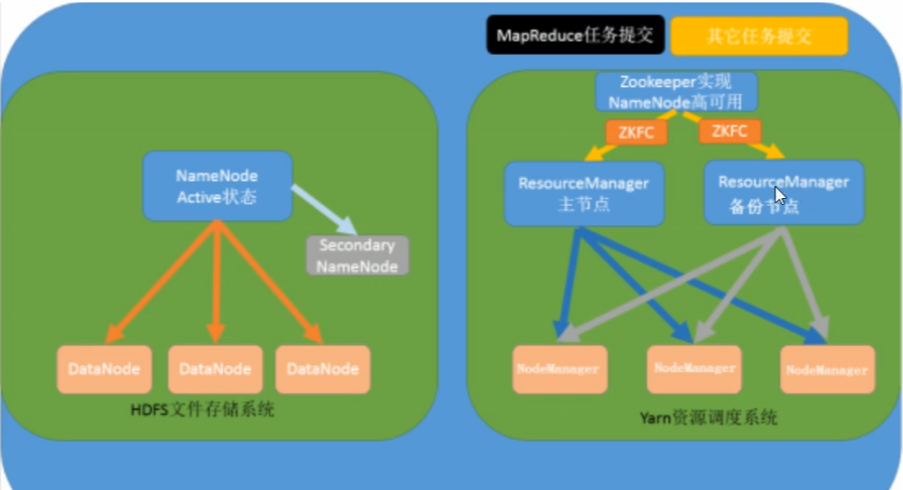
分布式文件系统核心模块:
namenode:集群中的主节点,管理元数据(文件的大小,文件的位置,文件的权限)。
secondaryNameNode:辅助namenode管理元数据信息。
dadanode:集群当中的从节点,主要存储集群中的各种数据。
分布式数据计算核心模块:
resourcemanager:接收用户的计算请求,并负责集群的资源分配,通过zookeeper实现resourcemanager高可用。
nodemanager:负责执行主节点appmaster分配的任务。
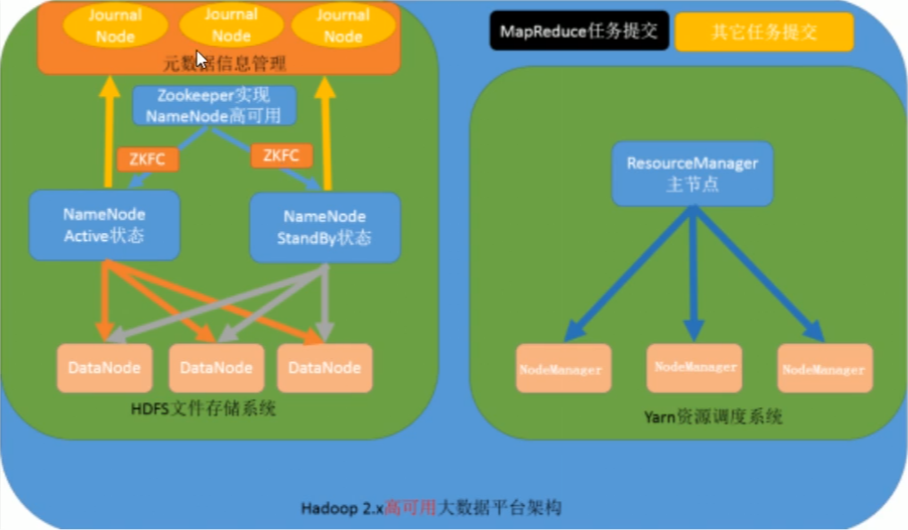
分布式文件系统核心模块:
namenode:集群中的主节点,管理元数据(文件的大小,文件的位置,文件的权限),namenode有两个形成高可用。
secondaryNameNode:辅助namenode管理元数据信息。
dadanode:集群当中的从节点,主要存储集群中的各种数据。
分布式数据计算核心模块:
resourcemanager:接收用户的计算请求,并负责集群的资源分配。
nodemanager:负责执行主节点appmaster分配的任务。
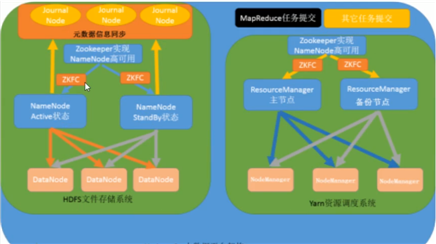
分布式文件系统核心模块:
namenode:集群中的主节点,管理元数据(文件的大小,文件的位置,文件的权限),namenode有两个形成高可用。
secondaryNameNode:辅助namenode管理元数据信息。
dadanode:集群当中的从节点,主要存储集群中的各种数据。
分布式数据计算核心模块:
resourcemanager:接收用户的计算请求,并负责集群的资源分配,通过zookeeper实现resourcemanager高可用。
nodemanager:负责执行主节点appmaster分配的任务。
hadoop3在架构,角色上和hadoop2没有区别, 主要的区别是功能和性能上的区别。
jdk: 最低版本1.8
存储:新增纠删码存储技术Erasure Code(EC).
