标签:转换 ber marked war public 对象 record 没有 upm
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于KAFKA的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
本来是打算写到消费者模块的时候再详细看一下和写一下rebalance过程,但是前阵子遇到的rebalance的问题比较多,发现自己对rebalance的理解也仅仅是浮于表面,也就是网上和书上讲的宏观层面上的什么FIND_COORDINATOR -> JOIN -> SYNC -> STABLE这一套,但是服务端究竟是如何运转的呢?rebalance为什么会突然劣化导致停顿几分钟呢?依旧不甚了解,网上能查到的信息也都寥寥无几基本上也都是宏观上的几个阶段流转,所以决定自己重新去看一下这部分的源码,并记录下来。
另外就是这一篇文章可能会很长,因为rebalance本身是一个比较复杂的过程,各位要是对源码分析看不进去,我会在源码分析之前给出一个过程概述,可能会更好理解一点。源码这个东西,在博客上看,真是看来就忘,还是要自己打开IDE导入源码自己分析才能加深印象,当自己无法理解的时候,可以到博客里面搜一下相关的注释,看下别人的思路和理解,这是我个人认为看源码比较友好的方式。
话不多说,让我们从头到尾梳理一下rebalance把。
中文直译,就是重平衡。
是什么去重平衡呢?消费组内的消费者成员去重平衡。(消费组的概念如果不清楚各位先自行百度,后续我写到消费模块的时候才会提到这些概念)
为什么需要重平衡呢?因为消费组内成员的故障转移和动态分区分配。
翻译一下:
消费组内成员的故障转移:当一个消费组内有三个消费者A,B,C,分别消费分区:a,b,c
A -> a
B -> b
C -> c
此时如果A消费者出了点问题,那么就意味着a分区没有消费者进行消费了,那这肯定不行,那么就通过rebalance去将a分区分配给其他还存活着的消费者客户端,rebalance后可能得到的消费策略:
A -> a (GG)
B -> b,a
C -> c
这就是消费组内成员的故障转移,就是某个消费者客户端出问题之后把它原本消费的分区通过REBALNACE分配给其他存活的消费者客户端。
动态分区分配:当某个topic的分区数变化,对于消费组而言可消费的分区数变化了,因此就需要rebalance去重新进行动态分区分配,举个栗子,原本某topic只有3个分区,我现在扩成了10个分区,那么不就意味着多了7个分区没有消费者消费吗?这显然是不行的,因此就需要rebalance过程去进行分区分配,让现有的消费者去把这10个分区全部消费到。
这个其实在上面一小节已经提到的差不多了,在这个小节再做一点补充和总结。
触发条件:
整个rebalance的过程,是一个状态机流转的过程,整体过程示意图如下:图源:https://www.cnblogs.com/huxi2b/p/6815797.html 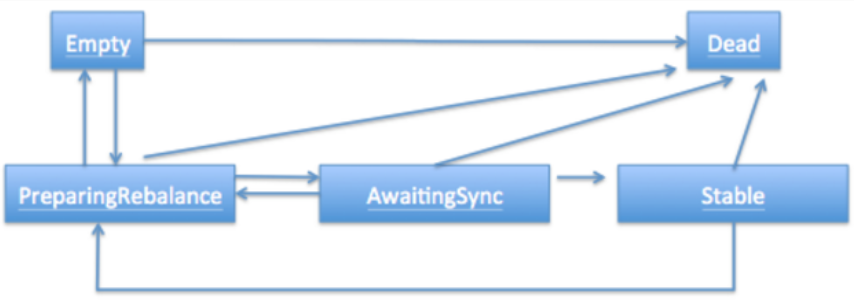
其实上面这个状态机流转过程在明白原理的情况下,已经非常清晰了,但是如果没看过源码的,依旧不知道为什么是这么流转的,什么情况下状态是Empty呢,什么状态下是Stable呢?什么时候Empty状态会转换为PreparingRebalance状态呢?
下面我就根据请求顺序来看下整个状态的流转过程: 
需要说明的一点是,上面请求的状态CompletingRebalance其实就对应上面的AwaitingSync状态。
让我们根据这个请求顺序图来解释一下各个状态是如何流转的:
Empty(Empty):当一个Group是新创建的,或者内部没有成员时,状态就是Empty。我们假设有一个新的消费组,这个消费组的第一个成员发送FIND_COORDINATOR请求的时候,也就是开启了Rebalacne的第一个阶段。
PreparingRebalance(JOIN):当完成FIND_COORDINATOR请求后,对应的客户端就能找到自己的coordinator节点是哪个,然后紧接着就会发送JOIN_GROUP请求,当coordinator收到这个请求后,就会把状态由Empty变更为PreparingRebalance,意味着准备要开始rebalance了。
CompletingRebalance(SYNC):当所有的成员都完成JOIN_GROUP请求的发送之后,或者rebalance过程超时后,对应的PreparingRebalance阶段就会结束,进而进入CompletingRebalance状态。
Stabe(Stable):在进入CompletingRebalance状态的时候呢,服务端会返回所有JOIN_GROUP请求对应的响应,然后客户端收到响应之后立刻就发送SYNC_GROUP请求,服务端在收到leader发送的SNYC_GROUP请求后,就会转换为Stable状态,意味着整个rebalance过程已经结束了。
上面整个过程,就是我们经常能在一些博客里面看到,其实里面有很多细节,例如这些请求都带有哪些关键数据,到底是哪个阶段导致rebalance过程会劣化到几分钟?为什么要分为这么多阶段?
