标签:loading 设置 服务 trie serve www 并且 数字 工作原理
git clone https://github.com/RedisBloom/RedisBloom.git
cd redisbloom
make
-----
以上命令会生成redisbloom.so文件
# MODULE LOAD /redisbloom.so (编译出的so路径)
查看已加载的插件module list
1) 1) "name" 插件名字
2) "bf" 模块名
3) "ver" 模块版本号
4) (integer) 999999
# 动态执行模块卸载
# MODULE UNLOAD 模块名
# Assuming you have a redis build from the unstable branch:
./redis-server --loadmodule ./redisbloom.so (编译出的so路径)
redis-server --loadmodule /path/to/redisbloom.so INITIAL_SIZE 400 ERROR_RATE 0.004
The default error rate is 0.01 and the default initial capacity is 100 .
Format:BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
eg:bf.reserve key3 0.1 5 NONSCALING
OK
127.0.0.1:6379> bf.add key3 0
(integer) 1
127.0.0.1:6379> bf.add key3 1
(integer) 1
127.0.0.1:6379> bf.add key3 2
(integer) 1
127.0.0.1:6379> bf.add key3 3
(integer) 1
127.0.0.1:6379> bf.add key3 4
(integer) 1
127.0.0.1:6379> bf.add key3 5
(error) ERR non scaling filter is full
容量设置为5,且配置为不可以扩容,添加第6个元素时即提示BloomFilter is full。
Parameters:
BF.ADD {key} {item}
eg:BF.ADD key0 v0
(integer) 1
功能:向key指定的Bloom中添加一个元素
BF.MADD {key} {item ...}
eg:BF.ADD key0 v1 v2
1) (integer) 1
2) (integer) 1
功能:向key指定的Bloom中添加多个元素
BF.INSERT {key} [CAPACITY {cap}] [ERROR {error}] [EXPANSION {expansion}] [NOCREATE] [NONSCALING] ITEMS {item ...}
eg: bf.insert bfinKey0 CAPACITY 5 ERROR 0.1 EXPANSION 2 NONSCALING ITEMS item1 item2
1) (integer) 1
2) (integer) 1
功能:向key指定的Bloom中添加多个元素,添加时可以指定大小和错误率,且可以控制在Bloom不存在的时候是否自动创建
参数说明
BF.EXISTS {key} {item}
eg:BF.EXISTS key0 v1
(integer) 1
功能:检查一个元素是否存在于BloomFilter
BF.MEXISTS {key} {item}
eg:BF.MEXISTS key0 v1 v2
1) (integer) 1
2) (integer) 1
功能:批量检查多个元素是否存在于BloomFilter
BF.SCANDUMP {key} {iter}
eg:BF.SCANDUMP key0 0
1) (integer) 1
2) "\x04\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x05\x00\x00\x00\x02\x00\x00\x00\x90\x00\x00\x00\x00\x00\x00\x00\x80\x04\x00\x00\x00\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00{\x14\xaeG\xe1zt?\xe9\x86/\xb25\x0e&@\b\x00\x00\x00d\x00\x00\x00\x00\x00\x00\x00\x00"
功能:对Bloom进行增量持久化操作(增量保存)
BF.LOADCHUNK {key} {iter} {data}
功能:加载SCANDUMP持久化的Bloom数据
BF.INFO {key}
eg:bf.info key1
1) Capacity
2) (integer) 7
3) Size
4) (integer) 416
5) Number of filters
6) (integer) 3
7) Number of items inserted
8) (integer) 5
9) Expansion rate
10) (integer) 2
功能:查询key指定的Bloom的信息
返回值:
BF.DEBUG {key}
eg:bf.debug key1
1) "size:5"
2) "bytes:8 bits:64 hashes:5 hashwidth:64 capacity:1 size:1 ratio:0.05"
3) "bytes:8 bits:64 hashes:6 hashwidth:64 capacity:2 size:2 ratio:0.025"
4) "bytes:8 bits:64 hashes:7 hashwidth:64 capacity:4 size:2 ratio:0.0125"
功能:查看BloomFilter的内部详细信息(如每层的元素个数、错误率等)
返回值:

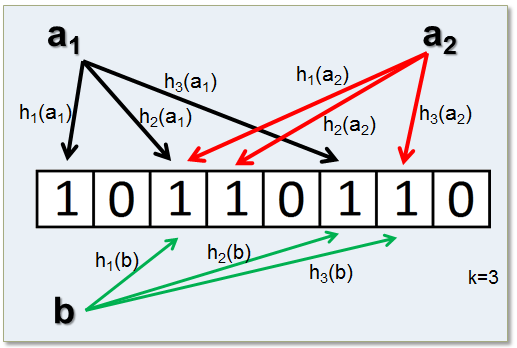
A Bloom filter is an array of many bits. When an element is ‘added’ to a bloom filter, the element is hashed. Then bit[hashval % nbits] is set to 1

In order to reduce the risk of collisions, an entry may use more than one bit
int bloom_init(struct bloom *bloom, uint64_t entries, double error, unsigned options) {
// ...
bloom->bpe = calc_bpe(error);
bloom->hashes = (int)ceil(0.693147180559945 * bloom->bpe); // ln(2)
// ...
