标签:自适应 组成 耦合 链接 之间 相似度 distance 梯度 一个
论文地址:https://www.aclweb.org/anthology/2020.coling-main.143/
代码地址:未找到
Abstract
本文提出了一种新的基于双层异构图(DHG)的文档级RE模型。特别是,DHG由结构建模层和关系推理层组成Composed of a structure modeling layer followed by a relation reasoning layer.它的主要优点是既能捕获文档的顺序信息和结构信息,又能将它们混合在一起,有利于多跳推理和最终决策。此外,我们还采用了基于图神经网络(GNNs)的消息传播策略来积累DHG上的信息。实验结果表明,该方法在两个广泛使用的数据集上取得了最先进的性能,进一步的分析表明,该模型中的所有模块都是文档级重建所必需的。
1 Introduction

在本文中,我们提出了一个新的文档级重模型,它建立了一个双层异构图Dual-tier Heterogeneous Graph(DHG)来连续地建模文档结构并支持关系推理。具体来说,DHG的第一层是结构建模层(structure modeling layer,SML),它负责从顺序、语法和层次三个方面对文档的内在结构进行综合编码,从而将每个文档转换为一个以节点为单词和句子,边为其间关系的图。在第二层中,基于前一层的语义丰富表示,引入关系推理层relation reasoning layer(RRL)在不同实体间传递关系信息,实现多跳关系推理。对于图神经网络(GNNs),我们假设在DHG中通过沿边传播节点信息可以捕获用于识别关系事实的期望信号。再以图1为例,通过SML中的句子节点,将由和原因引起的关键字信息传播到单词节点,并逐渐累积到RRL中的实体节点,最终决策。据我们所知,这是第一次尝试在文档级NLP任务中通过双层异构结构将文档建模和多跳推理分离开来。
我们在两个广泛使用的公共文档级RE数据集上进行了广泛的实验。结果表明,该模型达到了最先进的性能。通过详细的烧蚀研究,我们进一步证明了我们的方法中的所有组件对于文档级RE是必不可少的。此外,我们还证明,将预先训练的语言模型(例如,BERT(Devlin et al.,2019))与DHG结合可以带来进一步的改进。
2 Preliminaries 准备工作
2.1 Problem Statement
文档${\cal D}=\{ {\cal S_i}\}_{i=1}^{n_s}$,entity set ${\cal V}=\{ {\cal E_i}\}_{i=1}^{n_e}$,where ${\cal S}_i=\{ {w_j}\}_{j=1}^{n_w^i}$denotes the i-th sentence with $n^i_w$ words and ${\cal E}_i=\{ {m_j}\}_{j=1}^{n_m^i}$ is the i-th entity with $n_m^i$ mentity mentions.最终目标是预测每个实体对之间的所有句内和句间关系${\cal R}^{‘}\in {\cal R}= \{ r_i\} _{i=1}^{n_r}$
2.2 Message Propagation Strategy消息传播策略
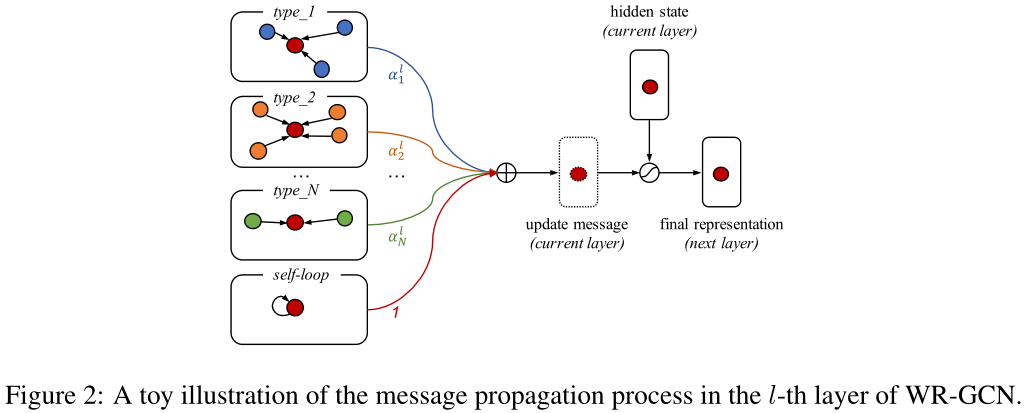
本文遵循关系图卷积网络(R-GCN)的基本传播思想(Schlichtkrull et al., 2018),它可以处理高度相关的数据特性,并充分利用不同的边缘类型。Formally, at l-th layer, given the hidden state $h_i^l∈ R^d$ of node $i$ and its neighbors $\cal N_i$ iwith corresponding edge types $\cal T$ , R-GCN propagates message across different neighboring nodes and generates transformed representation in the next layer for node $i$ via:
$h_i^{l+1} = \sigma(\sum_{t\in\mathcal{T}}\sum_{j\in\mathcal{N_i^t}}\frac{1}{|\mathcal{N}_i^t|}W_t^lh_j^l + W_s^lh_i^l)$
这个式子相当于把图中的所有边分类,前面的$\sum\sum$是对于每一类边有不同的$W^l_t$ ,后面的$W_s^l$指自环。作者在这里又给每个不同类的边加了一个权重:
$h_i^{l+1} = \sigma(\sum_{t\in\mathcal{T}}\sum_{j\in\mathcal{N_i^t}}\frac{\alpha_t^l}{|\mathcal{N}_i^t|}W_t^lh_j^l + W_s^lh_i^l) = \sigma(u_i^l)$
where $\alpha^l_t$ is a trainable parameter to model the interaction strength between two adjacent nodes with type $t$ in the l-th layer.
此外,研究还表明,如果层数较大,GNNs通常会遇到过度平滑问题(Kipf和Welling,2017),使得不同的节点具有相似的表示,并失去节点之间的区别。为了解决这个问题,我们添加了一个选通机制(Gilmer et al.,2017)来控制将更新消息传播到下一层的程度【加入了每层的残差链接,由一个 gate 控制:】:
$g_i^l = \text{sigmoid}(\mathcal{F_g}([u_i^l;h_i^l]))$
$h^{l+1}_i = g_i^l\odot\sigma(u_i^l) + (1-g_i^l)\odot h_i^l$
a linear transformation $\cal F_g$,为了简洁起见,在本文的剩余部分,我们将消息传播过程简化为加权关系图神经网络(WR-GCN)。图2显示了使用WR-GCN的一个层的工作流程【其中$\cal F_g$是一个 reshape 的 linear transformation,gate 感觉就是在算这一层输入输出每一维的相似度(?)】
3 Methodology
在本节中,我们将介绍所提出的双层异构图(DHG)和文档级重模型。图3显示了整个系统图。具体来说,RE模型可分为五层:(1)输入层负责将输入词转换为密集的矢量化表示;(2)上下文编码层可以是任何公共序列编码器,为每个词生成上下文化表示;(3) 结构建模层Structure Modeling Layer 是DHG的第一层异构图,旨在对纯文本固有的结构信息进行建模,包括邻接关系、从属关系affiliation和句法依赖关系;(4)关系推理层Relation Reasoning Layer主要捕获文档中实体对之间的多跳关系,输出层将关系预测看作一个多标签分类问题,预测每个实体对可能存在的关系。
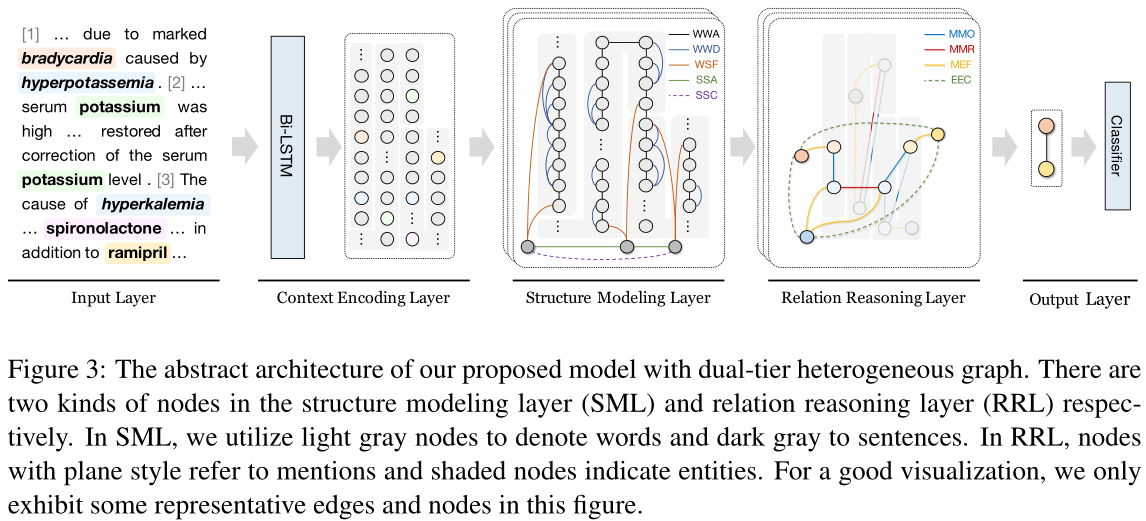
图3:我们提出的具有双层异构图的模型的抽象架构。结构建模层(SML)和关系推理层(RRL)分别有两种节点。在SML中,我们使用浅灰色节点表示单词,使用深灰色节点表示句子。在RRL中,具有平面样式的节点表示提及,阴影节点表示实体。为了获得良好的可视化效果,我们只展示了该图中一些具有代表性的边和节点。
3.1 Input Layer
for each word $w_i$, we concatenate its word embedding $w_i$, type embedding $t_i$ and coreference embedding $c_i$ to build input features $x_i= [w_i;t_i;c_i] ∈ R^{d_x}$, where [·;·] denotes concatenation operator and $d_x= d_w+ d_t+ d_c$.
3.2 Context Encoding Layer
We regard the whole document as a long sequence with n words,BiLSTM:
$h_i=\cal F([\overrightarrow{LSTM}(x_i);\overleftarrow{LSTM}(x_i)])$
