标签:对象 是否一致 receive path 单元 堆排 parse 方差 hash
本单元的重点在于理解规格描述,并在其基础上采用最优的解法尽可能地提高程序的效率,因此本文将从以下四个方面进行总结。
设计策略(思路分析)—— 问题1
容器选择以及性能问题(具体实现)—— 问题3&4
优化结果 —— 问题5
基于JML规格来设计测试的方法和策略 —— 问题2
由于三次作业的框架基本一致,因此选取了第三次作业最终的架构。
本单元作业主要分为两部分:异常类包与社交网络实现的包,其中社交网络实现过程中应该根据JML描述在适当的时候抛出异常。
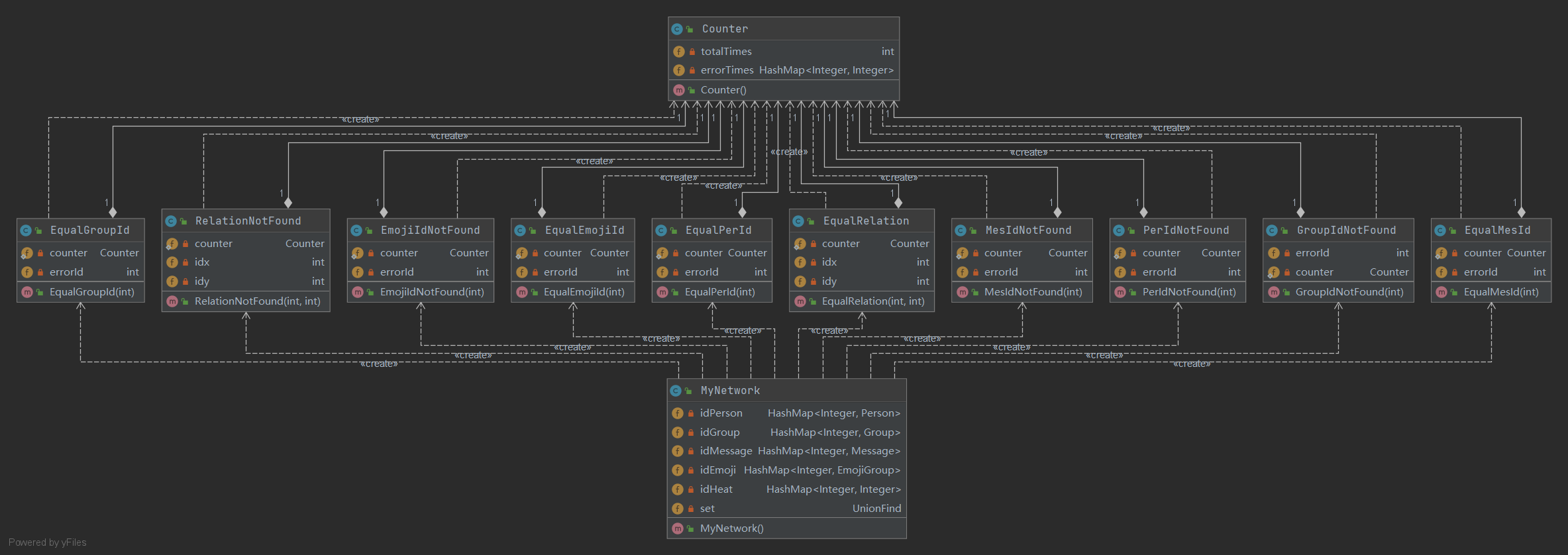
下图为异常类的结构,三次作业每次增加一部分新出现的异常,但是总体实现方法一致,即自行构建异常类,实现print方法,在MyNetwork类中抛出。在实现过程中,为了实现记录异常发生次数的功能,每个异常类皆拥有一个静态Counter类成员,记录了该类异常发生的次数,以及每个id引起该异常的次数。
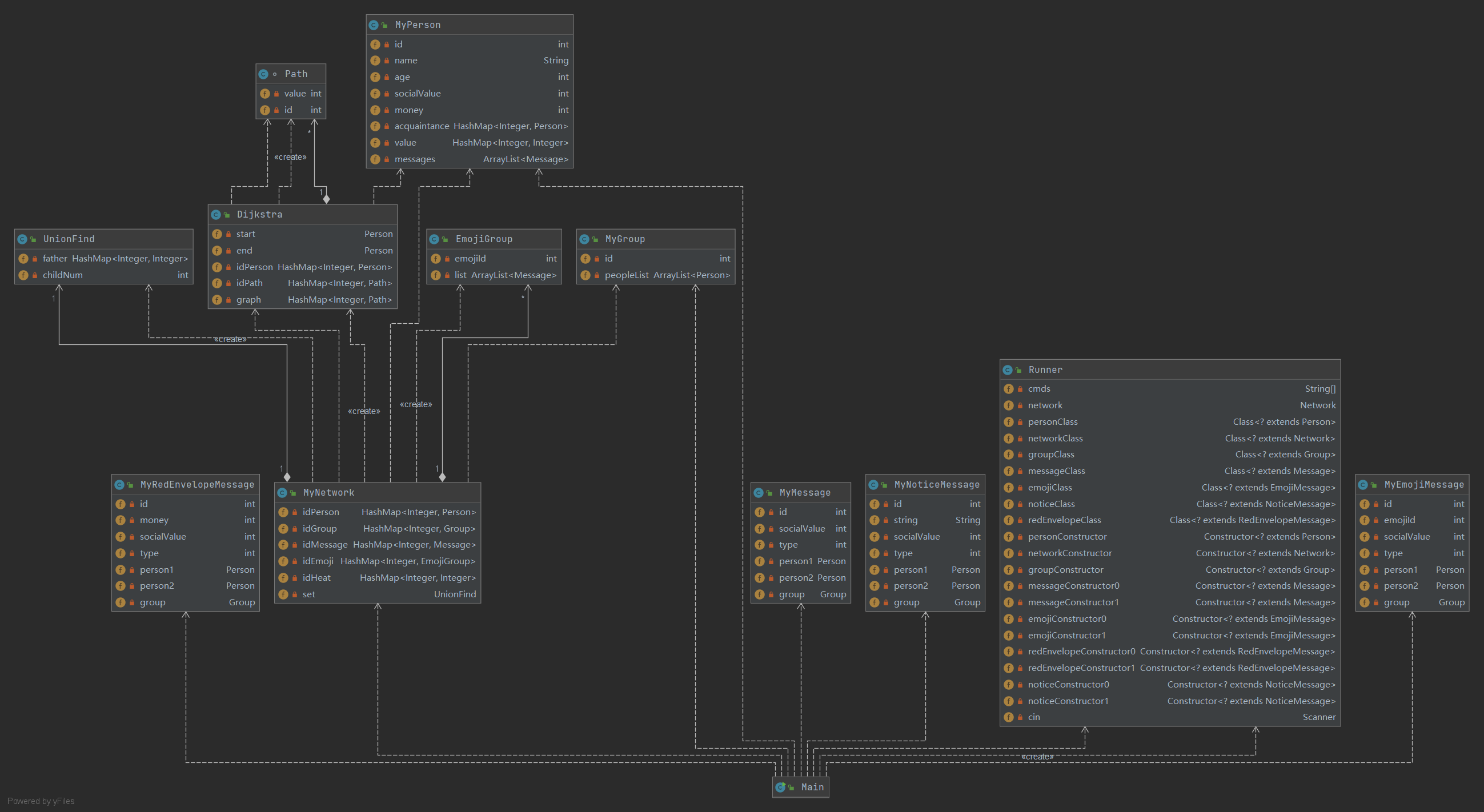
下图为社交网络的实现,主要有三部分内容:Person类、NetWork类以及Message类。Message类又衍生出NoticeMessage、RedEnvelopeMessage与EmojiMessage。
整体来说,Network中记录了社交网络中的人与消息,Person类记录与之相连的其他Person,而Message类在Person之间发送,发送后将从网络中去除。下面将从三个数据管理类的角度来阐述整个社交网络的管理。
Person-Relation是整个单元作业的基础,也是后续进行各类查询与计算的基础。在实现第一次作业的过程中,由于需要查询person之间是否连通,以及需要求解整个社交网络中连通块的数目,我维护了一个树状结构的关系图来实现并查集。UnionFind类中包含了存储所有父节点的一个HashMap,以及子图数量childNum。
通过findRoot方法可以确定两个人是否有公共根节点,即是否连通;而询问连通块数量时,返回childNum即可。
Group是包含人物的集合,也是第二次作业的重点,其实现相对简单,只需包括人物即可,同时提供了计算年龄均值,方差以及value均值等的方法。为了提高效率,Group内维护了ageMean、ageVar、valSum 分别记录当前组内的年龄均值、年龄方差、关系value总和。
由于第三次作业新增了更加细化种类的message,其中EmojiMessage具有独特的EmojiId,当删除EmojiId时,需要连带删除其对应的所有EmojiMessage,为了提升效率,减少遍历,设计了EmojiGroup类用于管理EmojiMessage数据。
该类动态管理属于同一EmojiId的Message,当新增message时需要判断其类型及是否需要加入EmojiGroup,而当发送消息时,需要将已发送消息从此EmojiGroup中去除。当我们需要调用deleteColdEmoji方法时,就可以获取EmojiGroup,进而删除其中对应的消息。
在三次作业中我主要使用了HashMap和ArrayList两种容器。这两类容器都可以动态扩展或者删除,适用于本单元对于数据管理的要求。
HashMap:使用场景为需要存储具有id的数据,且经常需要进行单个数据索引。这种场景下使用HashMap进行查找的速度会比ArrayList快很多。例如在NetWork中,JML使用的是数组存储peron和message,这里我使用的都是HashMap,将id与person或message对应起来,这样可以大幅减少查找时间。
ArrayList: 使用场景为当前只需存储数据本身,且使用时必须遍历或者获取特定位置的数据(如getReceivedMessage需要获取栈中前四个消息)。这种场景下,ArrayList维护特定的结构比HashMap更加方便。