让我们带着问题继续往下把,这些状态机流转的名字太长了,后面我会用上文中括号内的简写代表对应的阶段。
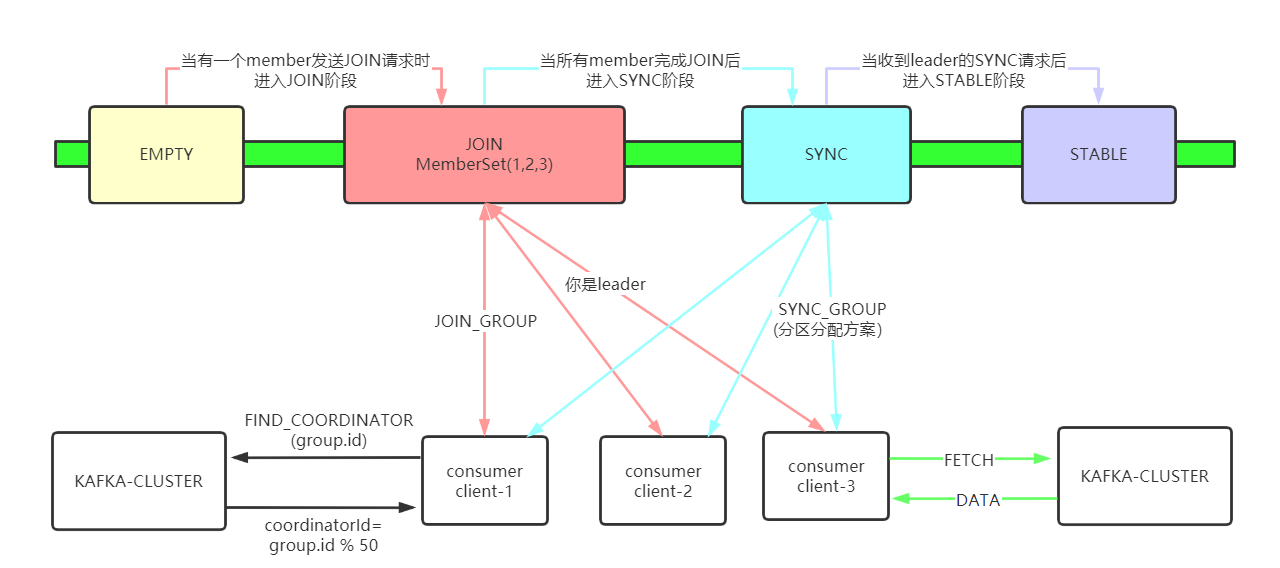
让我们来回答上个小节后面提出的几个比较细节的问题:
这些请求都带有哪些关键数据?
在FIND_COORDINATOR请求的时候,会带上自己的group.id值,这个值是用来计算它的coordinator到底在哪儿的,对应的计算方法就是:coordinatorId=groupId.hash % 50 这个算出来是个数字,代表着具体的分区,哪个topic的分区呢?显然是__consumer_offsets了。
在JOIN_GROUP请求的时候,是没带什么关键参数的,但是在响应的时候会挑选一个客户端作为leader,然后在响应中告诉它被选为了leader并且把消费组元数据信息发给它,然后让该客户端去进行分区分配。
在SYNC_GROUP请求的时候,leader就会带上它根据具体的策略已经分配好的分区分配方案,服务端收到后就更新到元数据里面去,然后其余的consumer客户端只要一发送SYNC请求过来就告诉它要消费哪些分区,然后让它自己去消费就ok了。
到底是哪个阶段导致rebalance过程会劣化到几分钟?
我图中特意将JOIN阶段标位红色,就是让这个阶段显得显眼一些,没错就是这个阶段会导致rebalance整个过程耗时劣化到几分钟。
具体的原因就是JOIN阶段会等待原先组内存活的成员发送JOIN_GROUP请求过来,如果原先组内的成员因为业务处理一直没有发送JOIN_GROUP请求过来,服务端就会一直等待,直到超时。这个超时时间就是max.poll.interval.ms的值,默认是5分钟,因此这种情况下rebalance的耗时就会劣化到5分钟,导致所有消费者都无法进行正常消费,影响非常大。
为什么要分为这么多阶段?
