标签:tput 数据 椭圆 文件名 nsf distance style 转化 pixel
操作步骤
1、PCA变换。将实验数据20180419.dat导入ENVI,如果没有数据统计文件(.sta文件),通过Transform->PCA Rotation->Forward PCA Rotation New Statistics and Rotate计算数据特征值、协方差或相关系数矩阵后进行Forward PCA Rotation。在Forward PC Parameters窗口中可以根据需要剪裁输出区域;调整重采样系数;选择主成分计算方式以及确定输出波段数。逆PCA变换。在输入对应的统计文件(.sta文件)后,Inverse PCA Rotation工具可将主成分图像变换回原始数据空间。在Inverse PC Parameters窗口中选择的计算矩阵需与正向PC旋转使用的计算矩阵相同。
2、IsoData Classification非监督分类。通过Classification -> Unsupervised Classification->IsoData Classification使用IsoData方法进行非监督分类。Number of Classes:输入类别数量的最小值和最大值来确定其范围;Maximum Iterations:确定迭代次数;Change Threshold:当每一类的像元变化小于阈值时结束迭代;Minimum # Pixel in Class:确定形成一类需要的最少像元数;Maximum Class Stdv:如果一类的阈值比这一阈值大,则将其拆分成两类;Minimum Class Distance:如果类均值之间的距离小于这一阈值,则将其合并;Maximum # Merge Pairs:合并成对的最大值。
3、K-Means Classification非监督分类。通过Classification->Unsupervised Classification->K-Means Classification选择K - Means 方法。Number of Classes:输入类别数量,输入10;Maximum Iterations:确定迭代次数,输入10;Change Threshold:当每一类的像元变化小于阈值时结束迭代。
4、类别更改及合并。在分类结果的Classes上右键,然后点击Edit Class Names and Colors,在弹出的窗口中更改类别名称及颜色。通过Classification->Post Classification->Combine Classes进行类别合并。在Combine Classes Parameters窗口中,确定将哪几类合并成一类,点击OK后,在Combine Classes Output窗口中设置输出文件名和是否移除空类。
5、分类统计分析。通过Classification->Post Classification->Class Statistics进行各类别的统计分析。
6、小图斑处理。可通过Classification->Post Classification中的Majority/Minority Analysis和Clump Classes将周围的小图斑合并到大类中,也可通过Sieve Classes将不符合的小图斑直接剔除。
7、栅矢转换。通过Classification->Post Classification->Classification to Vector将分类结果转化为矢量文件。
分析讨论
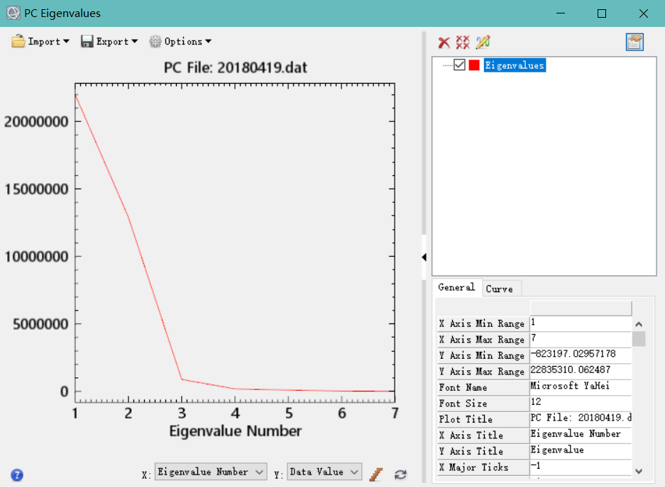
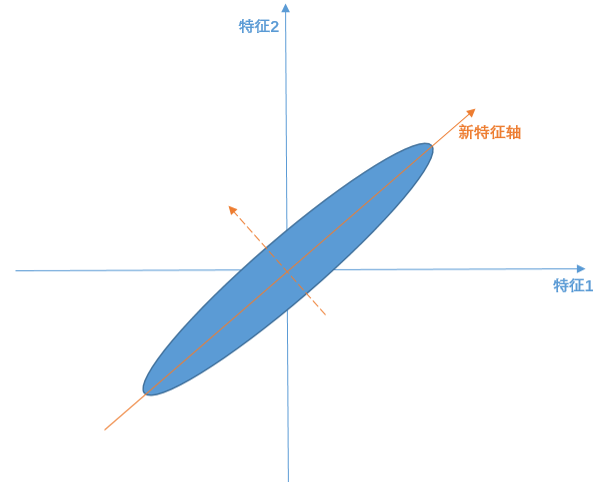
