标签:七天 ati efi 数据 center 空值 indent 遍历 form
来源:https://mp.weixin.qq.com/s/NdvHxOtVB7AS5P75QdVO7Q
1、表层面
1.1 利用分区表优化
1.2 利用分桶表优化
1.3 选择合适的文件存储格式
1.4 选择合适的压缩格式
2、HQL层面优化
2.1 执行计划
2.1 列、行、分区裁剪
2.2 谓词下推
2.3 合并小文件
2.4 合理设置MapTask并行度
2.5 合理设置ReduceTask并行度
2.6 Join优化
2.7 CBO优化
2.8 Group By优化
2.9 Order By优化
2.10 Count Distinct 优化
2.11 怎样写in/exists语句
2.12 使用 vectorization 矢量查询技术
2.13 多重插入模式
2.14 启动中间结果压缩
3、Hive架构层面
3.1 启用本地抓取(默认开启)
3.2 本地执行优化
3.3 JVM重用
3.4 并行执行
3.5 推测执行
3.6 Hive严格模式
4、数据倾斜
4.1 不同数据类型关联产生数据倾斜
4.2 空值过滤
4.3 group by
4.4 map join
4.5 开启数据倾斜是负载均衡
5、调优方案
5.1 日志表和用户表做链接
5.2 位图法求连续七天发朋友圈的用户
1.1 利用分区表优化
分区表 是在某一个或者几个维度上对数据进行分类存储,一个分区对应一个目录。如果筛选条件里有分区字段,那么 Hive 只需要遍历对应分区目录下的文件即可,不需要遍历全局数据,使得处理的数据量大大减少,从而提高查询效率。
也就是说:当一个 Hive 表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表,该字段即为分区字段。
CREATE TABLE page_view (viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT ‘IP Address of the User‘) PARTITIONED BY(date STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘1‘ STORED AS TEXTFILE;
1、当你意识到一个字段经常用来做where,建分区表,使用这个字段当做分区字段
2、在查询的时候,使用分区字段来过滤,就可以避免全表扫描。只需要扫描这张表的一个分区的数据即可
1.2 利用分桶表优化
跟分区的概念很相似,都是把数据分成多个不同的类别
1、分区:按照字段值来进行,一个分区,就只是包含这个值的所有记录
不是当前分区的数据一定不在当前分区
当前分区也只会包含当前这个分区值的数据
2、分桶:默认规则,Hash的方式
一个桶中会有多个不同的值
如果一个分桶中,包含了某个值,这个值的所有记录,必然都在这个分桶里面
Hive Bucket,分桶,是指将数据以指定列的值为key进行hash,hash到指定数目的桶里面,这样做的目的和分区表类似,是的筛选时不用全局遍历所有的数据,只需要遍历所在的桶就好了,这样也只可以支持高效采样。
其实最主要的作用就是 采样、join
如下例就是以 userid 这一列为 bucket 的依据,共设置 32 个 buckets
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT ‘IP Address of the User‘) COMMENT ‘This is the page view table‘ PARTITIONED BY(dt STRING, country STRING) CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
CLUSTERED BY(userid): 按照userid进行分桶
SORTED BY(viewTime): 按照viewTime进行桶内排序
INTO 32 BUCKETS: 分成多少个桶
两个表以相同方式(相同字段)划分桶,两个表的桶个数一定是倍数关系,这样在join的时候速度会大大增加
采样用的不多,也就不过多阐述了
1.3 选择合适的文件存储格式
在 HiveSQL 的 create table 语句中,可以使用 stored as … 指定表的存储格式。Apache Hive支持 Apache Hadoop 中使用的几种熟悉的文件格式,比如 TextFile、SequenceFile、RCFile、Avro、ORC、ParquetFile等。存储格式一般需要根据业务进行选择,在我们的实操中,绝大多数表都采用TextFile与Parquet两种存储格式之一。TextFile是最简单的存储格式,它是纯文本记录,也是Hive的默认格式。虽然它的磁盘开销比较大,查询效率也低,但它更多地是作为跳板来使用。RCFile、ORC、Parquet等格式的表都不能由文件直接导入数据,必须由TextFile来做中转。Parquet和ORC都是Apache旗下的开源列式存储格式。列式存储比起传统的行式存储更适合批量OLAP查询,并且也支持更好的压缩和编码。创建表时,特别是宽表,尽量使用 ORC、ParquetFile 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量。
