标签:format map err should clust mic src des image
1001 ss1 1002 ss2 1003 ss3 1004 ss4 1005 ss5 1006 ss6 1007 ss7 1008 ss8 1009 ss9 1010 ss10 1011 ss11 1012 ss12 1013 ss13 1014 ss14 1015 ss15 1016 ss16
(2)创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by ‘\t‘;
(3)查看表结构
hive (default)> desc formatted stu_buck;
Num Buckets: 4
(4)导入数据到分桶表中
hive (default)> load data local inpath ‘/opt/module/datas/student.txt‘ into table
stu_buck;
(1)先建一个普通的 stu 表
create table stu(id int, name string)
row format delimited fields terminated by ‘\t‘;
(2)向普通的 stu 表中导入数据
load data local inpath ‘/opt/module/datas/student.txt‘ into table stu;
(3)清空 stu_buck 表中数据
truncate table stu_buck;
select * from stu_buck;
(4)导入数据到分桶表,通过子查询的方式
insert into table stu_buck
select id, name from stu;
(6)需要设置一个属性
hive (default)> set hive.enforce.bucketing=true;
hive (default)> set mapreduce.job.reduces=-1;
hive (default)> insert into table stu_buck
select id, name from stu;
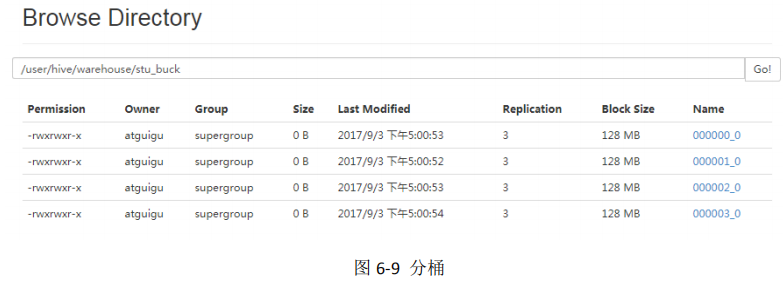
select * from stu_buck;
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
Hive基础(三十九):Hive DML (三) 分桶及抽样查询/其他常用查询函数
标签:format map err should clust mic src des image
原文地址:https://www.cnblogs.com/qiu-hua/p/14877910.html