标签:自动化构建 data effective 基于 abi core 情况 neu 系统
本文记录昨天看的两篇文章 Knowledge Vault&MLP 和 TATEC。因为后面还安排了别的学习任务,时间不太多了,而且双线性也不是研究重点,所以只简单记录一下模型要点就好了。
【paper】 Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion
【简介】 本文是谷歌的研究者发表在 KDD 2014 上的工作,提出了一套方法用于自动挖掘知识,并构建成大规模知识库 Knowledge Vault(KV);KV 的构建包括知识提取器、基于图的先验及两者的融合。本来打开这篇文章是为了看 MLP 模型,但 MLP 只是其中的一个组合部分。
本文的主要贡献如下:
KV 包括三部分组成成分:
本文的框架遵循局部封闭世界假说(Local closed world assumption, LCWA)。封闭世界假说是指不存在于 KB 中的事实都被判定为 false。但由于 KB 本身就是不完整的,因此这种假说不合理。因此本文提出一种启发式假说,定义了 \(O(s,p)\),对于给定的候选三元组,按照如下规则打标签:
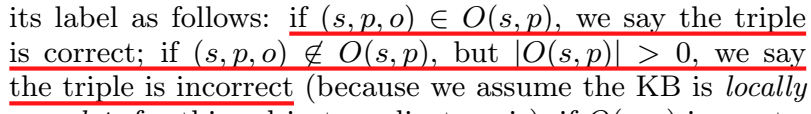
对不同的 web 资源提出了不同的处理方法:
对于自由文本 text documents,首先用 NLP 工具进行命名实体识别、词性标注、共指消解等处理,然后使用远程监督训练关系抽取器,并用 bootstrapping 方式挖掘更多实体对。
对于 HTML trees(DOM),和自由文本的处理方法一样,唯一不同的是从 DOM 树中连接两个实体获取特征而不是从自由文本。
对于 HTML tables,首先进行命名实体链接,然后识别表的每列表示的关系。
人工标注页面(ANO)。只有14个不同属性的子集,三元组的打分由实体链接系统给出。
抽取器融合: 对上面介绍的4种抽取器进行整合,对每个抽取出的三元组分配一个特征向量,并用二分类器计算该特征向量代表的三元组的得分:
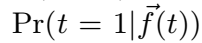
分类器为每个抽取器分配一个权重,且每种属性适配一个单独的分类器,最后进行整合。
介绍了两种对三元组进行打分的先验模型:PRA 和 MLP
PRA 学到的路径可以被视为规则,根据规则做推断,进行链接预测。