where $h_i∈ R^{d_h}$ and $\cal F : R^{2×d_h}→ R^{d_h}$ refers to a linear function,As a result, we use $H_W= {h_1,h_2, . . . ,h_n}$ to denote all word representations generated for input sequence.
3.3 Structure Modeling Layer
在DHG的第一层,我们将文档中的每个单词和句子作为一个节点。这很直观,因为一个文档是由许多句子组成的,而一个句子是由许多单词组成的。当然,我们可以用以下五种类型的边来模拟文档的固有结构:
word 和 sentence 作为 node,包含五类边:
在结构建模层(SML)中,我们分别解析每个句子的依赖树,并直接利用上下文编码层的输出作为词节点的初始特征。max-pooling操作应用于句子中的所有单词节点,以获得句子节点表示:$s=max\{ h_j\}^{n_w}_{j=1}$【一个单词的h代表一句话?】。之后,第2.2节中介绍的消息传递策略用于更新单词和句子节点的表示:
$(\overline{H}_W,\overline{H}_S)=WR-GCN_{SML}(H_W,H_S)$
where $H_S= \{s_1, . . . ,s_{N_s}\}$ is the set of sentence node representations,For each word node, we concatenate its features before and after $WR-GCN_{SML}$ as its output representation:$\hat{h}_i=\cal F([h_i;\overline{h}_i])$,这种快捷shortcut连接机制能够同时组合顺序和结构特征,并为下一推理步骤提供了坚实的基础。
3.4 Relation Reasoning Layer
DHG的第二层用于基于图的推理,它首先利用和传播实体间的关系信息,然后将它们归纳为相应的实体。受Entity-GCN成功的启发(De Cao et al.,2019),我们将提及和实体视为节点,这张图由 mention(word 平均) 和 entity(mention 平均) 构成,包含四类边:
Similar to SML, WR-GCN is also employed to propagate messages among nodes:
$(\overline{H}_E,\overline{H}_M)=WR-GCN_{RRL}(H_E,H_M)$
其中,$H_M$和$H_E$分别表示提及节点和实体节点的集合。在L次消息传递之后,所有节点都将有它们的最终表示。
3.5 Output Layer
为了确定两个实体之间的语义关系,我们将关系预测视为一个多标签分类问题。特别是对于$(e_i,e_j)$,我们将这些实体特征与相对距离嵌入连接起来,并使用双线性函数来计算每个关系的概率:
$\hat{e}_i=[\overline{e}_i;d_{ij}]$ $\hat{e}_j=[\overline{e}_j;d_{ji}]$
$y=sigmoid(\hat{e}_i^TW\hat{e}_j+b)$
where $d_{ij}∈ R^{d_d}$ and $d_{ji}∈ R^{d_d}$ are relative distance embeddings between the first mentions of two entities in the document, $W ∈ R^{d×n_r×d}$ is a learned bi-affine tensor, $b ∈ R^d$ is the bias vector (in which $d = d_h+d_d$) and $y ∈ R^{n_r}$ denotes the prediction for all relations. Finally, the loss function is defined as the sum of binary cross-entropy between gold annotation and its predicted probability for each fact.