在hadoop2中数据高可用主要是备份来进行的, 1G的数据3个副本需要3G的存储空间存储.
在hadoop3中只需要1.5倍数据来保证数据高可用,通过计算的方式将丢失数据计算出来.
优点:节省存储空间.
缺点:计算开销需要一些时间.
热数据通过备份机制存储, 冷数据(几年前不怎么查询的数据)通过纠删码机制.
HA:支持两个以上的namenode.
文件系统:增加对微软Azure Data Lake和阿里云OSS文件系统的支持.
功能:新增datanode磁盘复制均衡.
YARN timeline service v.2: 提升扩展性和可靠性.
支持Opportunistic Containers和Distributed Scheduling.
容器资源类型: 支持对CPU和内存之外的资源的配置, 如GPU和本地存储资源.
新的图形化监控界面.
客户端jar引用优化: 将hadoop client的第三方依赖以shading dependency的方式隔离在单一jar包中,避免hadoop渗透到应用程序的类路径中.
mapreduce任务级本地优化: shuffle密集型任务, 性能提升30%.
修改许多服务默认端口.
第三方依赖包升级: jersey, netty, cglib等.
优化对守护进程和mr程序的堆管理配置.
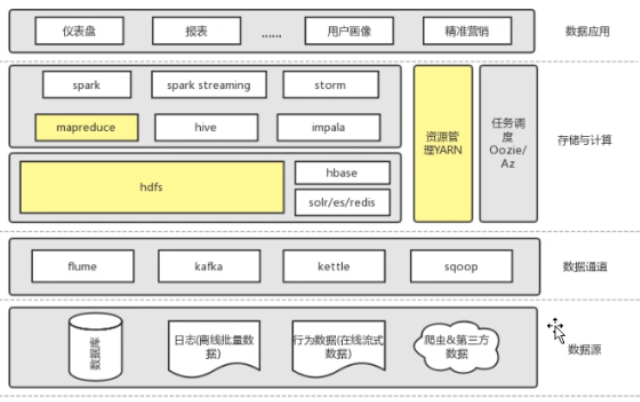
hadoop主要职责: 存储, 计算, 资源调度
| hadoop1 | hadoop2/hadoop3 | |
| 数据处理 | 支持批处理 | 支持批, 流,交互式处理 |
| 架构 | mapreduce,hdfs | mapreduce, hdfs2, yarn |
| 存储高可用 | master没有高可用 | master节点高可用 |
| 时间 | 版本 |
| 2007 | 0.14.1 |
| 2010 | 0.20 |
| 2012 |
1.X 2.X |
| 2017 | 3.X |
标签:resource 大小 集群 阿里 高可用 tab ppm jar 默认端口
原文地址:https://www.cnblogs.com/chong-zuo3322/p/14171604.html