标签:output tab property 泛化 idg hid tip die log
https://scikit-learn.org/stable/modules/multiclass.html#
sklearn 支持如下典型类型学习
multiclass -- 多类别
mulitlabel -- 多标签
multioutput -- 多输出
引入元模型 meta-estimators, 来实现这些类型的学习,将复杂的学习任务拆分为一些简单任务的集合, 对于每个简单任务应用具体模型。
元模型的属于是 基模型 (base estimator), 就是具体的学习模型。
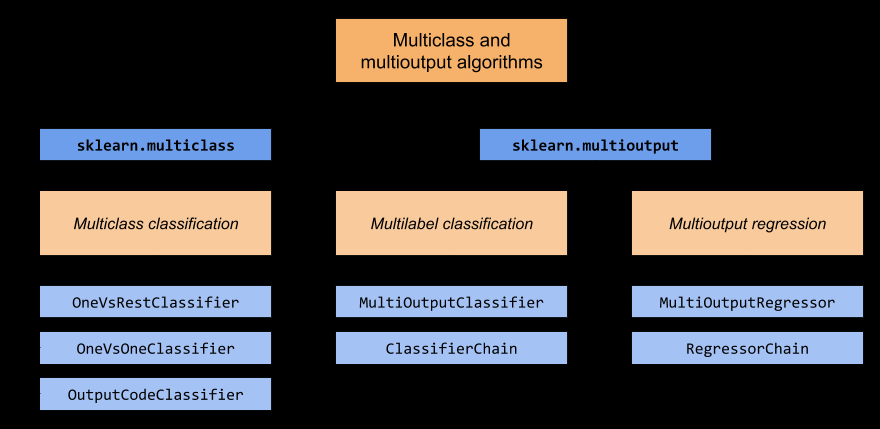
如下图,提供了 multiclass 和 multioutput 子库的结构,以及其包括的元模型。
其中多标签 multilabel 仅仅是 multioutput的一种具体情况。
注: 下文中 提到的 multiclass-multiouput
而 multiclass-multiouput 又是 multilabel的泛化情况, 即更加一般的情况。
因为 multilabel仅仅是标注的作用, 其值是binary, 即 true 和 false
multiclass-output, 其值是 multiclass, 任意数量的分类。
This section of the user guide covers functionality related to multi-learning problems, including multiclass, multilabel, and multioutput classification and regression.
The modules in this section implement meta-estimators, which require a base estimator to be provided in their constructor. Meta-estimators extend the functionality of the base estimator to support multi-learning problems, which is accomplished by transforming the multi-learning problem into a set of simpler problems, then fitting one estimator per problem.
This section covers two modules:
sklearn.multiclassandsklearn.multioutput. The chart below demonstrates the problem types that each module is responsible for, and the corresponding meta-estimators that each module provides.
模型分类特征表:
前面三个都是面向离散目标(分类), 最后一个面向连续型/数值型目标(回归)
后三个目标数目是2个及其以上, 属于multioutput类型。
The table below provides a quick reference on the differences between problem types. More detailed explanations can be found in subsequent sections of this guide.
Number of targets
Target cardinality
Valid
type_of_targetMulticlass classification
1
>2
‘multiclass’
Multilabel classification
>1
2 (0 or 1)
‘multilabel-indicator’
Multiclass-multioutput classification
>1
>2
‘multiclass-multioutput’
Multioutput regression
>1
Continuous
‘continuous-multioutput’
Below is a summary of scikit-learn estimators that have multi-learning support built-in, grouped by strategy. You don’t need the meta-estimators provided by this section if you’re using one of these estimators. However, meta-estimators can provide additional strategies beyond what is built-in:
Inherently multiclass:
svm.LinearSVC(setting multi_class=”crammer_singer”)
linear_model.LogisticRegression(setting multi_class=”multinomial”)
linear_model.LogisticRegressionCV(setting multi_class=”multinomial”)Multiclass as One-Vs-One:
gaussian_process.GaussianProcessClassifier(setting multi_class = “one_vs_one”)Multiclass as One-Vs-The-Rest:
gaussian_process.GaussianProcessClassifier(setting multi_class = “one_vs_rest”)
svm.LinearSVC(setting multi_class=”ovr”)
linear_model.LogisticRegression(setting multi_class=”ovr”)
linear_model.LogisticRegressionCV(setting multi_class=”ovr”)Support multilabel:
Support multiclass-multioutput:
https://scikit-learn.org/stable/modules/multiclass.html#multiclass-multioutput-classification
首先是多输出模型,
其次每个输出目标, 都是多类的。
Multiclass-multioutput classification (also known as multitask classification) is a classification task which labels each sample with a set of non-binary properties. Both the number of properties and the number of classes per property is greater than 2. A single estimator thus handles several joint classification tasks. This is both a generalization of the multilabel classification task, which only considers binary attributes, as well as a generalization of the multiclass classification task, where only one property is considered.
