标签:神经网络 收藏 ica ssm 网络 工业 增强 详解 data
目前用的较多的算法ESMM和MMOE类的算法,都是基于目标的重要性是对等或线性相关来优化的,也一定程度上仿真建模解决了业务的需求。后面会细讲一下最基础的两个算法ESMM和MMOE,这里概括一下:
MMOE 模型进化过程:
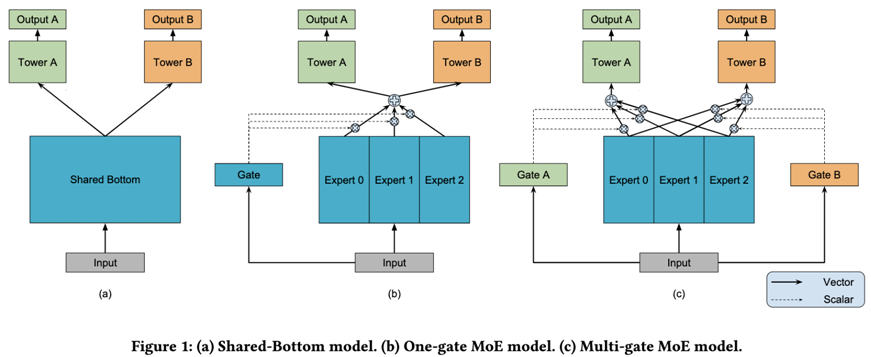
(1)Shared-Bottom结构模型
模型结构层面,底层使用经典的Shared-Bottom结构,如下图a中所示,底层特征共享,一般分为categorical和numeric特征,前一类需要先做embedding稠密转化,后一类直接拼接就可以,接着使用全连接层学习,整个底层为共享网络。上层针对不同目标分别学习自己的网络,最后输出结果。
模型可以表示为yk=hk(f(x))yk=hk(f(x)),其中k表示k个目标,f(x)表示底层模型,对应到图中底层Shared-Bottom,hkhk表示第k个目标,为图中上面两个网络部分。
这样设计的好处是模型结构简单,参数少,问题是模型拟合能力不强,上层塔对拟合自己对应目标所需要的底层输入没有差异,如果上层学习两个任务差异性比较大则效果会很差。
(2)MOE模型
针对上面问题就产生了下图b的MOE模型,主要解决上面说的拟合能力不强的问题,既然单个模型拟合能力弱,那能不能使用集成学习的思想,搞多个模型学习综合结果呢,MOE基本就是这个思路,每一个模型可以称作一个专家模型(Expert model),然后针对每个Expert产生的结果,需要加权综合,也就是Gate机制,给每个Expert学习出不同的权重,控制其对最终上层多个模型的影响。
表示为yk=hk(∑ni=1gi·fi(x))yk=hk(∑i=1ngi·fi(x)),其中i表示第i个Expert模型,然后每个模型又一个权重gigi,其中∑ni=1gi=1∑i=1ngi=1。
上面模型创新点其实比较大,但是依然遗留下来一个问题加入上层多目标见差异比较大,或者说是类型两阶段或多阶段的多目标,则会效果比较差,MMOE给出的解决方案是,针对不同目标分别学习自己的Gate,事后想想这样才是合理的,而且也没有增加多少参数,如下面图c所示。
表示为yk=hk(∑ni=1gi,k·fi(x))yk=hk(∑i=1ngi,k·fi(x)),第i个Expert模型和对应的第k个目标,分别学习自己的Gate权重gi,kgi,k,其中对于每个目标∑ni=1gi=1∑i=1ngi=1。
这里会涉及到Expert的数量,需要权衡模型复杂度和模型效果,找出合理的Expert数。
(1)MMOE一个模型有几个Loss?他跟多标签分类学习有什么区别?既然是多目标,多个专家网络,直接多个模型不是更好的解决问了吗?
搞清这些问题,需要从多目标优化的业务需求和真实数据场景讲起。所谓的多目标优化,是指真实业务场景中,一次排序展示,需要得到多个结果。例如电商的相关推荐,希望一次推荐排序好的商品,既能让用户点击,也能让用户下单,甚至还能让用户满意(好评)。又如一次新闻(视频)推荐,如果光考虑点击,可能一些猎奇的标题党更抢流量;我们希望点击,希望用户浏览时间长;并且还希望用户喜欢这个内容,转发或者收藏就更牛了。
理解了这个点,就不会考虑多个目标用多个模型了,首先,线上实时排序,不可能多个模型部署,这样耗时太高;其次训练管理多个模型的数据集,也是在工业界的最大成本。大数据集存储多份,不合适。当然,最重要的不是这个,而是核心的算法精度诉求:多个模型,每个模型预测一个值,拿来综合排序,由于每个模型是单独训练的,因而他们的排序序列是互斥的,容易顾此失彼,专注点击的模型+专注转化的模型<max(CTR,CVR)是有可能存在的。即1+1< 大1,因此,多目标优化就是要解决这个顾此失彼的问题,让一个模型成为多面手。 跟多标签学习的关系:其实本质是相同的,只是多标签学习更多是分类,多目标学习你可以是分类,也可以是回归。
MMOE的loss个数,就跟目标个数是一样的,然后加一起训练。
论文指出:一般的多任务模型结构如上图(a)所示,即对于不同的任务,底层的参数和网络结构是共享的,然后上层经过不同的神经网络得到对应任务的输出,缺点是模型的效果取决于任务的相关性,如果多任务之间关联较小,采用这种结构甚至会出现互相拖后腿的情况。Multi-gate Mixture-of-Experts模型为每个task设置一个gate,使不同的任务和不同的数据可以多样化的使用共享层。每个任务的共享层输出是不同的。
因此本论文提出了基于图(b)的OMOE和图(c)的MMOE两种结构,主要思路是每个任务有一个独立的expert中间网络,类似于“开关”的功能,通过模型学习,不同的任务可以从相同的底层embedding中提取到侧重点不同的特征,而不是完全共享底层,即达到了“各取所需”的效果,有点类似于上面提到的attention网络。
之后每个任务接各自的tower模型,得到logit,再和label一起计算loss,然后多目标的loss直接可以用类似weighted sum的方式结合起来组成总的loss。
(2)这两个方法有什么异同?
我现在既要点击好,又要转化多,还要成交金额高,怎么选?我如果就CTR和CVR两个目标,哪个方法效果更好?
MMOE在ESSM之后出来,本质解决的问题是ESSM解决不了的问题,就是现在这个需求:三个目标怎么学。ESSM是学CTR和CVR的,CTR和CVR是紧相连的,但GMV不太一样,跟商品单价相关,跟买家下单量有关。跟CTR和CVR的相关性有但小不少。
因此,如果目标相差迥异,只能用MMOE,ESSM是专门解决CTR和CVR两个目标联合训练的。这个是他们两个方法的核心不同点。
如果你的目标就是CTR和CVR,那么MMOE训练CVR时,是会出现欠拟合的,因为他没有共享模型参数,因此,这个时候ESSM比MMOE效果好不少。
标签:神经网络 收藏 ica ssm 网络 工业 增强 详解 data
原文地址:https://www.cnblogs.com/eilearn/p/14746522.html