这个主要是设计上的考虑,整个过程设计的还是非常优雅的,第一次连上的情况下需要三次请求,正常运行的consumer去进行rebalance只需要两次请求,因为它原先就知道自己的coordinator在哪儿,因此就不需要FIND_COORDINATOR请求了,除非是它的coordinator宕机了。
回答完这些问题,是不是对整个rebalance过程理解加深一些了呢?其实还有很多细节没有涉及到,例如consumer客户端什么时候会进入rebalance状态?服务端是如何等待原先消费组内的成员发送JOIN_GROUP请求的呢?这些问题就只能一步步看源码了。
FIND_COORDINATOR请求的源码我就不打写了,很简单大家可以自己翻一下,就是带了个group.id上去,上面都提到了。
从这段函数我们知道,如果加入一个新的消费组,服务端收到第一个JOIN请求的时候会创建group,这个group的初始状态为Empty
// 如果group都还不存在,就有了memberId,则认为是非法请求,直接拒绝。
groupManager.getGroup(groupId) match {
case None =>
// 这里group都还不存在的情况下,memberId自然是空的
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))
} else {
// 初始状态是EMPTY
val group = groupManager.addGroup(new GroupMetadata(groupId, initialState = Empty))
// 执行具体的加组操作
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
case Some(group) =>
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
让我们进入doJoinGroup函数,看下里面的核心逻辑:
case Empty | Stable =>
// 初始状态是EMPTY,添加member并且执行rebalance
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
// ...
} else {
//...
}
private def addMemberAndRebalance(rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
clientId: String,
clientHost: String,
protocolType: String,
protocols: List[(String, Array[Byte])],
group: GroupMetadata,
callback: JoinCallback) = {
// 根据clientID初始化memberID
val memberId = clientId + "-" + group.generateMemberIdSuffix
// 封装一个member对象
val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs,
sessionTimeoutMs, protocolType, protocols)
member.awaitingJoinCallback = callback
// update the newMemberAdded flag to indicate that the join group can be further delayed
if (group.is(PreparingRebalance) && group.generationId == 0)
group.newMemberAdded = true
// 增加成员到group中
group.add(member)
maybePrepareRebalance(group)
member
}
def add(member: MemberMetadata) {
if (members.isEmpty)
this.protocolType = Some(member.protocolType)
assert(groupId == member.groupId)
assert(this.protocolType.orNull == member.protocolType)
assert(supportsProtocols(member.protocols))
// coordinator选举leader很简单,就第一个发送join_group请求的那个member
if (leaderId.isEmpty)
leaderId = Some(member.memberId)
members.put(member.memberId, member)
}
上面的代码翻译一下很简单,就是新来了一个member,封装一下,添加到这个group中,需要说一下的就是当组状态是Empty的情况下,谁先连上谁就是leader。紧接着就准备rebalance:
private def maybePrepareRebalance(group: GroupMetadata) {
group.inLock {
if (group.canRebalance)
prepareRebalance(group)
}
}
// 这里是传入PreparingRebalance状态,然后获取到一个SET
// 翻译一下:就是只有这个SET(Stable, CompletingRebalance, Empty)里面的状态,才能开启rebalance
def canRebalance = GroupMetadata.validPreviousStates(PreparingRebalance).contains(state)
private val validPreviousStates: Map[GroupState, Set[GroupState]] =
Map(Dead -> Set(Stable, PreparingRebalance, CompletingRebalance, Empty, Dead),
CompletingRebalance -> Set(PreparingRebalance),
Stable -> Set(CompletingRebalance),
PreparingRebalance -> Set(Stable, CompletingRebalance, Empty),
Empty -> Set(PreparingRebalance))
private def prepareRebalance(group: GroupMetadata) {
// if any members are awaiting sync, cancel their request and have them rejoin
if (group.is(CompletingRebalance))
resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)
val delayedRebalance = if (group.is(Empty))
new InitialDelayedJoin(this,
joinPurgatory,
group,
groupConfig.groupInitialRebalanceDelayMs,// 默认3000ms,即3s
groupConfig.groupInitialRebalanceDelayMs,
max(group.rebalanceTimeoutMs - groupConfig.groupInitialRebalanceDelayMs, 0))
else
new DelayedJoin(this, group, group.rebalanceTimeoutMs)// 这里这个超时时间是客户端的poll间隔,默认5分钟
// 状态机转换:EMPTY -> PreparingRebalance
group.transitionTo(PreparingRebalance)
// rebalance开始标志日志
info(s"Preparing to rebalance group ${group.groupId} with old generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// 加入时间轮
val groupKey = GroupKey(group.groupId)
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}
上面这段代码有两个关键点,一个是判断当前能否进入rebalance过程,可以看到只有(Stable, CompletingRebalance, Empty)里面的状态,才能开启rebalance,而最开始来到第一个member的时候,组的状态是Empty显然是能进来的,但是近来之后就给转换为了PreparingRebalance状态,那么后续的member发送JOIN请求过来之后就进不来了,就只能设置个回调后一直等。
那么要等到什么时候呢?第二段代码写的很清楚就是等待延时任务超时,这个延时任务创建是根据当前状态来判断的,如果是Empty就创建一个InitialDelayedJoin延时任务,超时时间是3s;如果不是Empty就创建一个DelayedJoin,超时时间默认是5min。看,源码出真知,这就是JOIN阶段等待member的代码实现。
这里需要补充一下,为什么Empty的状态下要等待3s呢?这其实是一个优化,主要就是优化多消费者同时连入的情况。举个栗子,10个消费者都能在3s内启动然后练上,如果你等着3s时间那么一次rebalance过程就搞定了,如果你不等,那么就意味着来一个就又要开启一次rebalance,一共要进行10次rebalance,这个耗时就比较长了。具体的细节可以查看:https://www.cnblogs.com/huxi2b/p/6815797.html
另外就是,为什么状态不是Empty的时候就延时5分钟呢?这个其实上面就回答了,要等待原来消费组内在线的消费者发送JOIN请求,这个也是rebalance过程耗时劣化的主要原因。
接下来我们看看这两个延时任务,在超时的时候分别都会做些啥,首先是InitialDelayedJoin:
/**
* Delayed rebalance operation that is added to the purgatory when a group is transitioning from
* Empty to PreparingRebalance
*
* When onComplete is triggered we check if any new members have been added and if there is still time remaining
* before the rebalance timeout. If both are true we then schedule a further delay. Otherwise we complete the
* rebalance.