For example, classification of the properties “type of fruit” and “colour” for a set of images of fruit. The property “type of fruit” has the possible classes: “apple”, “pear” and “orange”. The property “colour” has the possible classes: “green”, “red”, “yellow” and “orange”. Each sample is an image of a fruit, a label is output for both properties and each label is one of the possible classes of the corresponding property.
Note that all classifiers handling multiclass-multioutput (also known as multitask classification) tasks, support the multilabel classification task as a special case. Multitask classification is similar to the multioutput classification task with different model formulations. For more information, see the relevant estimator documentation.
目标的值, 不仅仅是true和false
1.12.3.1. Target format
A valid representation of multioutput
yis a dense matrix of shape(n_samples, n_classes)of class labels. A column wise concatenation of 1d multiclass variables. An example ofyfor 3 samples:>>> y = np.array([[‘apple‘, ‘green‘], [‘orange‘, ‘orange‘], [‘pear‘, ‘green‘]]) >>> print(y) [[‘apple‘ ‘green‘] [‘orange‘ ‘orange‘] [‘pear‘ ‘green‘]]
https://scikit-learn.org/stable/modules/multiclass.html#multioutput-regression
多输出回归
首先是属于multiouput类型,
其次是回归,限定的每个目标都是数值型。
例如 预测某个地方的 风向的风速, 都是数值, 但是是两个目标。
Multioutput regression predicts multiple numerical properties for each sample. Each property is a numerical variable and the number of properties to be predicted for each sample is greater than or equal to 2. Some estimators that support multioutput regression are faster than just running
n_outputestimators.For example, prediction of both wind speed and wind direction, in degrees, using data obtained at a certain location. Each sample would be data obtained at one location and both wind speed and direction would be output for each sample.
Target format
A valid representation of multioutput
yis a dense matrix of shape(n_samples, n_classes)of floats. A column wise concatenation of continuous variables. An example ofyfor 3 samples:>>> y = np.array([[31.4, 94], [40.5, 109], [25.0, 30]]) >>> print(y) [[ 31.4 94. ] [ 40.5 109. ] [ 25. 30. ]]
同 MultiOutputClassifier, 将目标看成是独立的, 不相关的。
对于每个目标, 都训练单独的模型。
Multioutput regression support can be added to any regressor with
MultiOutputRegressor. This strategy consists of fitting one regressor per target. Since each target is represented by exactly one regressor it is possible to gain knowledge about the target by inspecting its corresponding regressor. AsMultiOutputRegressorfits one regressor per target it can not take advantage of correlations between targets.
>>> from sklearn.datasets import make_regression >>> from sklearn.multioutput import MultiOutputRegressor >>> from sklearn.ensemble import GradientBoostingRegressor >>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1) >>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X) array([[-154.75474165, -147.03498585, -50.03812219], [ 7.12165031, 5.12914884, -81.46081961], [-187.8948621 , -100.44373091, 13.88978285], [-141.62745778, 95.02891072, -191.48204257], [ 97.03260883, 165.34867495, 139.52003279], [ 123.92529176, 21.25719016, -7.84253 ], [-122.25193977, -85.16443186, -107.12274212], [ -30.170388 , -94.80956739, 12.16979946], [ 140.72667194, 176.50941682, -17.50447799], [ 149.37967282, -81.15699552, -5.72850319]])
同 ClassifierChain, 将目标定义为相关的, 采用链式反馈, 将模型链接起来。
Regressor chains (see
RegressorChain) is analogous toClassifierChainas a way of combining a number of regressions into a single multi-target model that is capable of exploiting correlations among targets.
Multiclass and multioutput overview of sklearn
标签:output tab property 泛化 idg hid tip die log
原文地址:https://www.cnblogs.com/lightsong/p/14212456.html