TextFile
1、存储方式:行存储。默认格式,如果建表时不指定默认为此格式。,
2、每一行都是一条记录,每行都以换行符"\n"结尾。数据不做压缩时,磁盘会开销比较大,数据解析开销也
比较大。
3、可结合Gzip、Bzip2等压缩方式一起使用(系统会自动检查,查询时会自动解压),推荐选用可切分的压
缩算法。
Sequence File
1、一种Hadoop API提供的二进制文件,使用方便、可分割、个压缩的特点。
2、支持三种压缩选择:NONE、RECORD、BLOCK。RECORD压缩率低,一般建议使用BLOCK压缩
RC File
1、存储方式:数据按行分块,每块按照列存储 。
A、首先,将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。
B、其次,块数据列式存储,有利于数据压缩和快速的列存取。
2、相对来说,RCFile对于提升任务执行性能提升不大,但是能节省一些存储空间。可以使用升级版的ORC格
式。
ORC File
1、存储方式:数据按行分块,每块按照列存储
2、Hive提供的新格式,属于RCFile的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快,快速列存取。
3、ORC File会基于列创建索引,当查询的时候会很快。
Parquet File
1、存储方式:列式存储。
2、Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列查询,Parquet特别有用。Parquet一般使用Snappy、Gzip压缩。默认Snappy。
3、Parquet支持Impala 查询引擎。
4、表的文件存储格式尽量采用Parquet或ORC,不仅降低存储量,还优化了查询,压缩,表关联等性能
1.4 选择合适的压缩格式
Hive 语句最终是转化为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在与 网络IO 和 磁盘IO,要解决性能瓶颈,最主要的是 减少数据量,对数据进行压缩是个好方式。压缩虽然是减少了数据量,但是压缩过程要消耗 CPU,但是在 Hadoop 中,往往性能瓶颈不在于 CPU,CPU 压力并不大,所以压缩充分利用了比较空闲的 CPU。
常用压缩方法对比
| 压缩格式 | 是否可拆分 | 是否自带 | 压缩率 | 速度 | 是否hadoop自带 |
|---|---|---|---|---|---|
| gzip | 否 | 是 | 很高 | 比较快 | 是 |
| lzo | 是 | 是 | 比较高 | 很快 | 否 |
| snappy | 否 | 是 | 比较高 | 很快 | 否 |
| bzip2 | 是 | 否 | 最高 | 慢 | 是 |
压缩率对比
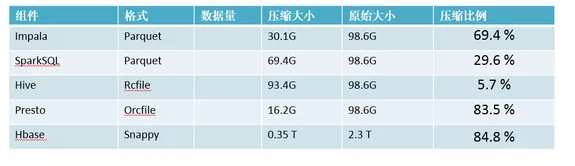
如何选择压缩方式呢?
1、压缩比例
2、解压缩速度
3、是否支持split
支持切割的文件可以并行的有多个mapper程序处理大数据文件,一般我们选择的都是支持切分的!
压缩带来的缺点和优点
1、计算密集型,不压缩,否则会进一步增加cpu的负担,真实的场景中hive对cpu的压力很小
2、网络密集型,推荐压缩,减小网络数据传输
# Job 输出文件按照 Block ## 默认值是false set mapreduce.output.fileoutputformat.compress=true; ## 默认值是Record set mapreduce.output.fileoutputformat.compress.type=BLOCK; set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.lzo.LzoCodec; # Map 输出结结果进行压缩 set mapred.map.output.compress=true; set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.lzo.LzoCodec; # 对 Hive 输出结果和中间都进行压缩 set hive.exec.compress.output=true ## 默认值是false,不压缩 set hive.exec.compress.intermediate=true ## 默认值是false,为true时MR设置的压缩才启用
Hive基础(二十二):面试题:Hive调优全方位指南(一)
标签:七天 ati efi 数据 center 空值 indent 遍历 form
原文地址:https://www.cnblogs.com/qiu-hua/p/14220742.html