标签:中间件 了解 后台 资源调度算法 代名词 span 作业 算法 detail
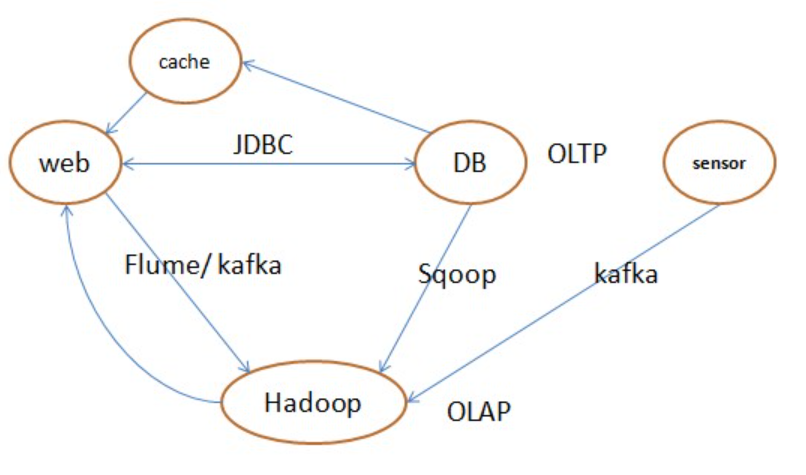
很多的场景都是如上的,有web(包括无线、以前CS的模式、现在的BS模式等)、DB、cache、数据分析我就用了Hadoop了(代名词,或者泛指数据仓库了),另外就是一些传感器之类的,数据通道(有的简单如:jdbc等,有的比较复杂,保序不丢等),其中也简单列了一些中间件的软件。这张图组成了一家公司的基本架构形式,其中每个点都是一个领域。每个点、每条边、有成千上万的同学在奉献。其中DB、Hadoop一般沉淀了数据,包含了大部分的计算。
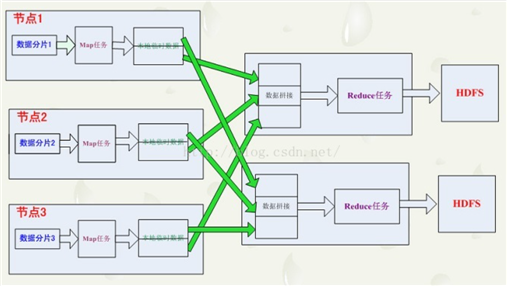
首先了解一下Mapreduce,它最本质的两个过程就是Map和Reduce,Map的应用在于我们需要数据一对一的元素的映射转换,比如说进行截取,进行过滤,或者任何的转换操作,这些一对一的元素转换就称作是Map;Reduce主要就是元素的聚合,就是多个元素对一个元素的聚合,比如求Sum等,这就是Reduce。
Mapreduce是Hadoop1.0的核心,Spark出现慢慢替代Mapreduce。那么为什么Mapreduce还在被使用呢?因为有很多现有的应用还依赖于它,它不是一个独立的存在,已经成为其他生态不可替代的部分,比如pig,hive等。
尽管MapReduce极大的简化了大数据分析,但是随着大数据需求和使用模式的扩大,用户的需求也越来越多:
1. 更复杂的多重处理需求(比如迭代计算, ML, Graph);
2. 低延迟的交互式查询需求(比如ad-hoc query)
而MapReduce计算模型的架构导致上述两类应用先天缓慢,用户迫切需要一种更快的计算模型,来补充MapReduce的先天不足。
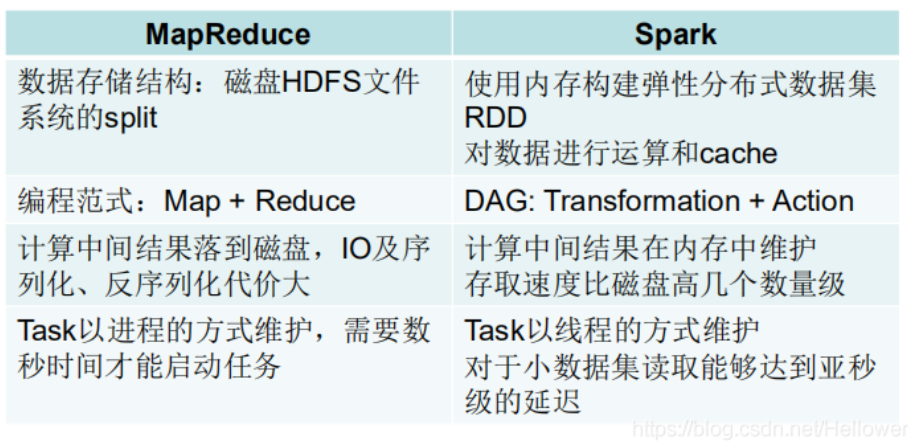
Spark的出现就弥补了这些不足,我们来了解一些Spark的优势:
1.每一个作业独立调度,可以把所有的作业做一个图进行调度,各个作业之间相互依赖,在调度过程中一起调度,速度快。
2.所有过程都基于内存,所以通常也将Spark称作是基于内存的迭代式运算框架。
3.spark提供了更丰富的算子,让操作更方便。
4.更容易的API:支持Python,Scala和Java
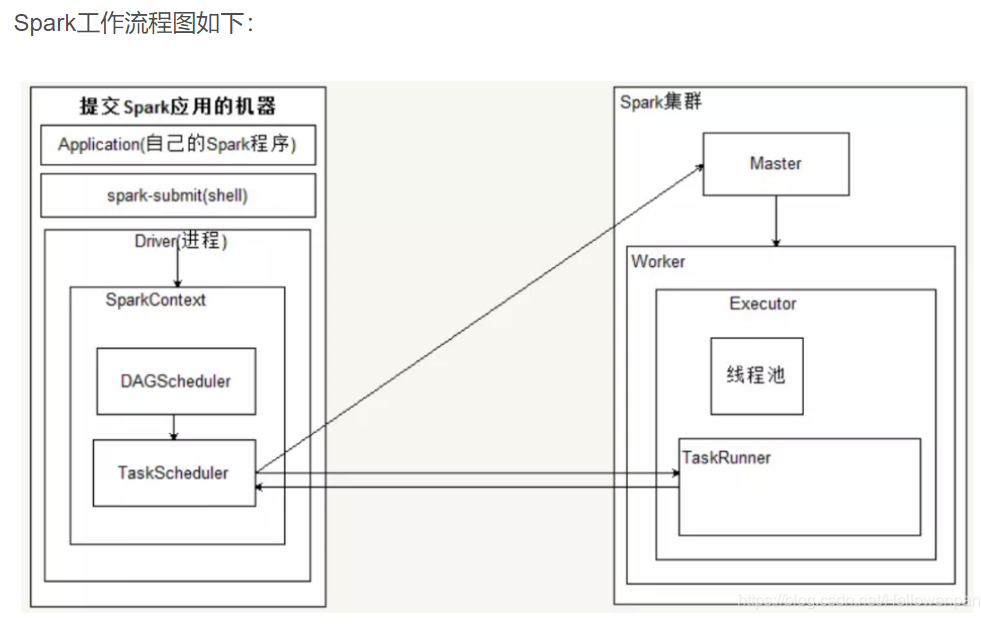