将 KB 表示为 3d 矩阵 G,若从 s 到 o 的链接 p 存在,则 \(G(s,p,o)=1\),否则 \(G(s,p,o)=0\)。
三元组成立的概率通过元素点积计算:
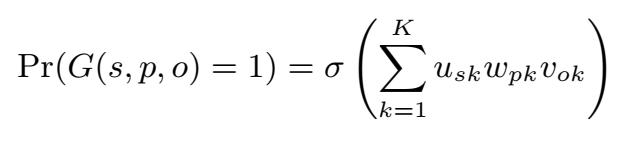
其中,激活函数 \(\sigma\) 为 sigmoid 或 logistic 函数:
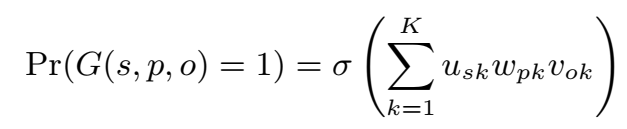
K 约为 60,为隐藏层维度。
还有一种是 NTN 的形式:
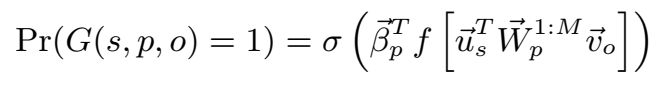
本文使用的 MLP 形式为:
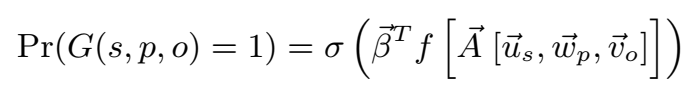
实验发现,两种用于计算先验概率的图模型的效果相差无几,MLP 的 AUC 是 0.882,PRA 的 AUC 是 0.884。
和抽取器融合类似,也对图模型 priors 进行了融合。
对抽取器和 prior 进行融合,对三元组打分的结果:
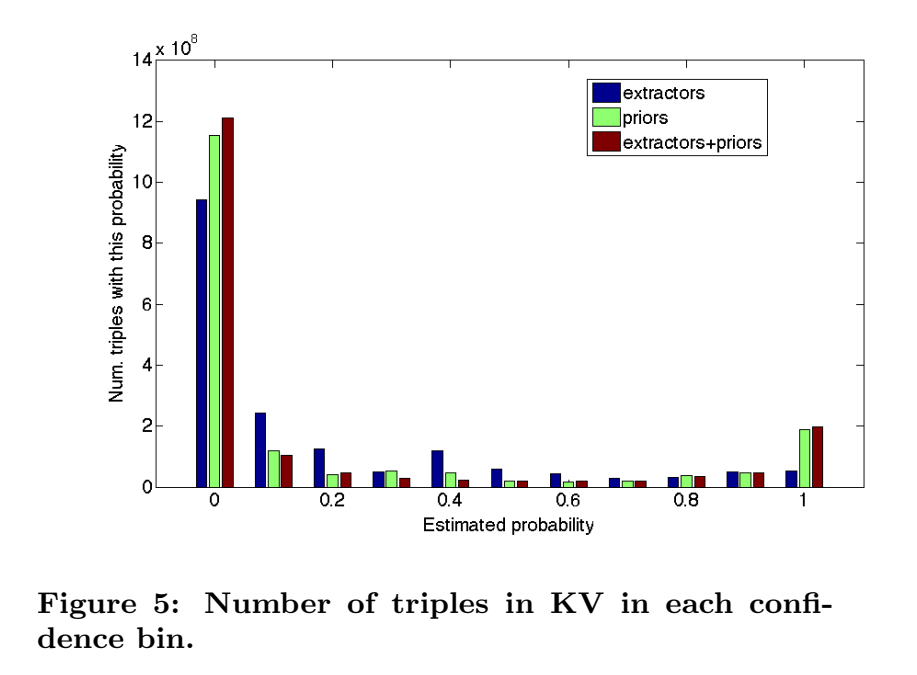
与单使用抽取器相比,融合 priors 和抽取器增加了高置信度事实的数量。
【总结】 本文提出了 Web 规模的概率知识库 Knowledge Vault 的构建过程,将多个抽取器与先验知识打分模型结合,自动化构建知识库。
【paper】 Effective Blending of Two and Three-way Interactions for Modeling Multi-relational Data
【简介】 本文是法国 Antoine Bordes 团队发表在 ECML-PKDD 2014 上的工作,提出了 TATEC(Two and Three-way Embeddings Combination)主要思想是混合二元和三元模型,分别训练然后进行联合微调。
文章提出,之前的模型,要么太复杂导致过拟合,要么太简单导致 capacity 不够,因此本文提出折中的办法,结合 high-capacity模型(三元交互)和 简单模型(二元交互),分别预训练并进行联合微调。
3-way interaction 的 large capacity 会导致过拟合,解决方法有二,一是加正则项,但会削弱模型表现力;而是使用二元交互,对于三元组 \((h,r,t)\),使用其二元交互项 \((h,t)\)、\((t,l)\) 和 \((h,l)\)。文中说 TransE 属于二元交互模型。但是基于二元交互的方法是有限的,不能表示实体间所有类型的关系。