*/
private[group] class InitialDelayedJoin(coordinator: GroupCoordinator,
purgatory: DelayedOperationPurgatory[DelayedJoin],
group: GroupMetadata,
configuredRebalanceDelay: Int,
delayMs: Int,
remainingMs: Int) extends DelayedJoin(coordinator, group, delayMs) {
// 这里写死是false,是为了在tryComplete的时候不被完成
override def tryComplete(): Boolean = false
override def onComplete(): Unit = {
// 延时任务处理
group.inLock {
// newMemberAdded是后面有新的member加进来就会是true
// remainingMs第一次创建该延时任务的时候就是3s。
// 所以这个条件在第一次的时候都是成立的
if (group.newMemberAdded && remainingMs != 0) {
group.newMemberAdded = false
val delay = min(configuredRebalanceDelay, remainingMs)
// 最新计算的remaining恒等于0,其实本质上就是3-3=0,
// 所以哪怕这里是新创建了一个InitialDelayedJoin,这个任务的超时时间就是下一刻
// 这么写的目的其实就是相当于去完成这个延时任务
val remaining = max(remainingMs - delayMs, 0)
purgatory.tryCompleteElseWatch(new InitialDelayedJoin(coordinator,
purgatory,
group,
configuredRebalanceDelay,
delay,
remaining
), Seq(GroupKey(group.groupId)))
} else
// 如果没有新的member加入,直接调用父类的函数
// 完成JOIN阶段
super.onComplete()
}
}
}
大意我都写在注释里面了,其实就是等待3s,然后完了之后调用父类的函数完成整个JOIN阶段,不过不联系上下文去看,还是挺费劲的,对了看这个需要对时间轮源码有了解,正好我前面有写,大家如果有什么不清楚的可以去看下。
接着看下DelayedJoin超时后会干嘛:
/**
* Delayed rebalance operations that are added to the purgatory when group is preparing for rebalance
*
* Whenever a join-group request is received, check if all known group members have requested
* to re-join the group; if yes, complete this operation to proceed rebalance.
*
* When the operation has expired, any known members that have not requested to re-join
* the group are marked as failed, and complete this operation to proceed rebalance with
* the rest of the group.
*/
private[group] class DelayedJoin(coordinator: GroupCoordinator,
group: GroupMetadata,
rebalanceTimeout: Long) extends DelayedOperation(rebalanceTimeout, Some(group.lock)) {
override def tryComplete(): Boolean = coordinator.tryCompleteJoin(group, forceComplete _)
override def onExpiration() = coordinator.onExpireJoin()
override def onComplete() = coordinator.onCompleteJoin(group)
}
// 超时之后啥也没干,哈哈,因为确实不用做啥,置空就好了
// 核心是onComplete函数和tryComplete函数
def onExpireJoin() {
// TODO: add metrics for restabilize timeouts
}
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = {
group.inLock {
if (group.notYetRejoinedMembers.isEmpty)
forceComplete()
else false
}
}
def notYetRejoinedMembers = members.values.filter(_.awaitingJoinCallback == null).toList
def forceComplete(): Boolean = {
if (completed.compareAndSet(false, true)) {
// cancel the timeout timer
cancel()
onComplete()
true
} else {
false
}
}
def onCompleteJoin(group: GroupMetadata) {
group.inLock {
// remove any members who haven‘t joined the group yet
// 如果组内成员依旧没能连上,那么就删除它,接收当前JOIN阶段
group.notYetRejoinedMembers.foreach { failedMember =>
group.remove(failedMember.memberId)
// TODO: cut the socket connection to the client
}
if (!group.is(Dead)) {
// 状态机流转 : preparingRebalancing -> CompletingRebalance
group.initNextGeneration()
if (group.is(Empty)) {
info(s"Group ${group.groupId} with generation ${group.generationId} is now empty " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
groupManager.storeGroup(group, Map.empty, error => {
if (error != Errors.NONE) {
// we failed to write the empty group metadata. If the broker fails before another rebalance,
// the previous generation written to the log will become active again (and most likely timeout).