spark-submit 提交了应用程序的时候,提交spark应用的机器会通过反射的方式,创建和构造一个Driver进程,Driver进程执行Application程序,
Driver根据sparkConf中的配置初始化SparkContext,在SparkContext初始化的过程中会启动DAGScheduler和taskScheduler
taskSheduler通过后台进程,向Master注册Application,Master接到了Application的注册请求之后,会使用自己的资源调度算法,在spark集群的worker上,通知worker为application启动多个Executor。
Executor会向taskScheduler反向注册。
Driver完成SparkContext初始化
application程序执行到Action时,就会创建Job。并且由DAGScheduler将Job划分多个Stage,每个Stage 由TaskSet 组成
DAGScheduler将TaskSet提交给taskScheduler
taskScheduler把TaskSet中的task依次提交给Executor
Executor在接收到task之后,会使用taskRunner来封装task(TaskRuner主要将我们编写程序,也就是我们编写的算子和函数进行拷贝和反序列化),然后,从Executor的线程池中取出一个线程来执行task。就这样Spark的每个Stage被作为TaskSet提交给Executor执行,每个Task对应一个RDD的partition,执行我们的定义的算子和函数。直到所有操作执行完为止。
原文链接:https://blog.csdn.net/dashujuedu/article/details/53487199;https://www.sohu.com/a/315363622_120104204;
https://blog.csdn.net/Hellowenpan/article/details/85010852?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-12.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-12.control
标签:中间件 了解 后台 资源调度算法 代名词 span 作业 算法 detail
原文地址:https://www.cnblogs.com/-X-peng/p/14768048.html