标签:权限设置 load row 大于 最大 iss nts manage 结构
你将编写一个内存管理代码。主要分为两大部分。分别对物理内存和虚拟内存的管理。
操作系统必须跟踪哪部分物理内存是被使用的以及哪部分物理内存是空闲的。你需要在切入到虚拟内存之前完成这一操作,因为当使用虚拟内存的时候我们需要页表来进行管理,而你需要为页表分配物理内存。
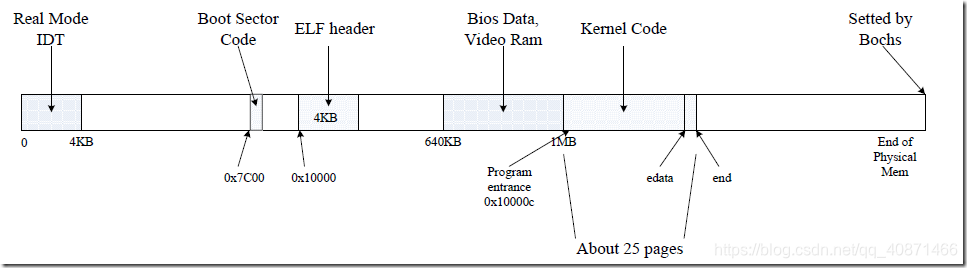
下面的图来自于[https://blog.csdn.net/qq_40871466/article/details/103922416]
你需要实现 kern/pmap.c的下列函数
boot_alloc()
mem_init() (only up to the call to `check_page_free_list(1)`)
page_init()
page_alloc()
page_free()
check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes.
在lab1我们知道了pc的启动过程。这里是在内核执行的init.c中先调用了mem_init。
根据我的调试输出(printf)我发现.bss的地址是 0xf01156a0这个地址在虚拟地址0xf0000000之上。我们知道内核的虚拟地址是在0xf0000000为起点的。随后是内核的代码段+数据段然后就是.bss所以这里bss大于内核虚拟地址起始位置是合理的.
boot_alloc就是在.bss之上分配制定大小为n的区域。注意这里都是在虚拟内存地址下进行的操作
nextfree的地址。也就是把.bss向上取整(为了都符合一页一页的存储形式。分页管理)static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
if (!nextfree) {
extern char end[];
cprintf("end is %08x\n",end);
nextfree = ROUNDUP((char *) end, PGSIZE);
}
cprintf("nextfree is %08x\n",nextfree);
// Allocate a chunk large enough to hold ‘n‘ bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
//
// LAB 2: Your code here.
if (n == 0) {
return nextfree;
}
//allocate
result = nextfree;
nextfree = ROUNDUP((char *)(nextfree + n), PGSIZE);
return result;
}
mem_init在mem_init中我们会调用两次boot_alloc。第一次为了创建页目录。第二次则为了创建所有的物理页表。分别为它们分配内存然后memset成0。
// create initial page directory.
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
//////////////////////////////////////////////////////////////////////
// Recursively insert PD in itself as a page table, to form
// a virtual page table at virtual address UVPT.
// (For now, you don‘t have understand the greater purpose of the
// following line.)