// This should be safe since there are no active members in an empty generation, so we just warn.
warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")
}
})
} else {
// JOIN阶段标志结束日志
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// trigger the awaiting join group response callback for all the members after rebalancing
for (member <- group.allMemberMetadata) {
assert(member.awaitingJoinCallback != null)
val joinResult = JoinGroupResult(
// 如果是leader 就返回member列表及其元数据信息
members = if (group.isLeader(member.memberId)) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = member.memberId,
generationId = group.generationId,
subProtocol = group.protocolOrNull,
leaderId = group.leaderOrNull,
error = Errors.NONE)
member.awaitingJoinCallback(joinResult)
member.awaitingJoinCallback = null
completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}
}
}
上面这一串代码有几个要点,首先,这个任务超时的时候是啥也不干的,为什么呢?这里要了解时间轮的机制,代码也在上面,当一个任务超时的时候,时间轮强制执行对应任务的onComplete函数,然后执行onExpiration函数,其实onExpiration函数对于这个延时任务来说是没有意义的,并不需要做什么,打日志都懒得打。
第二点就是这个任务onComplete什么时候会被调用呢?难道就只能等待5分钟超时才能被调用吗?那不是每一次rebalance都必须要等待5分钟?当然不可能啦,这里就需要先看下tryComplete函数的内容,发现这个内容会去检查还没连上的member,如果发现到期了,就强制完成。那么我们看下这tryComplete是在哪儿被调用的?这里需要插入一点之前没贴全的代码,在doJoinGroup函数中的而最后一段:
if (group.is(PreparingRebalance))
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
这段代码非常关键,当当前状态是PreparingRebalance的时候,会尝试去完成当前的延时任务,最终调用的代码:
private[server] def maybeTryComplete(): Boolean = {
var retry = false
var done = false
do {
if (lock.tryLock()) {
try {
tryCompletePending.set(false)
done = tryComplete()
} finally {
lock.unlock()
}
// While we were holding the lock, another thread may have invoked `maybeTryComplete` and set
// `tryCompletePending`. In this case we should retry.
retry = tryCompletePending.get()
} else {
// Another thread is holding the lock. If `tryCompletePending` is already set and this thread failed to
// acquire the lock, then the thread that is holding the lock is guaranteed to see the flag and retry.
// Otherwise, we should set the flag and retry on this thread since the thread holding the lock may have
// released the lock and returned by the time the flag is set.
retry = !tryCompletePending.getAndSet(true)
}
} while (!isCompleted && retry)
done
}
就是上面的tryComplete函数,最终会调用到DelayedJoin中的tryComplete函数,什么意思呢?已经很明显了,每来一个JOIN请求的时候,如果处于PreparingRebalance阶段,都会去检查一下group中原来的成员是否已经到齐了,到齐了就立刻结束JOIN阶段往后走。看到这儿,回头看下InitialDelayedJoin这个延时任务的tryComplete为什么就默认实现了个false呢?也明白了,就是初始化延时任务的时候不让你尝试完成,我就等3s,不需要你们来触发我提前完成。
以上,我们就看完了整个服务端的JOIN请求处理过程,其实主要核心就是这两个延时任务,如果不联系上下文,不了解时间轮机制,看起来确实费劲。接下来就看下SYNC阶段是如何处理的。
直接看下面的核心源码逻辑:
private def doSyncGroup(group: GroupMetadata,
generationId: Int,
memberId: String,
groupAssignment: Map[String, Array[Byte]],
responseCallback: SyncCallback) {
group.inLock {
if (!group.has(memberId)) {
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
} else if (generationId != group.generationId) {
responseCallback(Array.empty, Errors.ILLEGAL_GENERATION)
} else {
group.currentState match {
case Empty | Dead =>
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
case PreparingRebalance =>
responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS)
// 只有group处于compeletingRebalance状态下才会被处理
// 其余状态都是错误的状态
case CompletingRebalance =>
// 给当前member设置回调,之后就啥也不干,也不返回
// 等到leader的分区方案就绪后,才会被返回。
group.get(memberId).awaitingSyncCallback = responseCallback
// if this is the leader, then we can attempt to persist state and transition to stable
// 只有收到leader的SYNC才会被处理,并进行状态机流转
if (group.isLeader(memberId)) {
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")
// fill any missing members with an empty assignment
val missing = group.allMembers -- groupAssignment.keySet
val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap
groupManager.storeGroup(group, assignment, (error: Errors) => {
group.inLock {
// another member may have joined the group while we were awaiting this callback,
// so we must ensure we are still in the CompletingRebalance state and the same generation
// when it gets invoked. if we have transitioned to another state, then do nothing
if (group.is(CompletingRebalance) && generationId == group.generationId) {
if (error != Errors.NONE) {
resetAndPropagateAssignmentError(group, error)
maybePrepareRebalance(group)
} else {
setAndPropagateAssignment(group, assignment)
// 状态机流转:CompletingRebalance -> Stable
group.transitionTo(Stable)
}
}
}
})
}
// 如果已经处于stable状态,说明leader已经把分区分配方案传上来了
// 那么直接从group的元数据里面返回对应的方案就好了
case Stable =>
// if the group is stable, we just return the current assignment
val memberMetadata = group.get(memberId)
responseCallback(memberMetadata.assignment, Errors.NONE)
// 开启心跳检测
completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))
}
}
}
}
我们可能对上面的代码案处理会有一个疑问,为什么只有leader的SYNC请求才会被处理呢?要是其他consumer比leader早上来了难道就卡这儿不管了?不像JOIN阶段那样加入个时间轮设置个最大超时时间?这要是leader一直不发送SNYC请求,那不就所有成员都这儿干等着,无限等待了?
