准备:
1. 规划3个集群节点:
hosts主机都已经配置好映射,映射主机名分别为master,slave1,slave2,
且已经进行ssh免密配置,确保端口互通,防火墙关闭
2. 先安装好scala(参考:https://www.cnblogs.com/sea520/p/13518158.html)
一. 下载
spark安装包下载地址:https://archive.apache.org/dist/spark/spark-2.4.6/
将下载的spark-2.4.6-bin-hadoop2.7.tgz上传到master机器目录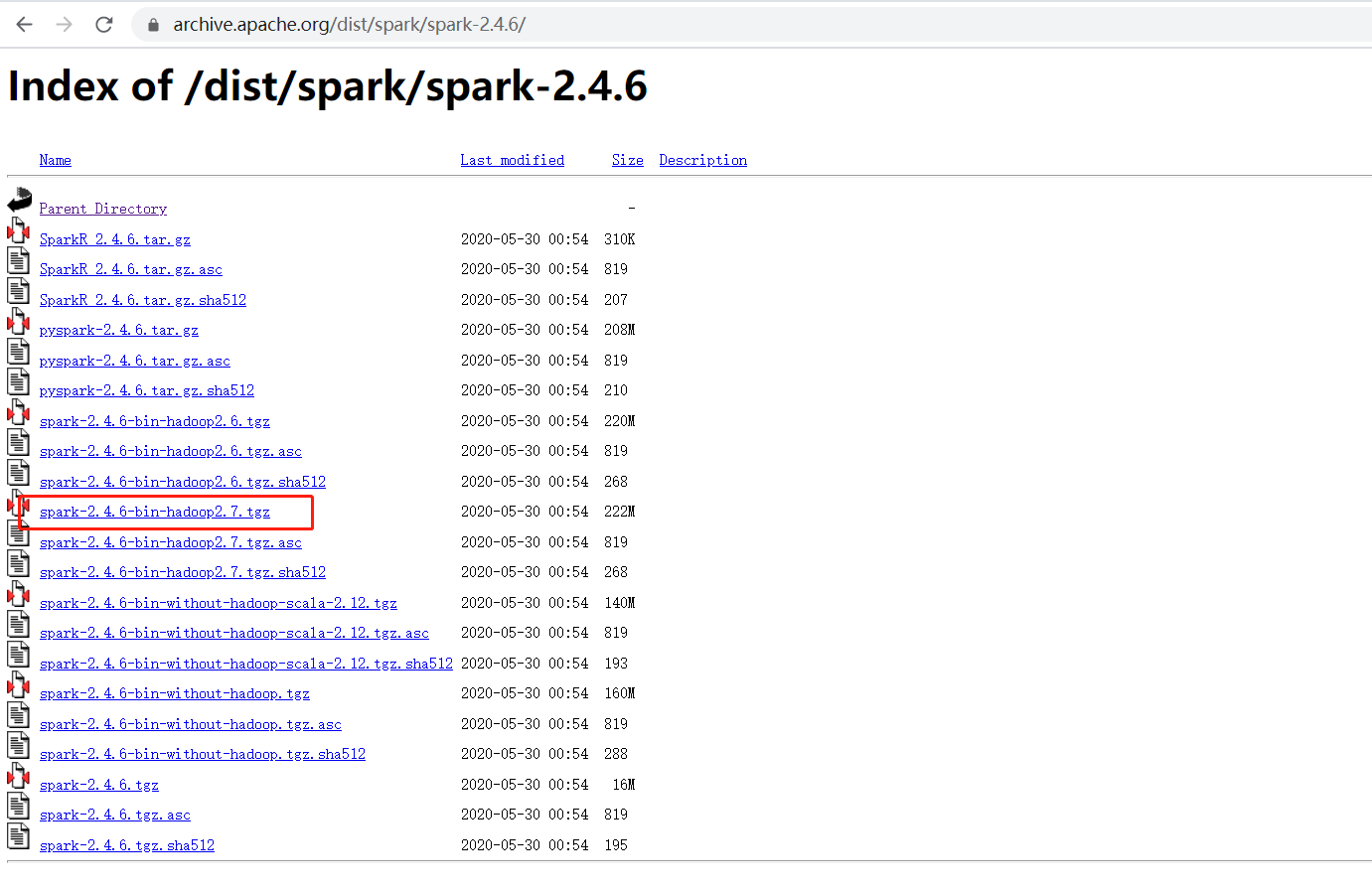
(参考:
开发源码与编译下载 https://github.com/apache/spark/tree/branch-2.4
官方的下载地址已经无法选择版本下载:http://spark.apache.org/downloads.html)
二. 安装
1.解压 (解压后主目录:/opt/soft/spark-2.4.6-bin-hadoop2.7)
tar -zxvf /opt/soft/download_jars/spark-2.4.6-bin-hadoop2.7.tgz -C /opt/soft/
2. 配置环境变量
3. 配置环境变量
3.1 打开 vim /etc/profile添加以下配置
# spark home
export SPARK_HOME=/opt/soft/spark-2.4.6-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