// Permissions: kernel R, user R
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
cprintf("Page nubmer %d\n",npages);
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages ‘struct PageInfo‘s and store it in ‘pages‘.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. ‘npages‘ is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
// all 32768 number pages
pages = (struct PageInfo *) boot_alloc(sizeof(struct PageInfo) * npages);
memset(pages, 0, sizeof(struct PageInfo) * npages);
page_alloc这里给了我们示例代码。不过这里把所有的pages都初始化了成了0和可用。这显然是不合理的
根据下图和实验中给的提示。base_memory(也就是 1mb + extended_memoy)这一段 。的low memory是可以被分配成use的
但是注意最下面的一个page不可以(实验中有提到保存实模式的一些信息)

第二就是extended memory里会存有内核的信息。我们要找到内核的结束位置,然后给剩余部分进行初始化
这里就可以简单利用boot_alloc(0)。因为这个会返回内核的结束位置对应的虚拟地址。
但是我们要找的是这个虚拟地址定于的物理地址在哪个page中。也就是要找到它在pages数组中的标号。
这里实验给我们提供了一个宏定义page2kva即可获得它对应的物理地址。然后除页表大小就可以获得对应的标号
好了代码已经呼之欲出了
cprintf("npages_basemem is %d\n",npages_basemem);
cprintf("pages addr is %0x8 \n", pages);
size_t i;
//all low memeory is free expect 0 page
for (i = 1; i < npages_basemem; i++) {
cprintf("pages addr is %0x8 \n", pages[i]);
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
i = PADDR(boot_alloc(0)) / PGSIZE;
for (; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
page_free这个就比较简单了。只需要简单的把要释放的页加入到free_page_list中就好。
根据实验中给出的提示,可以很容易的写出来
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if (pp->pp_ref || pp->pp_link) {
panic("no shoule page free");
}
//head insert
pp -> pp_link = page_free_list;
page_free_list = pp;
}
跳过中间的一些废话,直接开始exercise4。这里要求我们编写代码来管理页面表。要插入和删除linear-to-physical(其实就是虚拟地址和物理地址之间的mappings,并按需分配页。
这个是JOS所用的32位虚拟地址的分布

下面就是虚拟地址的翻译过程。这个学过os的应该非常熟悉了吧。这里的page_dir和page_table其实就是一个二级页表。的多级索引非常简单。
整体过程就是我们先通过CR3寄存器找到PAGE_DIR所在的位置,然后通过虚拟地址的前10位在PAGE_DIR中获取到下一级页表,也就是PAGE_TABLE的地址。随后通过虚拟地址的12-21这10位去找到对应的PAGE_FRAME的地址。从里面获取到ppa的地址结合OFFSET就可以得到最终的物理地址了。
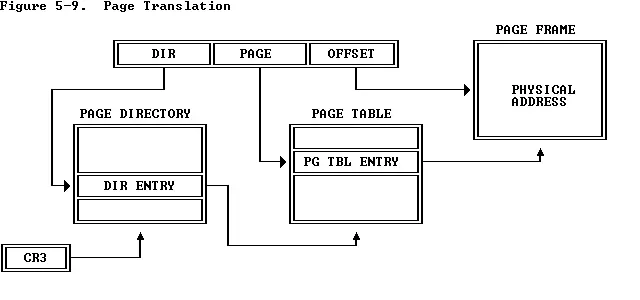
好了搞清楚大概逻辑之后,下面开始完成第二部分的代码
这个代码是后面四个代码的基础,因此一定要小心认真,这里的意思就是说给你pgdir的地址。和虚拟地址va你要返回一个指向pte的指针。pte就是页表条目在最后一层页表对应位置处。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
uintptr_t dir = PDX(va); //表示对应的page_dir索引
uintptr_t page = PTX(va); // 表示对应的page_table索引
uintptr_t offset = PGOFF(va); // 表示在page中对应的页内偏移
pde_t dir_entry = pgdir[dir]; // 首先要判断这个虚拟地址是否有映射
if (!(dir_entry & PTE_P)) {
if (create) {
// allocate
struct PageInfo *newPage = page_alloc(ALLOC_ZERO);
if (newPage == NULL) {
// allocation failed
return NULL;
}
newPage->pp_ref++;
pgdir[dir] = (pde_t)page2pa(newPage)|PTE_P|PTE_U|PTE_W;
} else {
return NULL;
}
}
//
pte_t *ptab = (pte_t *)KADDR(PTE_ADDR(pgdir[dir]));
return &ptab[page];
}
这个函数的实现就比较简单了。要求是把虚拟地址[va, va+size)映射到物理地址[pa, pa+size],使用权限位为perm|PTE_P,只是在UTOP上方做静态映射,所以不能修改pp_ref字段.
