标签:保存 必须 开发 纯粹 for unsigned 风格 ide lazy
GPU编程和流式多处理器(四)
单精度浮点支持是GPU计算的主力军。GPU已经过优化,可以在此数据类型上原生提供高性能,不仅适用于核心标准IEEE操作(例如加法和乘法),还适用于非标准操作(例如对先验的近似(例如sin()和log()))。32位值与整数保存在同一寄存器文件中,因此单精度浮点值和32位整数(使用__float_as_int()和__int_as_float())之间的强制转换是免费的。
编译器自动将浮点值的+,–和*运算符转换为加,乘和乘加指令。所述__fadd_rn()和__fmul_rn()内部函数可以被用于加入抑制融合和乘法操作进入乘加指令。
对于具有2.x或更高版本的计算能力的设备,使用--prec-div = true编译代码时,除法运算符符合IEEE规定。对于具有计算能力1.x的设备或对于具有计算能力2.x的设备,当使用--prec-div = false编译代码时,除法运算符和__fdividef(x,y)具有相同的精度,但精度为2 126 <y <2 128,__fdividef(x,y)的结果为零,而除法运算符的结果为正确。另外,对于2 126 <y <2 128,如果x为无穷大,则__fdividef(x,y)返回NaN,而除法运算符返回无穷大。
SM中的特殊功能单元(SFU)实现了六个常见超越功能的快速版本。
(摘自有关Tesla架构论文)摘录了受支持的操作和相应的精度。SFU并不能完全实现精度,但是它们可以很好地近似于这些功能,并且速度很快。对于比优化的CPU等效端口(例如25倍或更多)快得多的CUDA端口,代码很可能依赖SFU。
给出的内在函数访问SFU。指定--fast-math编译器选项将使编译器将常规C运行时调用替换为上面列出的相应SFU内部函数。
__saturate(x)如果x <0返回0 ,如果x> 1返回1,否则返回x。
带有SM 1.3的CUDA中添加了双精度浮点支持(最早在GeForce GTX 280中实现),而SM 2.0则提供了大大改进的双精度支持(功能和性能)。CUDA对双精度的硬件支持具有全速异常功能,并且从SM 2.x开始,符合IEEE 754 c的本机融合乘法加法指令(FMAD)。2008年,仅执行一个舍入步骤。FMAD除了是本质上有用的操作之外,还可以使某些功能(与Newton-Raphson迭代收敛)完全准确。
与单精度运算一样,编译器会自动将标准C运算符转换为乘法,加法和乘加指令。所述__dadd_rn()和__dmul_rn()内部函数可以被用于加入抑制融合和乘法操作进入乘加指令。
对于5位指数和10位有效数,半值具有足够的精度以用于HDR(高动态范围)图像,并可用于保存其他不需要浮点精度的值,例如角度。半精度值仅用于存储,而不用于计算,因此硬件仅提供指令以转换为32位或从32位转换。13这些指令以__halftofloat()和__floattohalf()内部函数公开。
float __halftofloat(unsigned short);
unsigned short __floattohalf(float);
这些内部函数使用unsigned short,因为C语言尚未标准化半浮点类型。
研究float → half转换操作是了解浮点编码和舍入细节的有用方法。因为这是一个简单的一元运算,所以我们可以专注于编码和舍入,而不会被浮点运算的细节和中间表示的精度所分散。
当从float转换为half时,对于任何太大而无法表示的float的正确输出是half infinity。任何太小而不能代表一半(甚至是反常的一半)的浮点数都必须固定为0.0。舍入为0.0的一半的最大浮点数为0x32FFFFFF或2.98 -8,而舍入为无穷大的一半的最小浮点数为65520.0。此范围内的float值可以转换为一半通过传播符号位,重新偏置指数(因为float的8位指数偏差为127,一半的5位指数偏差为15),然后将float的尾数四舍五入到最接近的一半尾数。在所有情况下,舍入都是简单的,除非输入值恰好落在两个可能的输出值之间。在这种情况下,IEEE标准指定四舍五入到“最近的偶数”值。在十进制算术中,这意味着四舍五入为1.5到2.0,但也四舍五入为2.5到2.0,以及(例如)四舍五入到0.5到0.0。
清单3显示了一个C例程,该例程完全复制了CUDA硬件实现的浮点到一半转换操作。变量exp和mag包含输入指数和“幅值”,尾数和指数以及被屏蔽的符号位。可以对幅度执行许多操作,例如比较和舍入操作,而无需分离指数和尾数。
清单3中使用的宏LG_MAKE_MASK创建具有给定位数的掩码:#define LG_MAKE_MASK(bits)((1 << bits)-1)。甲挥发性联合用于治疗相同的32位值作为浮子和无符号整型; 诸如*((float *)(&u))之类的习惯用法不是可移植的。该例程首先传播输入符号位并将其屏蔽掉。
提取幅度和指数后,该函数处理输入浮点为INF或NaN的特殊情况,并尽早退出。请注意,INF是带符号的,但NaN具有规范的无符号值。第50–80行将输入浮点值钳位到与可表示的半值相对应的最小值或最大值,然后重新计算钳位值的大小。不要被构造f32MinRInfin和f32MaxRf16_zero的复杂代码所迷惑;它们是分别具有值0x477ff000和0x32ffffff的常量。
例程的其余部分处理输出正常和异常的情况(输入异常在前面的代码中被钳位,因此mag对应于正常float)。与钳位代码一样,f32Minf16Normal是一个常量,其值为0x38ffffff。
