标签:pac 计数器 简单 main mask 一致性 csdn 能耗 二分
由于通过提升cpu频率提升性能的道路遇到了能耗墙,进一步提升频率可能会造成CPU温度过高,影响稳定性。为了进一步提升cpu性能,多核CPU逐渐发展起来。然而多核也面临着诸多问题,包括正确性和可扩展性。下面我们就谈谈多核中的缓存一致性。
主流的多核处理器均采用共享内存,但访问内存耗时较长,因此在CPU和内存之间设立了高速缓存,一个典型的高速缓存架构如图所示,分为L1、L2、L3 Cache。告诉缓存以缓存行 (Cacheline) 作为最小操作粒度,大小一般为64字节。
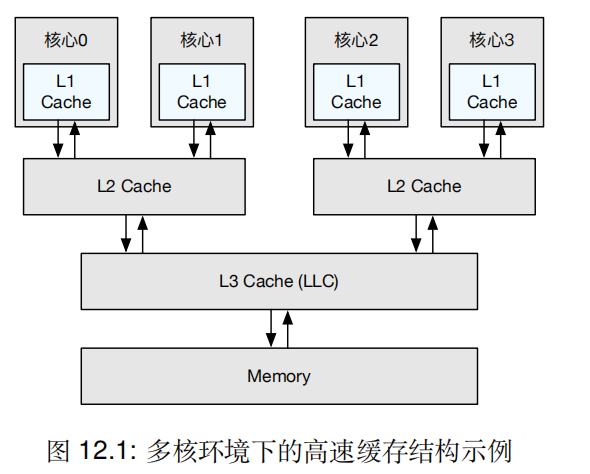
在这种架构中,不同核心访问时延会依据缓存行所在位置有所差别。如核心0访问本地的L2 cache会远快于访问另一个L2 cache。这种缓存架构被称为 非一致性缓存访问。除了非一致性缓存访问以外,更重要的问题就是缓存一致性问题。
下面举例说明对单一缓冲行高频修改带来的性能断崖,在多个核心中执行一个线程,竞争一个全局的互斥锁,并更新一个全局计数器。如图所示,当核数量提升到一定数量时,性能会出现断崖式下跌。
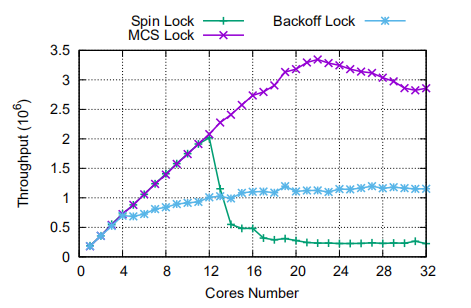
由于自旋锁是通过修改全局单一变量 *lock 来获取和释放锁,因此多核对该缓存行进行高频修改时,缓存行的状态与拥有者也不断改变,最终消耗大量时间在缓存一致性协议上,导致互斥锁无法快速有效地在不同的核心之间传递。
通过 Backoff Lock 或者 MCS 锁可以一定程度解决自旋锁的问题,在此我们不详述,可以参阅[1]获取更多内容。
伪共享的问题可以举一个简单的例子,如果多个核的任务是自增对同一数组的不同位置数据,理论上应该是互不干扰的。但如果这些数据在同一个缓存行,就会导致一次只有一个核可以写数据,造成伪共享。
可以通过一段代码来检验伪共享造成的性能损失:
#include<thread>
#include <algorithm> // std::for_each
#include<vector>
#include <functional>
using namespace std;
bool SetCPUaffinity(int param){
cpu_set_t mask; // CPU核的集合
CPU_ZERO(&mask); // 置空
CPU_SET(param,&mask); // 设置亲和力值,第一个参数为零的时候默认为调用线程
sched_setaffinity(0, sizeof(mask), &mask); // 设置线程CPU亲和力
}
int num0;
int num1;
void thread0(int index){
SetCPUaffinity(index);
int count = 100000000; // 1亿
while(count--){
num0++;
}
return;
}
void thread1(int index){
SetCPUaffinity(index);
int count = 100000000;
while(count--){
num1++;
}
return;
}
int main(){
thread proc0(thread0, 0);
thread proc1(thread1, 1);
proc0.join();
proc1.join();
return 0;
}
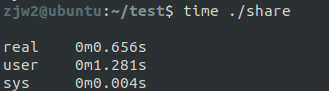
这段代码功能很简单,就是把用两个线程把 num0 和 num1 增加到100000000,为了使得两个线程跑在不同的核上,我们需要设置CPU亲和性。通过time命令可以获取运行时间,可以看到实际需要跑0.65s:
修改代码,让两个线程串行执行,即把main()函数修改如下:
int main(){
thread proc0(thread0, 0);
proc0.join();
thread proc1(thread1, 1);
proc1.join();
return 0;
}
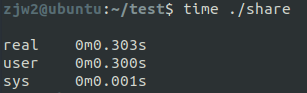
可以看到时间直接减少为原来的二分之一。本应是并行的程序却比串行的程序花费了两倍的时间,这些多的时间都消耗在缓存一致性和伪共享上。
将num0和num1放到不同的缓存行,可以通过如下方式:
int num0;
int num[1000];
int num1;
再运行并行代码,运行时间如图所示,可以看到只需要0.18s,接近串行的二分之一时间,和预料中一致。
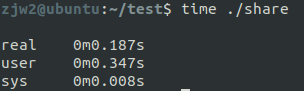
因此伪共享不仅不会提升系统性能,反而会因为竞争同一缓存行造成性能损失。
标签:pac 计数器 简单 main mask 一致性 csdn 能耗 二分
原文地址:https://www.cnblogs.com/zhujiwei/p/14726848.html