4 Experiments
Dataset:CDR,GDA
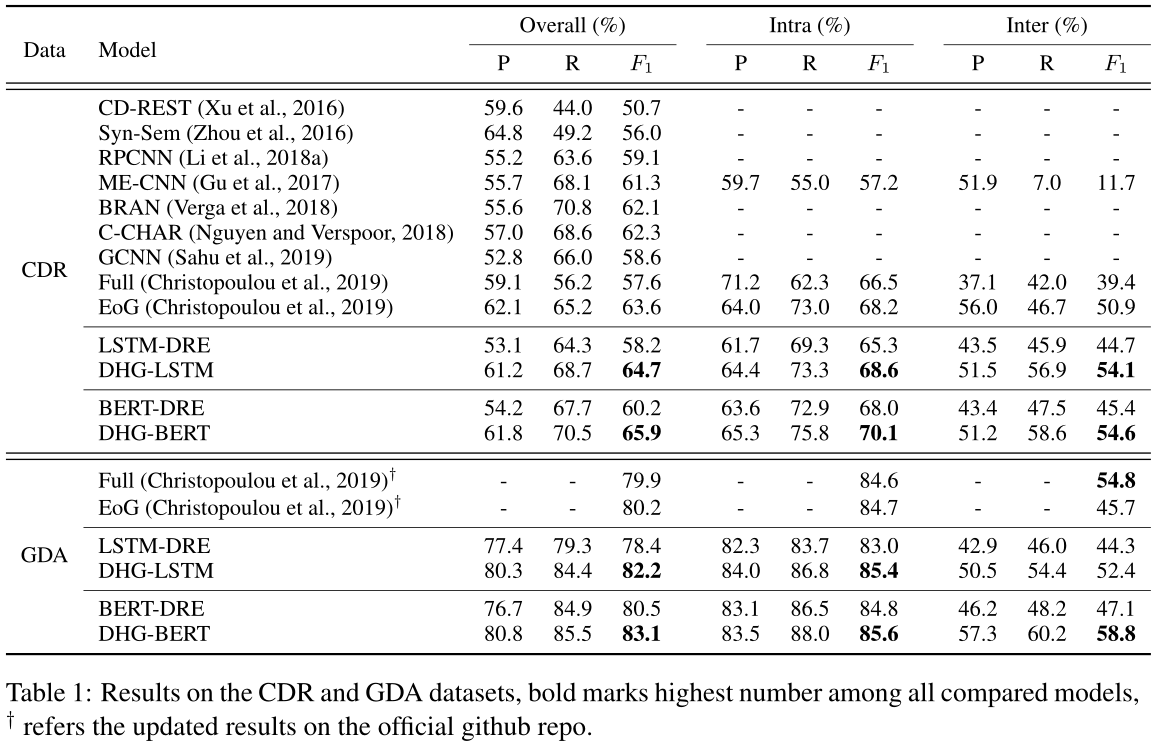
表1报告了我们提出的模型在两个数据集上与其他基线方法的比较结果。可以观察到,使用DHG的模型显著优于所有其他方法,并且DHG-BERT在所有数据集上都达到了最先进的F1分数。与CDR数据集上最新的基于图的方法EoG和GCNN相比,DHG-LSTM的F1得分分别提高了1.1%和6.1%。我们将性能提升归因于两种设计选择:(1)文档建模和多跳推理的分解,因为它使推理过程受益于序列和结构信息;(2) 我们的消息传播策略中的加权机制,因为它从异类相邻节点收集自适应数量的信息。
此外,在CDR数据集上,DHG-LSTM相对于LSTM-DRE提高了6.5%的相对幅度,即使BERT已经提供了强大的学习丰富语义特征的能力,DHG-BERT仍然取得了一致的改进。它直接证明了在文档级RE中引入结构信息和推理机制的必要性,并且由于其松散耦合的体系结构,多种基本编码器可以很好地集成到我们的模型中。我们认为BERT-DRE的性能提升主要是因为DHG充分利用了BERT的语义信息,而图结构弥补了BERT在捕捉长程句法结构方面的不足,这与最近一些研究的结论是一致的(Clark et al.,2019;Zhang et al.,2020b)。
同时,另一个现象是基于DHG的模型在句内和句间情境下的表现都优于所有的基线模型,尤其是句间情境,这说明DHG的大部分来源于句间关系事实。特别是,当我们将DHG-LSTM与其基线LSTM-DRE进行比较时,可以发现句间对的性能有了惊人的改进,而且句内对也从组织良好的文档级信息中获益匪浅。
4.5 Effect of Model Architectures
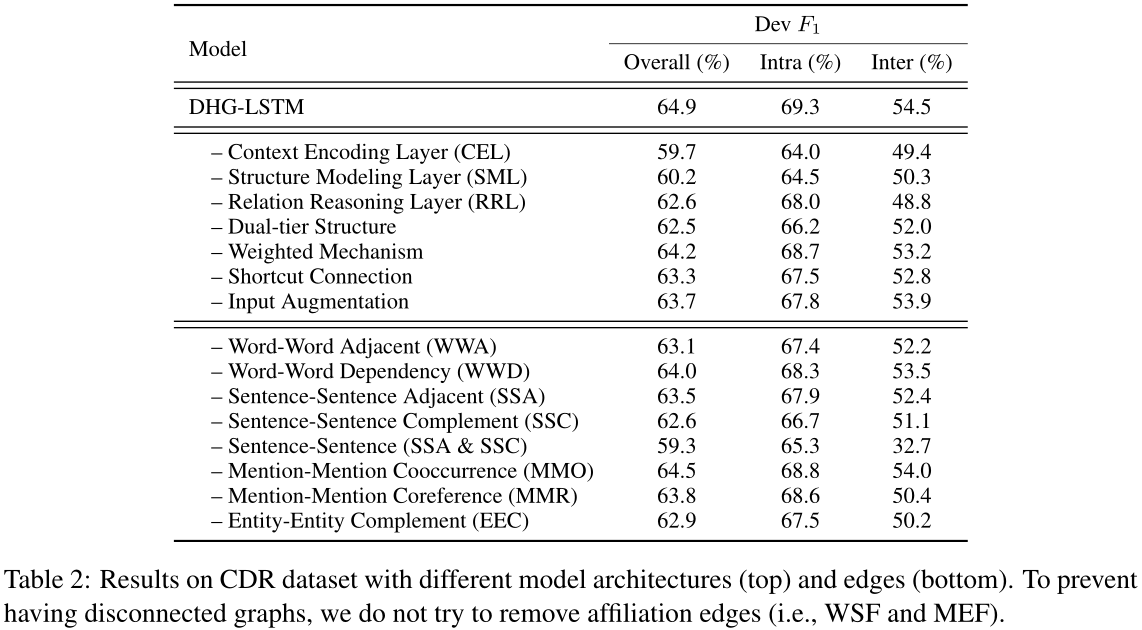