我们一个个来回答,首先,我们看上面的代码,每个请求过来第一件事是先设置回调,然后才去卡住等着,直到leader把分区分配方案通过SYNC请求带上来。
第二个问题,如果其他consumer比leader早到了就这么干等着吗?是的,没错,代码就是这么写的。
第三个问题,为什么不设置个最大超时时间啥的?我们可以看下客户端的代码,一旦开启rebalance之后,就只会进行相关请求的收发,意味着leader在收到JOIN阶段的返回后,中间不会有任何业务代码的影响,直接就是分配完分区然后发送SYNC请求;这就意味着leader的JOIN响应和SYNC请求之间理论上是不存在阻塞的,因此就可以不用设置超时,就不用加入时间轮了。
第四个问题,leader一直不发送SYNC请求就干等着?是的,代码就是这么写的。不过你想想,哪些情况能让leader一直不发送SYNC请求?我能想到的就是GC/leader宕机了,无论是哪种情况都会因为心跳线程出了问题被服务端检测到,因此在对应的心跳任务超时后重新开启下一轮的rebalance。哪怕是GC很长时间之后恢复了继续发SYNC请求过来,也会因为generation不匹配而得到错误返回开启下一轮rebalance。
最后再看下leader到了之后会具体做啥:
private def setAndPropagateAssignment(group: GroupMetadata, assignment: Map[String, Array[Byte]]) {
assert(group.is(CompletingRebalance))
// 给每个member的分配方案赋值
group.allMemberMetadata.foreach(member => member.assignment = assignment(member.memberId))
// 在整个group中传播这个分配方案
propagateAssignment(group, Errors.NONE)
}
private def propagateAssignment(group: GroupMetadata, error: Errors) {
// 遍历
// 如果是follower比leader先到SYNC请求
// 那么就只会设置个callback,就啥都不干了,也不会返回
// 直到leader带着分配方案来了以后,把状态更改为stable之后,才会遍历
// 看看有哪些member已经发送了请求过来,设置了callback,然后一次性给他们返回回去对应的分区方案
// 所以这个名称叫做【传播分配方案】
// 真是绝妙
for (member <- group.allMemberMetadata) {
if (member.awaitingSyncCallback != null) {
// 通过回调告诉member对应的分配方案
member.awaitingSyncCallback(member.assignment, error)
member.awaitingSyncCallback = null
// reset the session timeout for members after propagating the member‘s assignment.
// This is because if any member‘s session expired while we were still awaiting either
// the leader sync group or the storage callback, its expiration will be ignored and no
// future heartbeat expectations will not be scheduled.
completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}
看,最开始设置的回调,在收到leader请求时候,起了作用;会被挨个遍历后响应具体的分区分配方案,另外就是kafka里面的命名都很准确。
SYNC阶段简单说起来就是等待leader把分区分配方案传上来,如果member先到就设置个回调先等着,如果leader先到,就直接把分区分配方案存到group的元数据中,然后状态修改为Stable,后续其他member来的SYNC请求就直接从group的元数据取分区分配方案,然后自己消费去了。
八、线上如何排查rebalance问题?