基本上就是通过上面实现的pgdir_walk函数找到给定虚拟地址对应的pte。然后修改pte条目即可
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
uintptr_t start = 0;
for ( ; start < size; start += PGSIZE, va += PGSIZE, pa += PGSIZE) {
pte_t *pte = pgdir_walk(pgdir,(void *) va, 1);
*pte = pa | perm | PTE_P;
}
}
返回一个虚拟地址va映射的页面。如果pte_store不是0,那么将对应的页表项地址存到pte_store的地址里(用于结果返回)。如果没有页面映射在va那么返回NULL。提示:使用pgdir_walk和pa2page
struct PageInfo *
pgee_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir,(void *) va, 0);
if (!pte) {
return NULL;
}
if (*pte && !(*pte & PTE_P)) {
return NULL;
}
if (pte_store) {
*pte_store = pte;
}
struct PageInfo* page = pa2page(PTE_ADDR(*pte));
return page;
}
基本上通过给的提示就可以实现这个函数
也是通过提示。移除给定的va对应的映射。
tlb_invalidate和page_decrefvoid
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t * pte;
struct PageInfo *page = page_lookup(pgdir,va,&pte);
if (!page) {
return;
}
*pte = 0;
tlb_invalidate(pgdir,va);
page_decref(page);
}
把物理页pp映射在虚拟地址va,页表项权限设置为perm|PTE_P。
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir,(void *) va, 1);
if (!pte) {
return -E_NO_MEM;
}
pp->pp_ref++;
if (*pte & PTE_P) {
page_remove(pgdir,va);
}
*pte = page2pa(pp) | perm | PTE_P;
return 0;
}
第三部分需要我们补齐mem_init函数
只要跟随提示来完成对于内核部分的一些映射。按照下面这样做就好了
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U);
boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W);
补充完第三部分的代码之后,我们来看一下第三部分的问题
What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
| Entry | Base Virtual Address | Points to (logically): |
|---|---|---|
| 1023 | 0xff000000 | Page table for top 4MB of phys memory |
| 1022 | ? | ? |
| 959 | 0xefc00000 | cpu0‘s kernel stack(0xefff8000),cpu1‘s kernel stack(0xeffe8000) |
| 956 | 0xef000000 | npages of PageInfo(0xef000000) |
| 952 | 0xee000000 | bootstack |
| 2 | 0x00800000 | Program Data & Heap |
| 1 | 0x00400000 | Empty |
| 0 | 0x00000000 | [see next question] |
这个地方要参考一下
memlayout.h就可以写出了其实主要搞清楚几个重要的就可以了
比如0xef000000表示UPAGES
oxefc00000表示内核栈等等
We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel‘s memory? What specific mechanisms protect the kernel memory?
通过把页表项中的 Supervisor/User位置0,那么用户态的代码就不能访问内存中的这个页。
What is the maximum amount of physical memory that this operating system can support? Why?
这个操作系统利用一个大小为4MB的空间也就是UPAGES这一段。来存放所有的页的PageInfo结构体信息,每个结构体的大小为8B,所以一共可以存放512K个PageInfo结构体,所以一共可以出现512K个物理页,每个物理页大小为4KB,自然总的物理内存占2GB。
How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
这个问题是说如果我们现在的物理页达到最大,那么管理这些内存所需要的额外空间开销有多少
首先我们所有的pageinfo需要4mb。然后需要存放页目录表。一共1024个每一个需要4B所以一共4kb
还有存放当前的页表。页表是1024 * 4kb = 4mb
所以一共需要4MB + 4MB + 4KB = 8MB + 4KB
Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
- 是通过下面的代码来跳转到kernbase之上的虚拟地址的
mov $relocated, %eax
jmp *%eax
是因为我们把[0,4mb]和[KernalBASE,KERNALBASR + 4MB]这段的虚拟地址都映射到了0-4MB的物理地址上,因此无论EIP在高位还是在低位都可以运行。必须这样做的原因是,如果只映射高位地址。在我们刚开启分页模式之后就会crash。
因为刚开始我们访问的还是地位地址。是通过jump来跳转到高位》
//TODO
标签:权限设置 load row 大于 最大 iss nts manage 结构
原文地址:https://www.cnblogs.com/JayL-zxl/p/14934546.html