为了研究我们模型中不同模块的贡献,我们对CDR数据集进行了一项烧蚀研究(见表2的顶部)。从这些烧蚀中可以观察到:(1)CEL、SML、RRL是必不可少的层,它们分别使F1成绩提高5.2%、4.7%和2.3%,说明它们在整个系统中起着不同的决定性作用。(2) 如果没有双层结构,性能也会受到2.4%F1的严重损害。有力的证据表明,将这些异构节点分层而不是杂乱无章地混合在一起是非常关键的。(3) 加权机制对F1的贡献率约为0.7%,这表明有必要让模型知道互补边等边类型的权重应该比其他边小。(4) SML中的快捷连接操作非常关键,因为如果去掉F1,F1会显著下降1.6%,这可以解释为快捷连接提供了一种将序列信息与结构信息相结合的有效方法,解决了深层神经网络中的消失梯度问题。(5) 去除输入增广对最终结果的影响为1.2%F1,说明多通道信息的参与也有助于文档级重建模提高性能。
4.6 Effect of Different Edges
在这个实验中,我们研究了我们的DHG中不同边缘的影响。为此,我们单独烧蚀每种类型的边缘,并在表2底部报告结果。首先要注意的是,当WWA或SSA被删除时,F1的分数会显著下降,这可以解释为它们保持了文档的顺序结构,可以通过这两条边恢复原始文档。其次,WWD带来了显著的改进,证明了在文档级RE中利用句法依赖的有效性。第三,删除MMO对性能的影响较小,因为大部分句内关系可以通过上下文编码层来识别,而SML中的一个词-句-词链可以替代其部分角色。与此相反,MMR的丢弃显著降低了模型的性能,因为MMR使模型能够感知长期的和句间的提及指代关系。最后但同样重要的是,SSC和EEC有助于句子间关系的提取,同时也起到了使信息在图上快速传播的必要作用。不出意料的是,句与句之间连接的去除会导致性能的急剧下降,尤其是句间连接。总的来说,每个边缘都有自己的职责。各种边以相互促进的方式工作,这再次证实了我们的动机,即显式地捕获文档的内在结构对于文档级别的重新设计是必不可少的。
