标签:定义 teacher 数值 创建目录 ring awd 详解 toc 描述
Protocol Buffers 是一种与语言、平台无关,可扩展的序列化结构化数据的方法,常用于通信协议,数据存储等等。相较于 JSON、XML,它更小、更快、更简单,因此也更受开发人员的青眯。
基本语法
syntax = “proto3”;
package model;
service MyServ {
rpc Query(Request) returns(Reply);
}
message Student {
int64 id = 1;
string name = 2;
int32 age = 3;
}
定义完 proto文件后,生成相应语言的代码
protoc --proto_path=. --go_out=plugins=grpc,paths=source_relative:. xxxx.proto
--proto_path 或者 -I 参数用以指定所编译源码(包括直接编译的和被导入的 proto 文件)的搜索路径
--go_out 参数之间用逗号隔开,最后用冒号来指定代码目录架构的生成位置 ,--go_out=plugins=grpc参数来生成gRPC相关代码,如果不加plugins=grpc,就只生成message数据
eg:--go_out=plugins=grpc,paths=import:. 。注意一下 paths 参数,他有两个选项,import 和 source_relative 。默认为 import ,代表按照生成的 go 代码的包的全路径去创建目录层级,source_relative 代表按照 proto 源文件的目录层级去创建 go 代码的目录层级,如果目录已存在则不用创建
protoc是通过插件机制实现对不同语言的支持。比如 --xxx_out 参数,那么protoc将首先查询是否有内置的xxx插件,如果没有内置的xxx插件那么将继续查询当前系统中是否存在protoc-gen-xxx命名的可执行程序。
例如,生成 c++代码
protoc -I . --grpc_out=. --plugin=protoc-gen-grpc=`which grpc_cpp_plugin` --cpp_out=. *.proto
proto文件为了方便,会把公共的一些字段放到一个proto文件里,如果有需要,就把这个proto文件impot进去,比如,我现在的组织结构好下
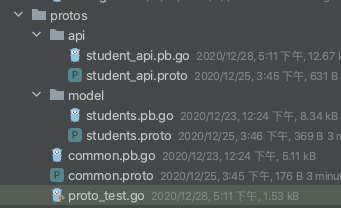
common.proto 文件里只有个简单的message
syntax = "proto3";
package protos;
option go_package = "protos";
option java_package = "com.proto";
message Result {
string code = 1;
string desc = 2;
bytes data = 3;
}
目录api里student_api.proto
在这个文件里,我们导入了common.proto,还有其他需要的文件
syntax = "proto3";
package api;
option go_package = "protos/api";
option java_package = "com.proto.api";
import "protos/common.proto";
import "protos/model/students.proto";
import "google/protobuf/empty.proto";
service StudentSrv {
rpc NewStudent(model.Student) returns (protos.Result);
rpc StudentByID(QueryStudent) returns (QueryStudentResponse);
rpc AllStudent(google.protobuf.Empty) returns(stream QueryStudentResponse);
rpc StudentInfo(stream QueryStudent) returns(stream QueryStudentResponse);
}
message QueryStudent {
int64 id = 1;
}
message QueryStudentResponse {
repeated model.Student studentList = 1;
}
在执行protoc的时候,我们要指定这些需文件的查找路径,在项目的根目录里执行protoc进行代码生成
protoc -I=. --go_out=plugins=grpc:. --go_opt=paths=source_relative protos/api/*.proto
上面的-I指定了当前目录,就是说可以从当前目录开始找proto文件
以 student.proto为例
syntax = "proto3";
package model;
option go_package = "protos/model";
option java_package = "com.proto.model";
message Student {
int64 id = 1;
string name = 2;
int32 age = 3;
}
message StudentList {
string class = 1;