要构建法线,必须计算新的指数(第92和93行),正确舍入的10位尾数将移入输出。要构造非正规数,必须将隐式1与输出尾数进行“或”运算,然后将所得尾数偏移与输入指数对应的量。对于法线和非法线,输出尾数的舍入分两步完成。舍入是通过添加一个1的掩码来实现的,该掩码的末尾刚好等于输出的LSB,如图3所示。

图3圆角(一半)。
如果输入的位12置1,则此操作将增加输出尾数;否则,将增加输出尾数。如果输入尾数全为1,则溢出会导致输出指数正确递增。如果我们向此调整的最高有效位再加1,我们将获得小学风格的四舍五入,其中平局决胜数更大。取而代之的是,即使设置了舍入到最接近值,如果设置了10位输出的LSB,则我们有条件地增加输出尾数(图4)。请注意,这些步骤可以按任何顺序执行,也可以以许多不同的方式重新制定。
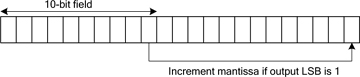
图4舍入到最接近的偶数(一半)。
实际上,开发人员应使用__floattohalf()内在函数将float转换为一半,编译器会将其转换为单个F2F机器指令。提供此示例例程的目的纯粹是为了帮助理解浮点布局和舍入。同样,检查所有INF / NAN和非标准值的特殊情况代码有助于说明IEEE规范的这些功能自诞生以来就一直引起争议:它们使硬件变慢,成本更高,或者由于增加的硅片面积和工程设计而使硬件变慢验证工作。
在本书随附的代码中,清单3中的ConvertFloatToHalf()例程被合并到名为float_to_float16.cu的程序中,该程序针对每个32位浮点值测试其输出。
CUDA包括一个以C运行时库为模型的内置数学库,但有一些小区别:CUDA硬件不包括舍入模式寄存器(取而代之的是,舍入模式是按指令编码的),因此14作为引用当前舍入模式的rint(),始终舍入为最接近值。此外,硬件不会引发浮点异常。异常运算的结果(例如,取负数的平方根)将编码为NaN。
表13列出了数学库函数以及每个函数的最大误差(单位为ulps)。在float上操作的大多数函数的函数名称后均带有“ f”,例如,计算正弦函数的函数如下。双*对于Bessel函数jnf(n,x)和jn(n,x),对于n = 128,最大绝对误差分别为2.2x10 -6
和5x10-12。
**对于Bessel函数ynf(n,x),| x |的误差为?22.5n?;否则,对于n = 128,最大绝对误差为2.2x10 -6。对于yn(n,x),最大绝对误差为5X10 -12。
这些在表13中表示为例如sin [f]。
根据C运行时库的定义,nearint()和rint()函数使用“当前舍入方向”将浮点值舍入到最接近的整数,在CUDA中,该值始终舍入到最接近偶数。在C运行时中,nearingint()和rint()的区别仅在于对INEXACT异常的处理。但是,由于CUDA不会引发浮点异常,因此函数的行为相同。
round()实现小学风格的舍入:对于整数之间中间的浮点值,输入始终从零舍入。NVIDIA建议不要使用此功能,因为它会扩展到八(8)条指令,而不是rint()及其变体的一条指令。trunc()截断或“砍除”浮点值,四舍五入为零。它编译为一条指令。
flost frexpf(float x,int * eptr);
frexpf()将输入分解为范围为[0.5,1.0)的浮点有效数和2的整数指数,使得
x =有效数·2指数
float logbf(float x);
logbf()从x提取指数,并将其作为浮点值返回。它等效于floorf(log2f(x)),但速度更快。如果x为非正规数,则logbf()返回x标准化后的指数。
float ldexpf(float x,int exp);
float scalbnf(float x,int n);
float scanblnf(float x,long n);
ldexpf(),scalbnf()和scalblnf()都通过直接操纵浮点指数来计算x2 n。
modff()将输入分为小数和整数部分。
float modff(float x,float * intpart);
返回值是x的小数部分,具有相同的符号。
restderf(x,y)计算x除以y的浮点余数。返回值为xn * y,其中n为x / y,四舍五入到最接近的整数。如果| x –ny | = 0.5,则选择n为偶数。
float remquof(float x, float y, int *quo);
计算余数并传回积分商x / y的低位,其符号与x / y相同。
n阶贝塞尔函数与微分方程有关
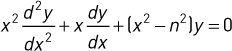
n可以是一个实数,但是对于C运行时而言,它是一个非负整数。
该二阶常微分方程的解结合了第一类和第二类的贝塞尔函数。
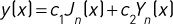
数学运行时函数jn [f]()和yn [f]()分别计算J n(x)和Y n(x)。对于n = 0和n = 1的特殊情况,j0f(),j1f(),y0f()和y1f()计算这些函数。
伽马函数Γ是阶乘函数的扩展,其自变量向下移动1,变为实数。它具有多种定义,其中之一如下。
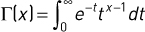
该函数的增长如此之快,返回值损失精度相对较小的输入值,所以该库提供了lgamma函数()函数,该函数返回伽玛函数的自然对数,除了tgamma()(“真伽马”)功能。
标签:保存 必须 开发 纯粹 for unsigned 风格 ide lazy
原文地址:https://www.cnblogs.com/wujianming-110117/p/14233802.html