看完理论,让我们来看下线上问题怎么排查rebalance问题。 rebalance有哪些问题呢?我们来整理一下:
首先,为什么会rebalance,这个就三种情况,分区信息变化、客户端变化、coordinator变化。
一般线上常见的就是客户端变化,那么客户端有哪些可能的变化呢?——新增成员,减少成员。
新增成员怎么看呢?很简单嘛,找到coordinator,然后去kafka-request.log里面搜:cat kafka-request.log |grep -i find | grep -i ${group.id} 不过一般FIND_COORDINATOR请求的处理时间都小于10ms,所以只能打开debug日志才能看到。一般这种让客户自己看,对应的时间点是不是有启动kafka-consumer就行了,其实也不常见,这种情况。毕竟很少有人频繁开启关闭消费者,就算是有也是不好的业务使用方式。
减少成员呢?又分为两种:心跳超时,poll间隔超过配置 心跳超时的标识日志:
def onExpireHeartbeat(group: GroupMetadata, member: MemberMetadata, heartbeatDeadline: Long) {
group.inLock {
if (!shouldKeepMemberAlive(member, heartbeatDeadline)) {
// 标识日志
info(s"Member ${member.memberId} in group ${group.groupId} has failed, removing it from the group")
removeMemberAndUpdateGroup(group, member)
}
}
}
很遗憾poll间隔超时,在1.1.0版本的info级别下并没有可查找的日志,检测poll时间间隔超时的是对应客户端的心跳线程,在检测到超过配置后就会主动leaveGroup从而触发rebalance,而这个请求在服务端依旧没有info级别的请求,因此,要判断是poll间隔超时引起的rebalance,就只能看下有没有上面心跳超时的日志,如果没有可能就是因为这个原因造成的。目前大多数的rebalance都是因为这个原因造成的,而且这个原因引发的rebalance同时还可能伴随着很长的rebalance耗时。
来看下服务端是如何做poll间隔超时的呢?
} else if (heartbeat.pollTimeoutExpired(now)) {
// the poll timeout has expired, which means that the foreground thread has stalled
// in between calls to poll(), so we explicitly leave the group.
maybeLeaveGroup();
}
public boolean sessionTimeoutExpired(long now) {
return now - Math.max(lastSessionReset, lastHeartbeatReceive) > sessionTimeout;
}
public synchronized void maybeLeaveGroup() {
if (!coordinatorUnknown() && state != MemberState.UNJOINED && generation != Generation.NO_GENERATION) {
// this is a minimal effort attempt to leave the group. we do not
// attempt any resending if the request fails or times out.
log.debug("Sending LeaveGroup request to coordinator {}", coordinator);
LeaveGroupRequest.Builder request =
new LeaveGroupRequest.Builder(groupId, generation.memberId);
client.send(coordinator, request)
.compose(new LeaveGroupResponseHandler());
client.pollNoWakeup();
}
resetGeneration();
}
总结一下,怎么定位rebalance的问题,就是找标志日志,然后排除法,实在不行了就打开debug日志。
接着看第二个问题,rebalance一次的时间耗费了多久?为什么会劣化到几分钟? 因为整个rebalance过程是线性的过程,就是状态按照请求顺序流转,因此呢找到对应的标志日志就好啦。 开启的标志日志:
// rebalance开始标志日志
info(s"Preparing to rebalance group ${group.groupId} with old generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
结束的两种标识日志:这两种结束日志都行,因为都差不多代表着rebalance过程完成,原因在上面已经讲的很清楚了。
// JOIN阶段标志结束日志
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// SYNC阶段结束日志
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")
那么如何统计整个rebalance过程的时间呢? 显而易见,结束时间 - 开始时间呀。
知道是怎么什么原因开启了rebalance之后,该怎么定位业务问题呢? 心跳超时:因为心跳线程是守护线程,一般都是因为客户端的机器负载太高导致心跳现场无法获取到CPU导致的。
poll间隔超过配置:显然嘛,就是poll出来数据之后,进行业务处理的时候太慢了,建议根据业务优化消费逻辑,改成多线程消费或者异步消费。
这个很简单,我们想一下,与这个group有关的元数据全部都在coordinator那里,哪些请求会与coordinator交互呢?HEARTBEAT/OFFSET_COMMIT嘛,就这俩,那么其实正常的member都是靠这两个请求来感知到自己要去进行rebalance的,我们分别来看下。
首先是HEARTBEAT请求,每次都会带上当前消费组的generation值,也就是纪元值,要是服务端rebalance已经完成了,纪元值+1,那么此时就会发现自己没匹配上,然后紧接着就去设置自己的RejoinNeeded的标识,在下一轮poll 的时候就会去开启rebalance。
如果说是rebalance还没完成,那就更简单了,发现group的状态不是stable,直接就返回对应的错误,然后设置标识,加入到rebalance过程中。
服务端源码:
case Some(group) =>
group.inLock {
group.currentState match {
case Dead =>
// if the group is marked as dead, it means some other thread has just removed the group
// from the coordinator metadata; this is likely that the group has migrated to some other
// coordinator OR the group is in a transient unstable phase. Let the member retry
// joining without the specified member id,
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case Empty =>
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case CompletingRebalance =>
if (!group.has(memberId))
responseCallback(Errors.UNKNOWN_MEMBER_ID)
else
responseCallback(Errors.REBALANCE_IN_PROGRESS)
case PreparingRebalance =>
if (!group.has(memberId)) {
responseCallback(Errors.UNKNOWN_MEMBER_ID)
} else if (generationId != group.generationId) {
responseCallback(Errors.ILLEGAL_GENERATION)
} else {
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
responseCallback(Errors.REBALANCE_IN_PROGRESS)
}
case Stable =>
if (!group.has(memberId)) {
responseCallback(Errors.UNKNOWN_MEMBER_ID)
// 纪元切换