因此本文提出了一个 latent factor model,结合了 well-controlled 2-way 交互和 high-capacity 3-way 交互。这是一个之前模型的泛化,并且不像 LFM 和 NTN,在二元和三元交互的 component 之间不进行参数共享。
三元组的整体打分函数为二元交互和三元交互两部分得分之和:
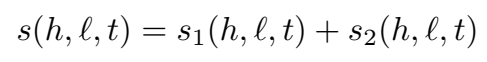
bigram 二元交互项:
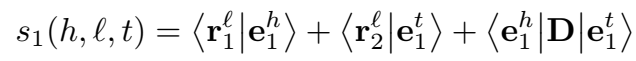
其中,\(r_1^l\) 和 \(r_2^l\) 是与关系有关的用于头尾实体投影的两个向量,\(D\) 是对角矩阵,\(<.|.>\) 是普通的点积。
TransE 可以被视为 \(r_1^l = -r_2^l\) 的特殊情况。
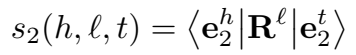
其中,\(R^l\) 是维度为 \((d_1,d_2)\) 的矩阵。
文中提到,三元交互模型基本上可以表示实体间的任何交互。这里文章强调了两点,一是二元和三元两部分间没有参数共享,而是没有用于正则化的全局约束项。
负采样:
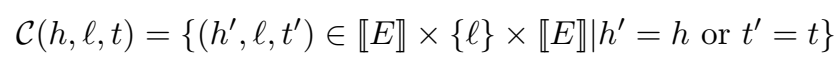
loss function:
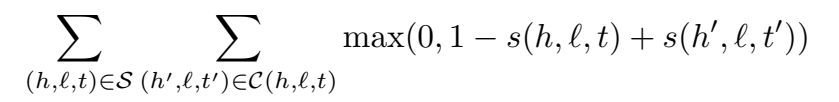
前面提到说没有正则化,但是训的时候也加了 L2 范数约束。
训练时首先分别训练 bigram term 和 trigram term,然后用学到的权重初始化 full score 并进行微调,用 SGD 训练 full model。
后面用了整整一章介绍模型的 motivation,并类比推荐系统协同过滤中“用户-物品”矩阵的各项。
链接预测的结果:
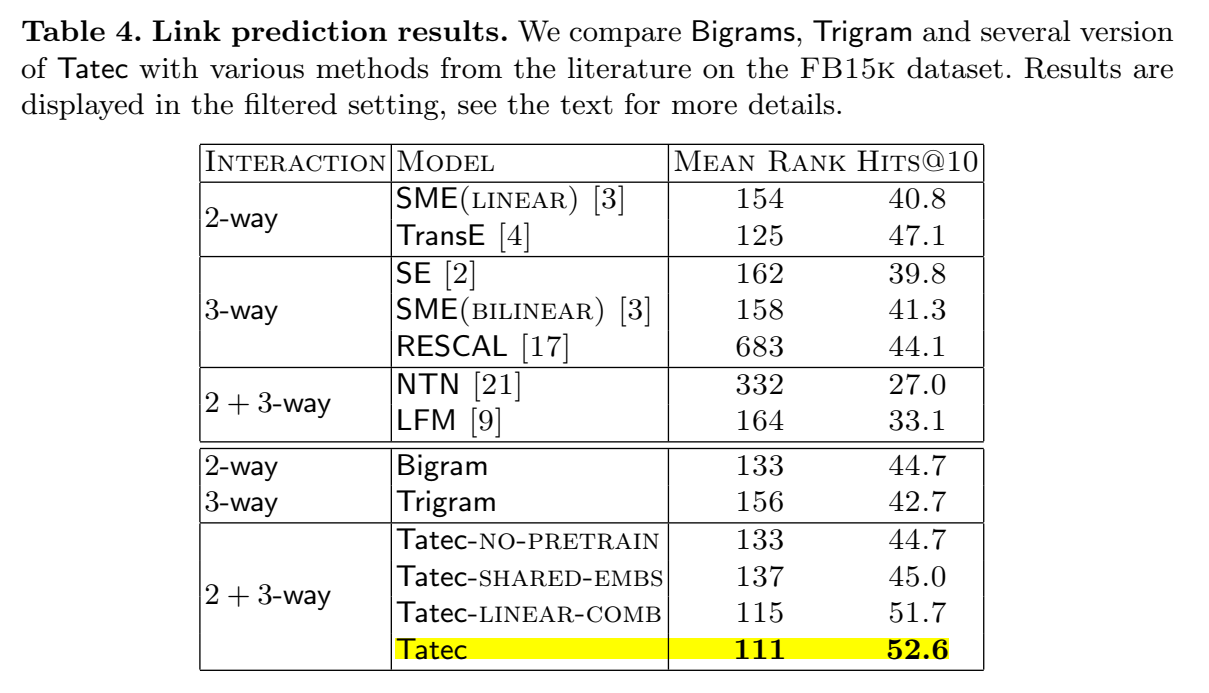
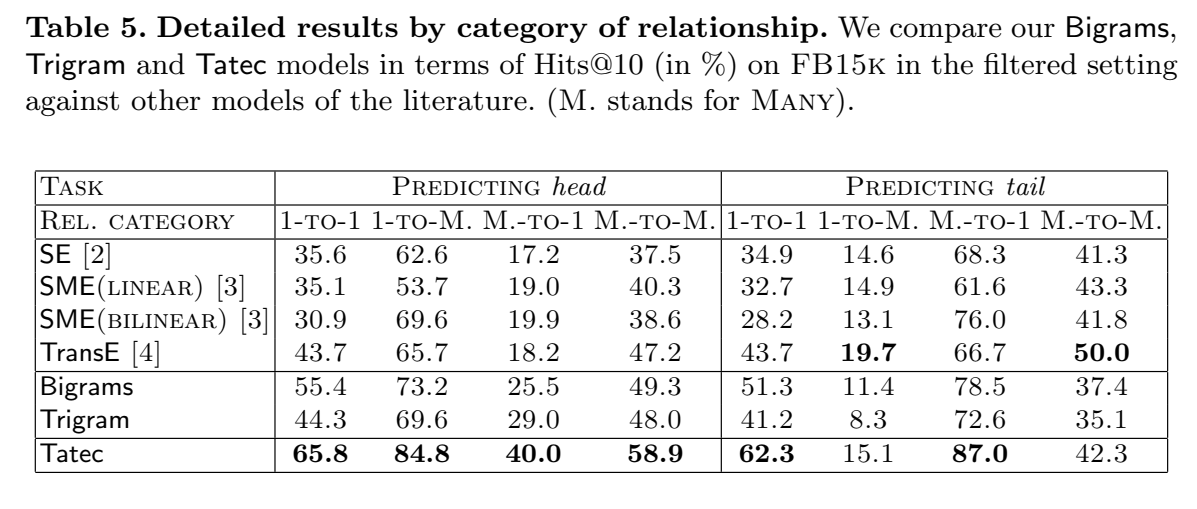
【总结】 文章提出了 TATEC,一种新的方法用于链接预测,将二元和三元交互项进行组合,两部分分别进行单独预训练,然后进行联合微调。
标签:自动化构建 data effective 基于 abi core 情况 neu 系统
原文地址:https://www.cnblogs.com/fengwenying/p/15066964.html