标签:存在 字符编码 可见 last ast 变量类型 string width 无法
目录
1.背景.
2.编码的理解
3.编码之间的相互转化
4. str类型说明
5. 可以使用的编码类型
6.参考文章
Python中与其他程序进行交互时,如果存在字符串交互,特别是字符串中含有中文时,需要注意字符的格式,需要保持两边一致。
笔者在开发中遇到一个python 调用Labview编译的dll函数,需要输入一个字符串路径。当路径中含有中文时,由于两边编码不一致,会导致报错。
1. python 中写代码时,一般通过在一开始使用 # -*- coding: utf-8 -*- 或者其他告诉编译器当前代码默认的编码是什么,这里就是utf-8格式,现在比较通用。
当string_a = ‘Bing,你好’
Type(string_a) = str
可见当赋值一个字符串时,python 默认是str类型。
通过encode(‘utf-8’),decode(‘utf-8’)可以进行格式的编码或者解码。编码后的变量类型是bytes类型,完整的说应该是 按照utf-8格式编码的bytes类型。
我的中文环境的Labview中默认编码格式是gbk格式,所以我用python将字符串送入labview编译的dll中时,需要 先将 字符串编码成gbk格式,比如 string_a.encode(‘gbk’),当收到labview编译的dll函数中传出来的字符串时,需要先将收到的 string_b_out.decode(‘gbk’) 这样就能显示中文,而不是乱码了。
在python(笔者当前为3.7版本)中,为编码的字符串类型为str,无论编码成 ‘utf-8’还是‘gbk’,类型都会从str类型变为bytes类型。
下面我们结合代码理解:
s=‘Bing-中国-!‘
print(‘type(s)‘,type(s))
打印如下内容----------------
type(s) <class ‘str‘>
打印内容结束----------------
a=s.encode(‘utf-8‘)
b=s.encode(‘gb2312‘)
c=s.encode(‘gb18030‘)
d=s.encode(‘gbk‘)
print("a=s.encode(‘utf-8‘), a=",a)
print("b=s.encode(‘gb2312‘),b=",b)
print("c=s.encode(‘gb18030‘),c=",c)
print("d=s.encode(‘gbk‘),d=",d)
打印如下内容----------------
a=s.encode(‘utf-8‘), a= b‘Bing-\xe4\xb8\xad\xe5\x9b\xbd-\xef\xbc\x81‘
b=s.encode(‘gb2312‘),b= b‘Bing-\xd6\xd0\xb9\xfa-\xa3\xa1‘
c=s.encode(‘gb18030‘),c= b‘Bing-\xd6\xd0\xb9\xfa-\xa3\xa1‘
d=s.encode(‘gbk‘),d= b‘Bing-\xd6\xd0\xb9\xfa-\xa3\xa1‘
打印内容结束----------------
print(‘type(a)‘,type(a))
print(‘type(b)‘,type(b))
print(‘type(c)‘,type(c))
print(‘type(d)‘,type(d))
打印如下内容----------------
type(a) <class ‘bytes‘>
type(b) <class ‘bytes‘>
type(c) <class ‘bytes‘>
type(d) <class ‘bytes‘>
打印内容结束----------------
a=a.decode(‘utf-8‘)
b=b.decode(‘gb2312‘)
c=c.decode(‘gb18030‘)
d=d.decode(‘gbk‘)
print("a=a.decode(‘utf-8‘), a=",a)
print("b=b.decode(‘gb2312‘),b=",b)
print("c=c.decode(‘gb18030‘),c=",c)
print("d=d.decode(‘gbk‘),d=",d)
打印如下内容----------------
a=a.decode(‘utf-8‘), a= Bing-中国-!
b=b.decode(‘gb2312‘),b= Bing-中国-!
c=c.decode(‘gb18030‘),c= Bing-中国-!
d=d.decode(‘gbk‘),d= Bing-中国-!
打印内容结束----------------
可见原来的内容又回来了,此时a,b,c,d的类型为str。
另一种情况,当我编码了utf-8后,是否可以从utf-8直接编码或者解码成 gbk格式
答案是不可以,必须先解码成 str类型,再重新编码为gbk编码的bytes类型。
所以其实编码解码之间还是有方向性的。
当变量类型为 str类型时,智能编码,使用encode(‘编码格式’)方法;当bytes类型时,按道理只用解码decode(‘编码格式’) 才不会出错。
#%% 当编码了utf-8后需要转化为gbk,应该先解码,再重新编码成gbk,即不同编码格式之间不能直接转化。
上图:
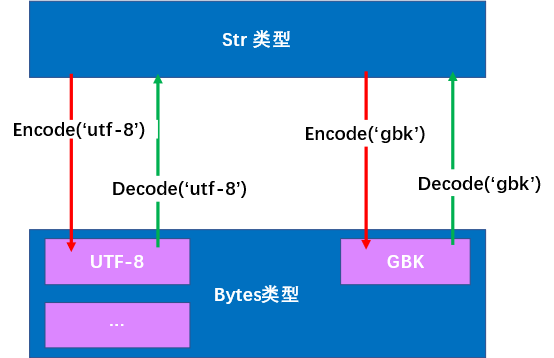
GBK需要转化为utf-8的流程为:
1. 首先通过decode(‘gbk’)转化为 str 类型
2. 再通过encode(‘utf-8’)转化为编码为utf-8的bytes类型。
s=‘Bing-中国-!‘
print(‘type(s)‘,type(s))
a=s.encode(‘utf-8‘)
print(‘type(a)‘,type(a))
#--------------------------------------
b=a.encode(‘gb2312‘) # 会报错如下内容
# 会报错如下内容
# type(s) <class ‘str‘>
# type(a) <class ‘bytes‘>
# Traceback (most recent call last):
# File "D:\Python\decodeandencode.py", line 60, in <module>
# b=a.encode(‘gb2312‘)
# AttributeError: ‘bytes‘ object has no attribute ‘encode‘
#-----------------------------------
b=a.decode(‘gb2312‘) # 也会报错,当编码无法使用正确识别时。
# 会报错如下内容
# type(s) <class ‘str‘>
# type(a) <class ‘bytes‘>
# Traceback (most recent call last):
# File "D:\Python\decodeandencode.py", line 71, in <module>
# b=a.decode(‘gb2312‘)
# UnicodeDecodeError: ‘gb2312‘ codec can‘t decode byte 0xad in position 7: illegal multibyte sequence
在网上看到有人说str类型在python中其实是按照unicode来保存的。但是会显性成str我们看到的字符。
除了utf-8和gbk以外,还可以编码成很多类型。在python的帮助文档中摘取一小部分:
|
Codec |
Aliases |
Languages |
|
euc_kr |
euckr, korean, ksc5601, ks_c- |
Korean |
|
gb2312 |
chinese, csiso58gb231280, euc |
Simplified Chinese |
|
gbk |
936, cp936, ms936 |
Unified Chinese |
|
gb18030 |
gb18030-2000 |
Unified Chinese |
|
hz |
hzgb, hz-gb, hz-gb-2312 |
Simplified Chinese |
|
iso2022_jp |
csiso2022jp, iso2022jp, iso-2022- |
Japanese |
|
iso2022_jp_1 |
iso2022jp-1, iso-2022-jp-1 |
Japanese |
|
iso2022_jp_2 |
iso2022jp-2, iso-2022-jp-2 |
Japanese, Korean, Simplified Chi |
字符编码之间的转换 utf-8 , gbk等,(解决中文字符串乱码)
标签:存在 字符编码 可见 last ast 变量类型 string width 无法
原文地址:https://www.cnblogs.com/Nicoooolas/p/14419438.html