标签:服务器 收集 形式 通过 数据过滤 方案 mic 适合 serve
要谈ELK的应用,就不得不谈ELK架构。下面介绍几种工程项目中最常用的架构,并讨论四种架构所适合的场景。当然,在实际场景选择架构时,只要能满足当前需求就好,同时现有架构也要有一定的可预见性,为架构的演进预留一定的扩展性。
应用服务器端部署logstash组件,作为日志收集器,然后将Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户也可以使用Kibana对日志查询,并根据数据生成报表。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。建议供学习者和小规模集群使用。
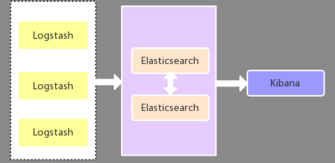
图 1.3?1 ELK架构-简单模式
应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最常用的架构。Logstash将收到的数据分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展。
这种架构使用beats作为日志采集器,Beats满负荷状态所耗系统资源几乎可以忽略不计,但其扩展性和灵活性有很大提高。同时用户可根据需要进行二次开发。
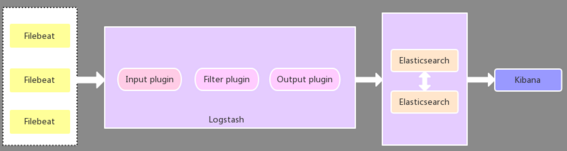
图 1.3?2 ELK架构-改进模式
在第二种架构的基础上引入了Redis缓存队列(还可以是其他消息队列),将Filebeat收集到的数据发送至Redis,然后在通过Logstasth读取Redis中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
这种架构适合于较大集群的解决方案,配置更灵活,扩展性更强,数据吞吐量高。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
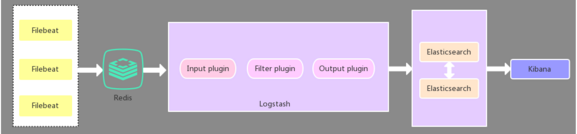
图 1.3?3 ELK架构-强化模式
另外,如果集群规模大,同时业务需求要满足日志数据分析和持久存储,需要使用hadoop、hive等大数据计算环境,还又针对此类业务场景的架构设计,后续完善补充内容。
后话:不管采用上面哪种ELK架构,都包含了其核心组件,即:Logstash、Elasticsearch 和Kibana。当然这三个组件并非不能被替换,只是就性能和功能性而言,这三个组件已经配合的很完美,是密不可分的。各系统运维中究竟该采用哪种架构,可根据现实情况和架构优劣而定。
标签:服务器 收集 形式 通过 数据过滤 方案 mic 适合 serve
原文地址:https://www.cnblogs.com/skyroad/p/14843756.html