HashMap的get与containsKey
HashMap中get与containskey方法实现方式其实是相同的,都是调用getNode方法,因此先用containsKey判断有无此元素,再进行索引是没有必要的,直接使用get方法即可,判断其是否为null。
public V get(Object key)
{
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
public boolean containsKey(Object key)
{
return getNode(hash(key), key) != null;
}
HashMap遍历
在某些情况下我们需要对HashMap进行遍历,此时有四种方案:
for each entrySet
for iterator entrySet
for each keySet
for entrySet=entrySet()
除了遍历keySet再get之外,另外三种复杂度相近,在本单元作业中,我主要采用的是迭代器遍历的方法。
PriorityQueue
在Dijkstra算法中使用了第三种容器优先队列,其内部基于堆排序,可以自定义compareTo方法来实现想要的排序。
本单元作业相对于CPU使用时间来说,内存较为充足,因此大量采用了空间换时间的做法。
第一次作业主要为社交网络基础框架的实现与优化,如上文所示,采用了并查集的方法来管理人物间的关系。
并查集在每次新增人物时加入节点,此时新加入的节点为孤立节点。
public void addNode(int id) {
father.put(id, id);
childNum++;
}
当新增关系后,判断二者的根节点是否一致,若不一致则将二者的根节点相连,在此树状关系中Person间的Relation不是很重要,关注的点主要在于它们是否处于一个连通块中。
public void addRelation(int idx, int idy) {
int root1 = findRoot(idx);
int root2 = findRoot(idy);
if (root1 != root2) {
father.put(root2, root1);
childNum--;
}
}
而在findRoot方法中,每次寻找当前树的根节点时,都将子节点直接连接到根节点上,以便加快下一次的寻找速度。
public int findRoot(int idLeaf) {
if (father.get(idLeaf) == idLeaf) {
return idLeaf;
}
else {
int temp = findRoot(father.get(idLeaf));
father.put(idLeaf, temp);
return temp;
}
}
第二次作业主要在新增了Group类管理person,为了减少Group中计算年龄均值与方差以及value和的次数,设置了update函数,在每次新增人物或者删除人物时设置标记,在下次询问这些值时调用update更新,来维护ageMean, ageVar, valSum(但是最后第三次作业强测data4还是超时了)。
public void update() {
int result = 0;
int size = peopleList.size();
if (size == 0) {
ageMean = 0;
ageVar = 0;
valSum = 0;
return;
}
for (int i = 0; i < size; i++) {
result += peopleList.get(i).getAge();
}
ageMean = result / size;
result = 0;
for (int i = 0; i < size; i++) {