1、PCA变换。PCA全称Principal Component Analysis,即主成分分析,是一种常用的数据降维方法。它可以通过线性变换将原始数据变换为一组各维度线性无关的表示,以此来提取数据的主要线性分量。如下图所示,样本点分布为斜45°的蓝色椭圆区域。PCA算法认为斜45°为主要线性分量,与之正交的虚线是次要线性分量(应当舍去以达到降维的目的)。PCA解释方差并对离群点很敏感:少量原远离中心的点对方差有很大的影响,从而也对特征向量有很大的影响。
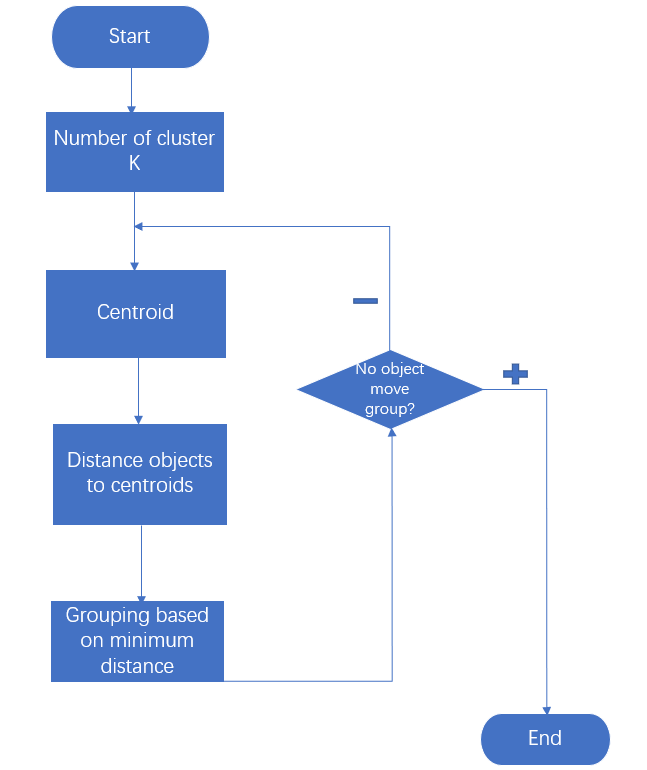
2、聚类K-Means算法。属于非监督学习(unsupervised learning),是无类别标记(class label)。K-means算法是聚类(clustering)中的经典算法,数据挖掘的十大经典算法之一。算法接收参数K,然后将事先输入的n个数据划分为K个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高,而不同聚类中的对象相似度较低。算法思想:以空间中K个点作为中心进行聚类,对最靠近它们的对象进行归类; 通过迭代的方法,逐渐更新各聚类中心的值,直至得到最好的聚类结果。流程图如下图所示:
优点:速度快、简单缺点:最终结果跟初始点选择相关,容易陷入局部最优,需要知道K值,有可能在分类之前不知道要分成几类。下图是ENVI在使用K-Means方法过程中的迭代次数进度。
3、ISODATA分类法。K-Means分类方法的一个重要缺点是:分类的类别数目事先必须确定下来,而作为非监督分类,事先我们很难去确定待分类的集合(样本)中到底有多少类别,基于这一缺点,提出了另外一种非监督分类方法:迭代自组织数据分析算法(ISODATA),它在K-均值算法的基础上,对分类过程增加了“合并”和“分裂”两个操作,并通过设定参数来控制这两个操作的一种聚类算法。
ISODATA的聚类的类别数目随着聚类的进行,是变化着的,因为在聚类的过程中,对类别数有一个“合并”和“分裂”的操作。合并是当聚类结果某一类中样本数太少,或两个类间的距离太近时,将这两个类别合并成一个类别;分裂是当聚类结果中某一类的类内方差太大,将该类进行分裂,分裂成两个类别。
优缺点:ISODATA 可以在聚类过程中自动调整类别个数和类别中心,使聚类结果能更加靠近客观真实的聚类结果。ISODATA算法需要设置的参数比较多,参数值不好确定。不同的参数之间相互影响,而且参数的值和聚类的样本集合也有关系,要得到好的聚类结果,需要有好的初始设置值,可以通过多次设置不同的值进行不同的实验,然后取一些已知的样本来检验聚类结果的精度,以最后取得更好的分类结果的那次实验为准;或者考虑和其他方法相结合来得到更好的分类结果。
4、分类后处理。
主要分析Majority 采用类似于卷积滤波的方法将较大类别中的虚假像元归到该类中,定义一个变换核尺寸,用变换核中占主要地位(像元数最多)的像元类别代替中心像元的类别。
次要分析Minority 用变换核中占次要地位的像元的类别代替中心像元的类别。
聚类处理Clump 运用数学形态学算子(腐蚀和膨胀),将临近的类似分类区域聚类并进行合并。首先将被选的分类用一个膨胀操作合并到一块,然后用变换核对分类图像进行腐蚀操作。优点:分类图像经常缺少空间连续性(分类区域中斑点或洞的存在)。低通滤波虽然可以用来平滑这些图像,但是类别信息常常会被临近类别的编码干扰,聚类处理解决了这个问题。
过滤处理Sieve 使用斑点分组方法来消除这些被隔离的分类像元。类别筛选方法通过分析周围的4个或8个像元,判定一个像元是否与周围的像元同组。如果一类中被分析的像元数少于输入的阈值,这些像元就会被从该类中删除,删除的像元归为未分类的像元(Unclassified) 解决分类图像中出现的孤岛问题。
标签:tput 数据 椭圆 文件名 nsf distance style 转化 pixel
原文地址:https://www.cnblogs.com/yuukirito/p/14749301.html