repeated Student students = 2;
string teacher = 3;
repeated int64 score = 4;
}
执行完protoc后,大概看一下生成的的go文件
type Student struct {
state protoimpl.MessageState
sizeCache protoimpl.SizeCache
unknownFields protoimpl.UnknownFields
Id int64 `protobuf:"varint,1,opt,name=id,proto3" json:"id,omitempty"`
Name string `protobuf:"bytes,2,opt,name=name,proto3" json:"name,omitempty"`
Age int32 `protobuf:"varint,3,opt,name=age,proto3" json:"age,omitempty"`
}
state 保存 proto文件的反射信息 sizeCache序列化的数据总长度 unknownFields 不能解析的字段
剩下的字段是我们message里定义的信息,主要看一下tag信息
protobuf:"varint,1,opt,name=id,proto3" json:"id,omitempty",说明这个字段是protobuf的varint类型,index为1 name为id,使用proto3协议
还有一个byte数组的file_protos_model_students_proto_rawDesc
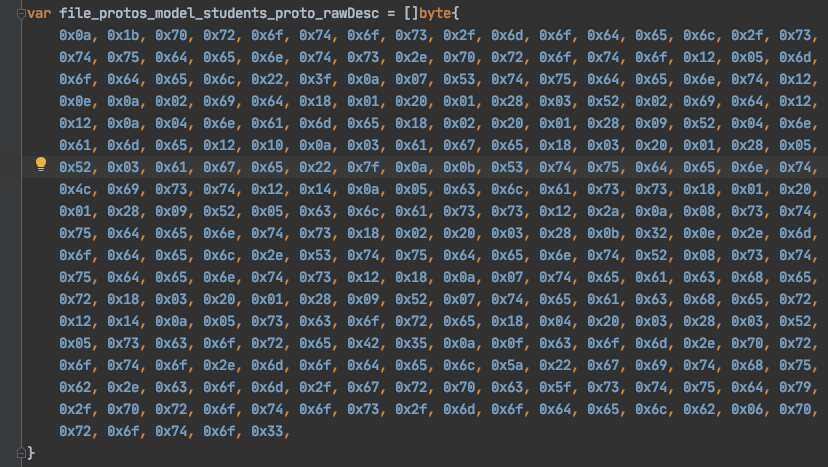
一眼看上去就有点蒙,这一坨是什么?开源的好处就是,我可以很清楚的看清他是做什么的,
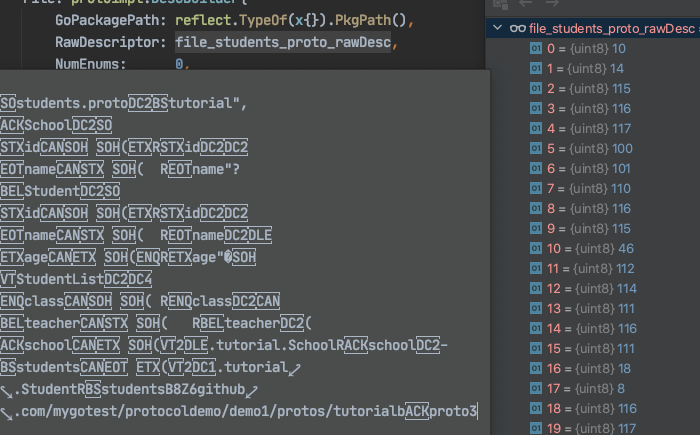
这个file_protos_model_students_proto_rawDesc是proto里数据的描述信息。如 proto的路径、包名称,message信息等等。
file_protos_model_students_proto_rawDesc描述信息有什么用呢?
当我们在执行proto.Marshal的时候,会对传入的参数Message进行验证,比如每个message字段的index、数据类型,是否和file_protos_model_students_proto_rawDesc一致。如果不一致就说明是有问题的。
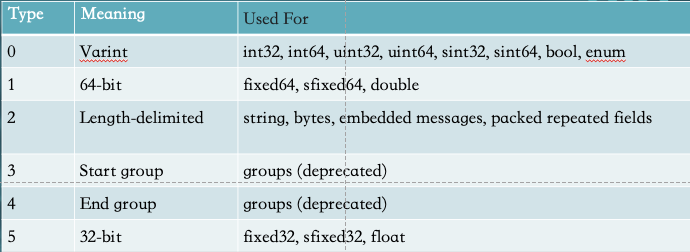
protobuf目前支持这5种数据类型,还有2个是已经废弃了。protobuf是语言无关的,也就是说,无论具体的语言支持哪些数据类型,在marshal的时候都要转换成这几种,在unmarshal的时候再转换成具体语言的类型
我们把一个结构转换成json
Student {
Id: 1,
Name: "孙悟空",
Age: 300,
}
{
"id": 1,
"name": "孙悟空",
"age": 300
}
转换成 protobuf 数据格式
1000 1 10010 1001 11100101 10101101 10011001 11100110 10000010 10011111 11100111 10101001 10111010 11000 10101100 10
转换成十进制
8 1 8 9 229 173 153 230 130 159 231 169 186 24 172 2
json一眼就能看懂是什么 ,protobuf数据格式看不明白,下面来解释这些数据都是什么。
先说一下第一个byte 1000 这个表示的是字段的index和类型,
protobuf 把一个字段的 index 和类型放在了一起
(field_number << 3) | wire_type
最后3个bit为类型,前面的bit为index
0000 1000 首位为标识位,index为 1 后三位为wire_type:0(Varint类型)再比如 10010 index: 2 wire_type: 2(Length-delimited类型)
Varint数据类型,最高位(msb)标志位,为1说明后面还有byte,0说明后面没有byte,使用后面的7个Bit位存储数值
Id: 1 protobuf对应的数据是0000 0001 这个很好理解
Age: 300 protobuf对应的数据是1010 1100 0000 0010,这个是怎么计算的呢?
protobuf数据 1010 1100 0000 0010
去掉最高位 010 1100 000 0010
连接剩余 0100101100
计算 256 + 32 + 8 + 4 = 300
字符串内存的表现形式protobuf一个汉字占3个byte
“孙悟空”内存的数据
11100101 10101101 10011001 11100110 10000010 10011111 11100111 10101001 10111010
“孙悟空”前面的一个byte:1001
这个数值有什么意义?对,字符串长度 9
Length-delimited类型的数据第一个byte是数据的长度,后面是具体的数据信息,数据大同小异
标签:定义 teacher 数值 创建目录 ring awd 详解 toc 描述
原文地址:https://www.cnblogs.com/li-peng/p/14201079.html