result += ((peopleList.get(i).getAge() - ageMean) *
(peopleList.get(i).getAge() - ageMean));
}
ageVar = result / size;
result = 0;
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
if (peopleList.get(i).isLinked(peopleList.get(j))) {
result += peopleList.get(i).queryValue(peopleList.get(j));
}
}
}
valSum = result;
}
第三次作业主要新增了不同种类的message,其中涉及EmojiMessage的管理最为复杂,因此我额外增加了一个EmojiGroup类对相同EmojiId的message进行管理。如上文所述,其功能较为简单,只需要维护相同EmojiId的链表。
在deleteColdEmoji时,可以减少遍历中查找的次数。
public int deleteColdEmoji(int limit) {
ArrayList<Integer> removedId = new ArrayList<>();
ArrayList<Message> removedMes;
//遍历确定要去除的EmojiId
Iterator iter = idHeat.entrySet().iterator();
while (iter.hasNext()) {
HashMap.Entry entry = (HashMap.Entry) iter.next();
Object key = entry.getKey();
int temp = Integer.parseInt(key.toString());
if (idHeat.get(temp) < limit) {
removedId.add(temp);
}
}
//获取要删除的EmojiId对应着的Message,同时删除Emoji列表中的id
for (int i = 0; i < removedId.size(); i++) {
removedMes = idEmoji.remove(removedId.get(i)).getList();
//从message和heat列表中删除这些message
for (int j = 0; j < removedMes.size(); j++) {
idMessage.remove(removedMes.get(j).getId());
}
idHeat.remove(removedId.get(i));
}
return idEmoji.size();
}
除了管理EmojiId,本次作业另一个难点在于sim,此方法需要找到message发送者和接收者间的最短value距离,两点最短路径算法中,Dijkstra算法最为常见,但是其时间复杂度为O(n^2),因此采用堆优化的Dijkstra算法,其时间复杂度为O(mlogn)。
(关于这一点其实我看到了一篇文章,在稠密图下堆优化的Dijkstra算法复杂度会变为(n2logn),因为堆优化管理的边在稠密图中数量会接近于点数n的平方,大于集合写法管理点的普通Dijkstra算法(此时仍为O(n2))。但是我没有去测试本次作业的图中边密度的大小,盲猜一手边密度不是很大)
采用优先队列进行优化,优先队列中管理的是路径Path类,包含节点id与到此节点的路径长度。Path重写了compareTo方法,进而可以实现最小堆排序。
class Path implements Comparable<Path> {
private int value;
private int id;
@Override
public int compareTo(Path o) {