}
static double calc_bpe(double error) {
static const double denom = 0.480453013918201; // ln(2)^2
double num = log(error);
double bpe = -(num / denom);
if (bpe < 0) {
bpe = -bpe;
}
return bpe;
}
// Math.ceil() 函数返回大于或等于一个给定数字的最小整数
// ln(2) ≈ 0.693147180559945
// ln(2)^2 ≈ 0.480453013918201
// log(error):以10为底的对数函数
即RedisBloom计算hash函数的个数k = - log(error) / ( (ln2) ^2) * ln(2) )
符合bloomfilter的推倒公式:[布隆过滤器 (Bloom Filter) 详解](https://www.cnblogs.com/allensun/archive/2011/02/16/1956532.html)
可以通过命令bf.reserve和bf.debug创建和查看redis bloom中最佳hash函数数量与错误率的关系如下:
| 错误率{error_rate} | hash函数的最佳数量 |
|---|---|
| 0.1 | 5 |
| 0.01 | 8 |
| 0.001 | 11 |
| 0.0001 | 15 |
| 0.00001 | 18 |
| 0.000001 | 21 |
| 0.0000001 | 25 |
eg:
bf.reserve bf0.1-2 0.1 100
bf.debug bf0.1-2
1) "size:0"
2) "bytes:80 bits:640 hashes:5 hashwidth:64 capacity:100 size:0 ratio:0.05"
int bloom_init(struct bloom *bloom, uint64_t entries, double error, unsigned options) {
// ...
bloom->bpe = calc_bpe(error);
bits = bloom->bits = (uint64_t)(entries * bloom->bpe);
// ...
}
即:bits = (entries * ln(error)) / ln(2)^2
| 错误率{error_rate} | 元素数量{capacity} | 占用内存(单位M) |
|---|---|---|
| 0.01 | 10万 | 0.13146M (bytes:137848) |
| 0.01 | 1百万 | 1.3146M (bytes:137847) |
| 0.01 | 1千万 | 13.146M (bytes:13784696) |
| 0.001 | 10万 | 0.18859M (bytes:197760) |
| 0.001 | 1百万 | 1.8859M(bytes:1977536) |
| 0.001 | 1千万 | 18.859M(bytes:19775360) |
| 0.0001 | 10万 | 2.4572M (bytes:2576608) |
| 0.0001 | 1百万 | 24.572M (bytes:25766016) |
| 0.0001 | 1千万 | 245.72M (bytes:257660152) |
RedisBloom官方默认的error_rate是 0.01,默认的capacity是 100
1、创建一个容量为5的RedisBloom bf.reserve keyExp 0.1 5
2、添加5个bf.madd keyExp 1 2 3 4 5
bf.debug keyExp
1) "size:5"
2) "bytes:8 bits:64 hashes:5 hashwidth:64 capacity:5 size:5 ratio:0.05"
3、重复添加“1” bf.madd keyExp 1
查看RedisBloom状态,未发生扩容
bf.debug keyExp
1) "size:5"
2) "bytes:8 bits:64 hashes:5 hashwidth:64 capacity:5 size:5 ratio:0.05"
4、添加第六6key bf.madd keyExp 6
查看RedisBloom状态,发现发生扩容了
bf.debug keyExp
1) "size:6"
2) "bytes:8 bits:64 hashes:5 hashwidth:64 capacity:5 size:5 ratio:0.05"
3) "bytes:16 bits:128 hashes:6 hashwidth:64 capacity:10 size:1 ratio:0.025"
1.插入m个元素,计算实际插入BloomFilter的元素数量;
2.如果实际插入元素数量 > BloomFilter的容量,则触发扩容;
3.扩容的倍数为BloomFilter初始化时设置的expansion(默认2);
备注:
Redis-benchmark是Redis官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能,Redis-benchmark参数的使用说明如下所示。
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-s <socket> Server socket (overrides host and port)
-a <password> Password for Redis Auth
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 2)
--dbnum <db> SELECT the specified db number (default 0)
-k <boolean> 1=keep alive 0=reconnect (default 1)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD
Using this option the benchmark will expand the string __rand_int__
inside an argument with a 12 digits number in the specified range
from 0 to keyspacelen-1. The substitution changes every time a command
is executed. Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
-e If server replies with errors, show them on stdout.
(no more than 1 error per second is displayed)
-q Quiet. Just show query/sec values
--csv Output in CSV format
-l Loop. Run the tests forever
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-I Idle mode. Just open N idle connections and wait.
Bloom Filter Datatype for Redis
标签:loading 设置 服务 trie serve www 并且 数字 工作原理
原文地址:https://www.cnblogs.com/yangsanchao/p/14695008.html