3.2 让环境变量立即生效
source /etc/profile
4. 修改Spark配置文件
spark配置文件模版在: cd ${SPARK_HOME}/conf/
主要修改两个配置文件:spark-env.sh和slaves
4.1 spark-env.sh修改:
# 复制模版
cp spark-env.sh.template spark-env.sh
# 添加配置 (请修改成你自己的各种目录环境,注意最后一个 HADOOP_CONF_DIR=你的hadoop主目录/etc/hadoop ,/etc/hadoop要保留哦)
vim spark-env.sh
export SCALA_HOME=/opt/soft/scala-2.13.3
export JAVA_HOME=/opt/soft/jdk1.8.0_261
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/soft/hadoop-3.1.2/etc/hadoop
4.2 slaves修改
cp slaves.template slaves
vim slaves
# localhost
slave1
slave2
5. node节点分发(如果在内网,用内网IP比主机名快很多,主机名是映射的公网太慢)
scp -r /opt/soft/spark-2.4.6-bin-hadoop2.7 hadoop@172.17.0.5:/opt/soft/
scp -r /opt/soft/spark-2.4.6-bin-hadoop2.7 hadoop@172.17.0.13:/opt/soft/
6. 其他各node节点(slave1,slave2)分别配置环境变量与刷新环境变量(执行3.1,3.2两个步骤),
刷新profile文件使配置生效,验证安装是否OK
7.启动Spark集群
7.1启动前确定Hadoop集群已经启动。
7.2启动命令:
/opt/soft/spark-2.4.6-bin-hadoop2.7/sbin/start-all.sh
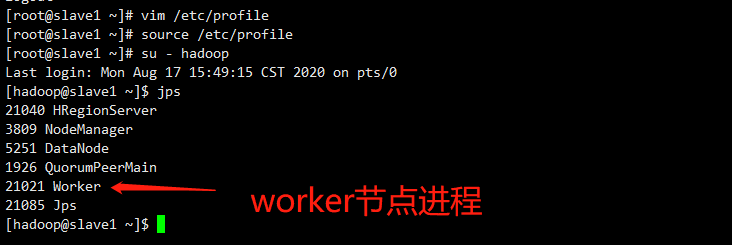
master节点进程:

worker节点进程:
====================================================================================================
小小尝试: 进行 Spark集群测试,运行第一个spark任务WorldCount
====================================================================================================
8. Spark集群测试--运行第一个spark任务WorldCount
8.1 准备一个测试文件,摘录一段百度词条中对spark的介绍内容。
vim spark-test.txt
在spark-test.txt中输入以下文字:
hi,sea
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。---sea
8.2 将测试文件上传到hdfs中
hadoop fs -put spark-test.txt /sea
8.3 启动spark-shell:
spark-shell
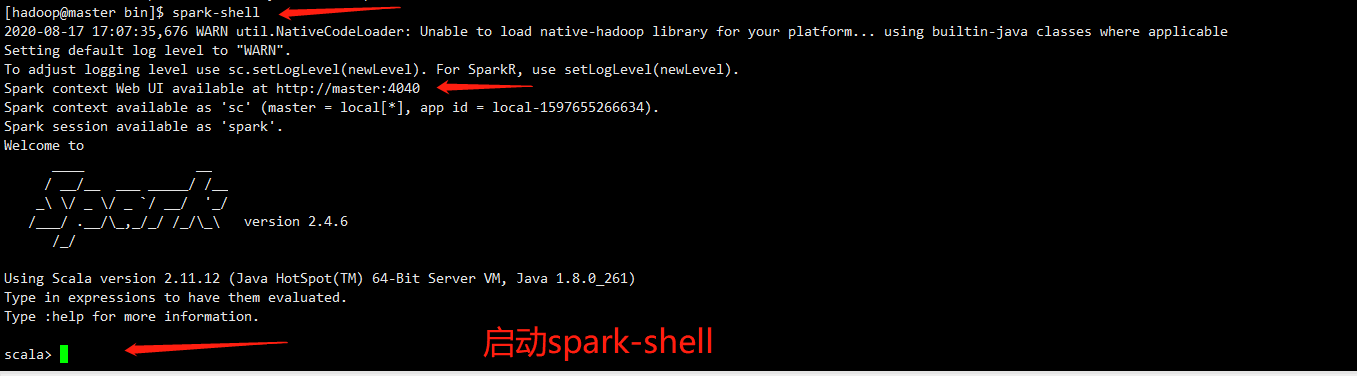
启动后注意观察这几行输出:
Spark context Web UI available at http://master:4040
Spark context available as ‘sc‘ (master = local[*], app id = local-1597655266634).
Spark session available as ‘spark‘.
启动后可以通过浏览器访问http://master:4040/查看Jobs,Stages,Storage,Environment,Executors等情况
8.3 输入测试代码
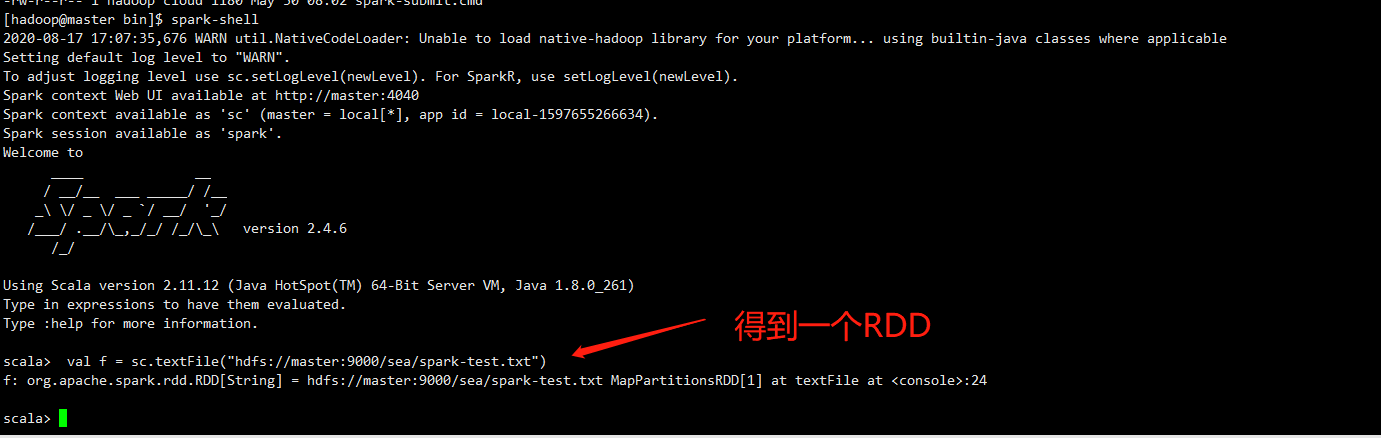
val f = sc.textFile("hdfs://master:9000/sea/spark-test.txt")
回车
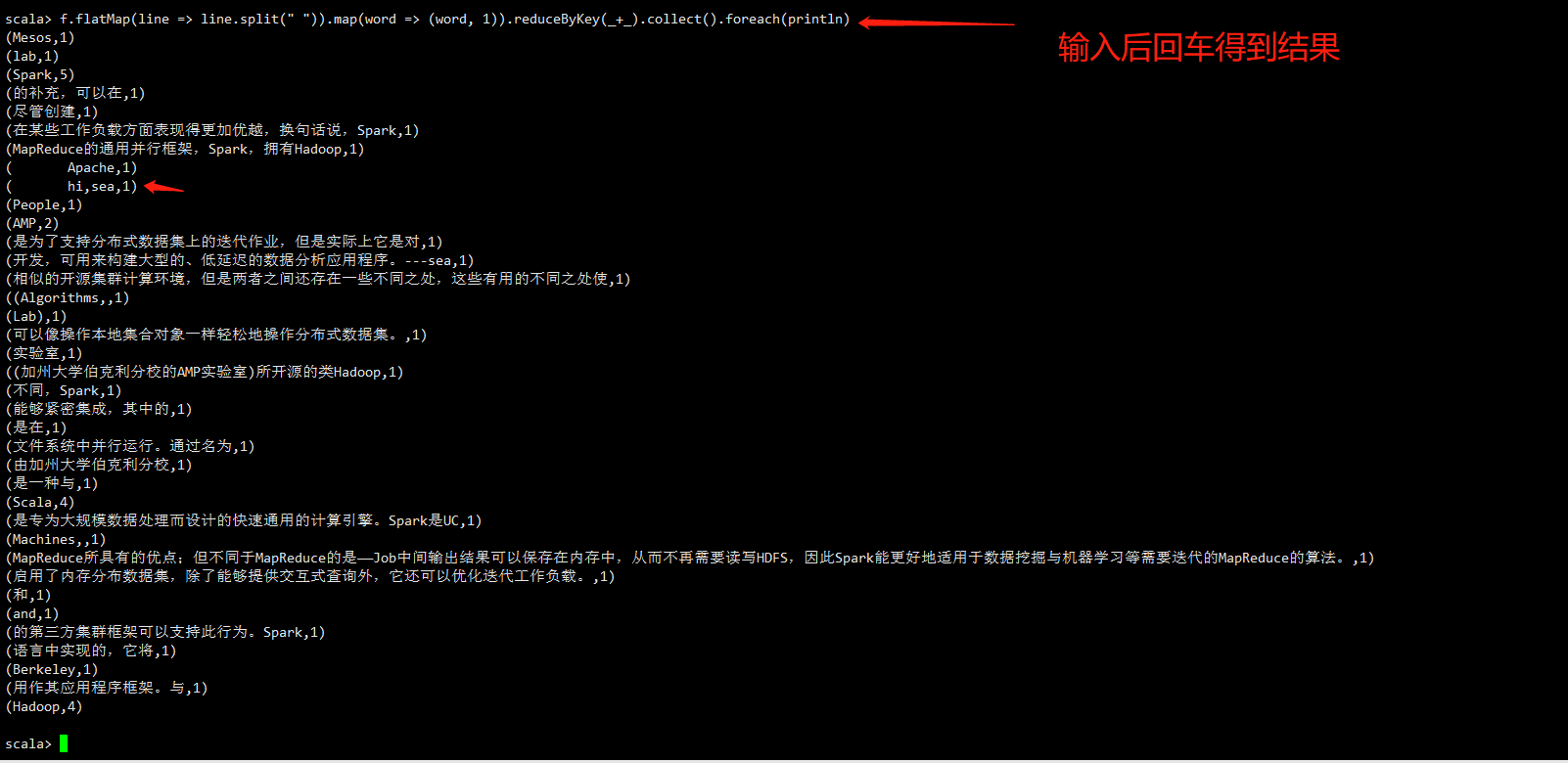
f.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_).collect().foreach(println)
回车,观察结果
到这里安装与第一个例子都搞定了,其他的可以根据实际需要进行配置与调优,如配置yarn调度,spark工作内存等
标签:配置环境变量 规划 数据挖掘 body 实验室 内网 slave 下载 gpo
原文地址:https://www.cnblogs.com/javalinux/p/14902381.html