4.7 Effect of Model Depth
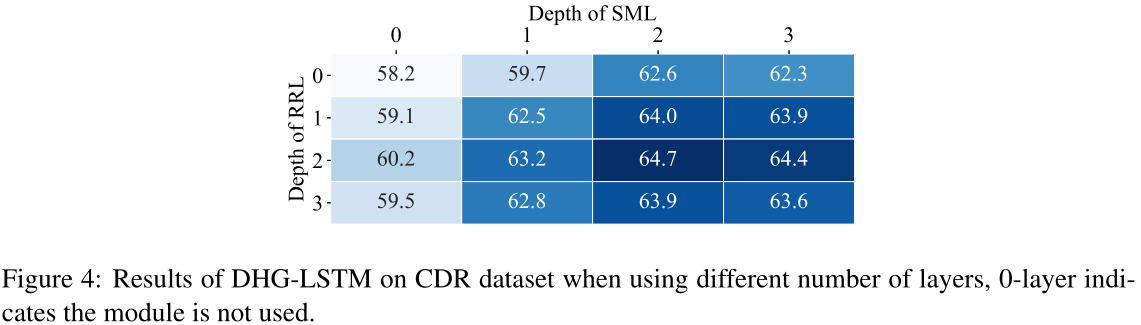
在本节中,我们将探讨模型深度(层数)的影响。对于DHG-LSTM模型中的SML和RRL,我们将它们的层数从0变为3。如图4所示,当SML和RRL的层都为2时,模型达到了最佳性能。在这种情况下,SML中的词节点通过句子-词链感知所有句子节点的信息,RRL支持二跳推理。因此,可以完全聚合用于检测关系的关键信息。然而,浅层模型和深层模型都不能很好地工作。一个可能的原因是仅仅从最近的邻居节点收集信息不足以识别两个实体之间的关系。相反,当层数为3时,同一个图中的任意两个节点都是可访问的,这可能会引入冗余信息并阻碍推理。
6 Conclusion
本文提出了一种新的基于GNNs的文档级RE方法,利用双层异构图DHG实现文档的有序建模和多跳推理。在两个广泛使用的文档级RE数据集上的实验结果表明,该模型达到了最先进的性能。我们相信我们的方法足够健壮,可以很容易地适应其他文档级别的NLP任务,而无需手动调整域。在未来,我们将研究可解释的GNNs在文档级RE中的应用,并在文档级NLP任务中将预训练技术与所提出的双层异构结构相结合。
参考:
论文笔记:https://ivenwang.com/2021/01/04/dhg/
【论文阅读】Document-level Relation Extraction with Dual-tier Heterogeneous Graph[COLING2020]
标签:自适应 组成 耦合 链接 之间 相似度 distance 梯度 一个
原文地址:https://www.cnblogs.com/Harukaze/p/14388265.html