if (o.getValue() < value) {
return 1;
}
else if (o.value > value) {
return -1;
}
else {
return 0;
}
}
HashMap的使用使得查找与删除的复杂度由O(n)降为O(1)
如上文所示采用了并查集,复杂度从O(n^2)降为O(logn)
同样采用并查集,计算连通块的操作均摊到每次修改并查集的操作中,时间复杂度为O(1)
每次更新的时间复杂度为O(n)
每次更新的时间复杂度为O(n)
每次更新的时间复杂度为O(mn)
加入了EmojiGroup管理数据,时间复杂度由O(mn)变为O(ma),其中a ≤ n
采用了堆优化的Dijkstra算法,时间复杂度为O(mlogn)
本单元作业我主要采用手动构造测试样例,因为基本功能的考察较为直观,因此手动构造测试样例基本可以覆盖大部分功能。例如并查集中的不同关系树合并问题,Dijkstra算法中图模型的构建,我都是手动构造样例去测试。
手动构造的优势在于简单直观,但是问题在于没法完全覆盖所有容易出现问题的地方,且无法进行强度测试,当数据量足够大时程序的性能无法考察到,比如第三次作业strong_data_4就对group的方法进行了高强度测试,导致CPU_TLE。
Junit可以进行单元测试,自动生产测试类,注解功能如下:
| 注解 | 说明 |
|---|---|
| @Test: | 标识一条测试用例。 (A) (expected=XXEception.class) (B) (timeout=xxx) |
| @Ignore: | 忽略的测试用例。 |
| @Before: | 每一个测试方法之前运行。 |
| @After : | 每一个测试方法之后运行。 |
| @BefreClass | 所有测试开始之前运行。 |
| @AfterClass | 所有测试结果之后运行。 |
在测试中可采用各类断言来检查程序的正确性
| 方法 | 说明 |
|---|---|
| assertArrayEquals(expecteds, actuals) | 查看两个数组是否相等。 |
| assertEquals(expected, actual) | 查看两个对象是否相等。类似于字符串比较使用的equals()方法。 |
| assertNotEquals(first, second) | 查看两个对象是否不相等。 |
| assertNull(object) | 查看对象是否为空。 |
| assertNotNull(object) | 查看对象是否不为空。 |
| assertSame(expected, actual) | 查看两个对象的引用是否相等。类似于使用“==”比较两个对象。 |
| assertNotSame(unexpected, actual) | 查看两个对象的引用是否不相等。类似于使用“!=”比较两个对象。 |
| assertTrue(condition) | 查看运行结果是否为true。 |
| assertFalse(condition) | 查看运行结果是否为false。 |
| assertThat(actual, matcher) | 查看实际值是否满足指定的条件。 |
| fail() | 让测试失败。 |
本单元作业的难度相较于前两个单元较为简单,但是对于细节的考察更为注重,由于我们的作业是基于JML描述完成的,所以理解其要求非常重要。在第二次作业时,因为对ageVar和ageMean的计算方式理解错误,导致强测只过了一个点,而在第三次作业中,也因为sim中对于JML描述没有完全实现的问题挂了一些点,在后续的作业中要引以为戒。
标签:对象 是否一致 receive path 单元 堆排 parse 方差 hash
原文地址:https://www.cnblogs.com/buaadxt/p/14826330.html