} else if (generationId != group.generationId) {
responseCallback(Errors.ILLEGAL_GENERATION)
} else {
val member = group.get(memberId)
// 完成上次的延时,新建新的延时任务
completeAndScheduleNextHeartbeatExpiration(group, member)
// 回调响应
responseCallback(Errors.NONE)
}
客户端源码:
private class HeartbeatResponseHandler extends CoordinatorResponseHandler<HeartbeatResponse, Void> {
@Override
public void handle(HeartbeatResponse heartbeatResponse, RequestFuture<Void> future) {
sensors.heartbeatLatency.record(response.requestLatencyMs());
Errors error = heartbeatResponse.error();
if (error == Errors.NONE) {
log.debug("Received successful Heartbeat response");
future.complete(null);
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
log.debug("Attempt to heartbeat since coordinator {} is either not started or not valid.",
coordinator());
markCoordinatorUnknown();
future.raise(error);
} else if (error == Errors.REBALANCE_IN_PROGRESS) {
log.debug("Attempt to heartbeat failed since group is rebalancing");
requestRejoin();
future.raise(Errors.REBALANCE_IN_PROGRESS);
} else if (error == Errors.ILLEGAL_GENERATION) {
log.debug("Attempt to heartbeat failed since generation {} is not current", generation.generationId);
resetGeneration();
future.raise(Errors.ILLEGAL_GENERATION);
} else if (error == Errors.UNKNOWN_MEMBER_ID) {
log.debug("Attempt to heartbeat failed for since member id {} is not valid.", generation.memberId);
resetGeneration();
future.raise(Errors.UNKNOWN_MEMBER_ID);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(groupId));
} else {
future.raise(new KafkaException("Unexpected error in heartbeat response: " + error.message()));
}
}
}
protected synchronized void requestRejoin() {
this.rejoinNeeded = true;
}
所以我们客户端看到这种异常,就知道怎么回事了,就是我在rebalance的过程中,或者已经完成了,客户端的纪元不对。
REBALANCE_IN_PROGRESS(27, "The group is rebalancing, so a rejoin is needed.",
new ApiExceptionBuilder() {
@Override
public ApiException build(String message) {
return new RebalanceInProgressException(message);
}
}),
ILLEGAL_GENERATION(22, "Specified group generation id is not valid.",
new ApiExceptionBuilder() {
@Override
public ApiException build(String message) {
return new IllegalGenerationException(message);
}
}),
我们再看OFFSET_COMMIT请求,其实和HEARTBEAT请求是基本一致的。
服务端:
group.inLock {
if (group.is(Dead)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID))
} else if ((generationId < 0 && group.is(Empty)) || (producerId != NO_PRODUCER_ID)) {
// The group is only using Kafka to store offsets.
// Also, for transactional offset commits we don‘t need to validate group membership and the generation.
groupManager.storeOffsets(group, memberId, offsetMetadata, responseCallback, producerId, producerEpoch)
} else if (group.is(CompletingRebalance)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.REBALANCE_IN_PROGRESS))
} else if (!group.has(memberId)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID))
} else if (generationId != group.generationId) {
responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION))
} else {
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
groupManager.storeOffsets(group, memberId, offsetMetadata, responseCallback)
}
}
}
客户端:
else if (error == Errors.UNKNOWN_MEMBER_ID
|| error == Errors.ILLEGAL_GENERATION
|| error == Errors.REBALANCE_IN_PROGRESS) {
// need to re-join group
resetGeneration();
future.raise(new CommitFailedException());
return;
/**
* Reset the generation and memberId because we have fallen out of the group.
*/
protected synchronized void resetGeneration() {
this.generation = Generation.NO_GENERATION;
this.rejoinNeeded = true;
this.state = MemberState.UNJOINED;
}
从源码我们可以看到,客户端在感知rebalance主要通过两个机制,一个是状态,一个是纪元;状态生效于rebalance过程中,纪元生效于rebalance的JOIN阶段结束后。
与coordinator交互的这两个请求都会带上自己的纪元信息,在服务端处理前都会校验一下状态已经纪元信息,一旦不对,就告诉客户端你需要rebalance了。
首先明确下,rebalance会有什么影响?引用JVM的术语来说,就是STOP THE WORLD。
一旦开启rebalance过程,在消费者进入JOIN阶段后就无法再继续消费,就是整个group的成员全部STW,所以对业务的影响还是很大的。
那么如何减小rebalance的影响呢?知道rebalance的原理之后,方案自然就有了嘛。
KAFKA进阶:【十二】能否说一下你对rebalance的了解?全网最详细的rebalance源码分析,基于1.1.0
标签:转换 ber marked war public 对象 record 没有 upm
原文地址:https://www.cnblogs.com/keepal/p/14729336.html