标签:效率 时间 根据 mic 相关 最可 编码 距离 邻居
k近邻(k-Nearest Neighbor,简称kNN)学习是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于k个“邻居”的信息来进行预测。近似最近邻检索的核心思想:搜索可能是近邻的数据项而不再只局限于返回最可能的项目,在牺牲可接受范围内的精度的情况下提高检索效率。
3.总结
根据以上内容可得以下图(图中的不通顺地方是因为我不知道该怎么翻译图片)
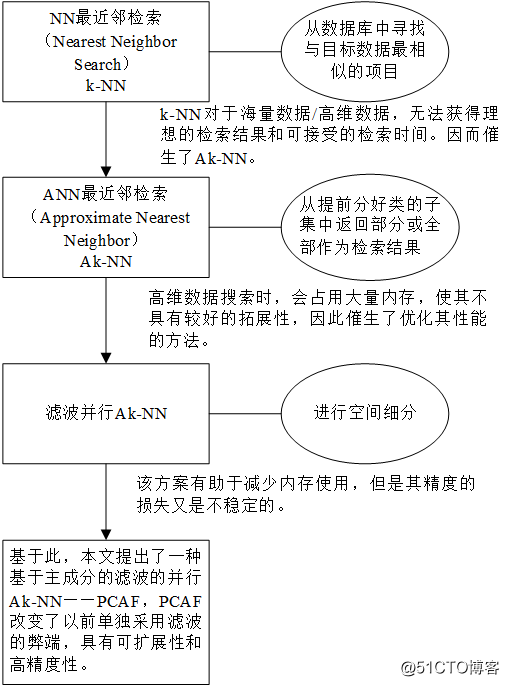
关于PCAF的相关内容及具体实现过程以后会实现。未完待续..
标签:效率 时间 根据 mic 相关 最可 编码 距离 邻居
原文地址:https://blog.51cto.com/15069472/2577214