标签:des style blog http io ar color os sp
goals and assumptions
Google file system shares the same goals as previous distributed file systems:
1. scalability
2. performance
3. reliability
4. availability
However, it has special assumptions about application workloads and technological environment:
1. Component fails are the normal other than the exception.
system bugs, application bugs, user operation errors, hardware failures etc.
2. Files are huge by traditional standards.
3. File append operations are the most frequence operation.
arch overview
Master keeps all the meta data of the file system, while all the files are stored in chunk servers.
All the heavy operations(read, write, append) are performed directly between chunk servers and clients. Each chunk server serves some replicas of file system, thus pressures are balanced across the chunk server group(the key secret for building high-performance systems).
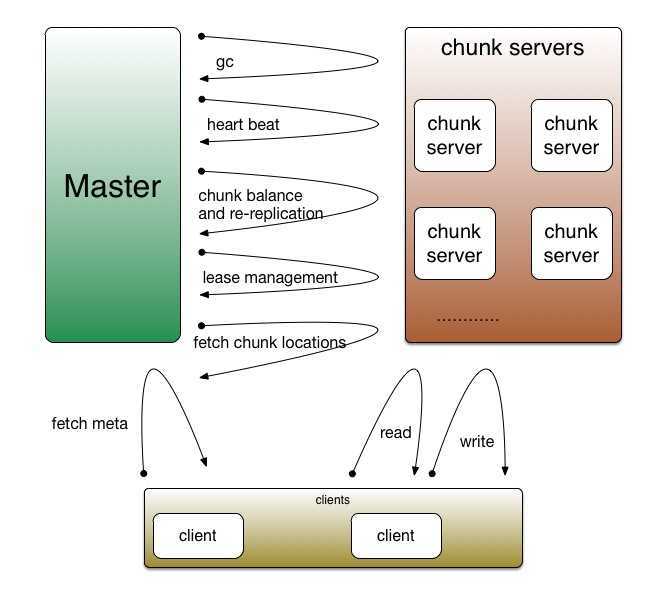
master
data structure
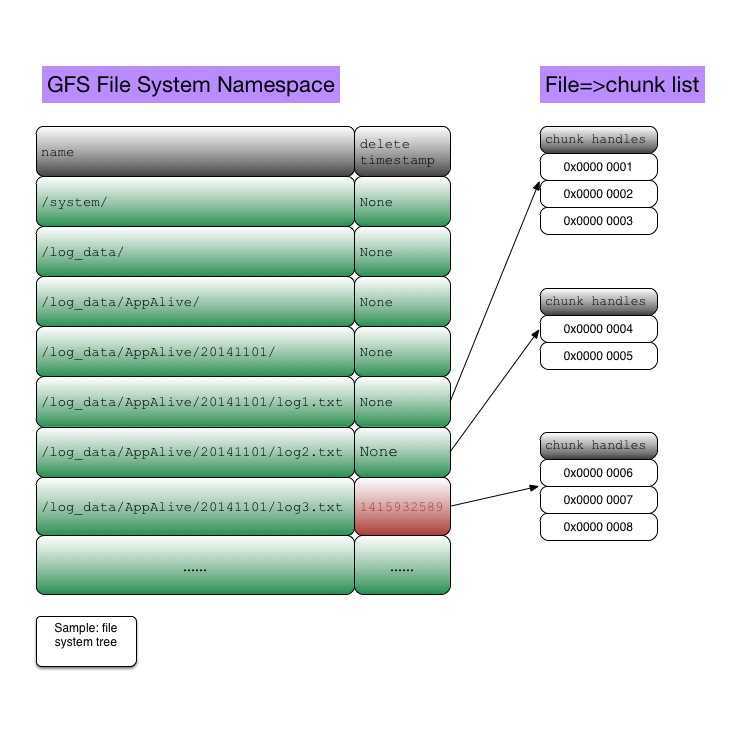
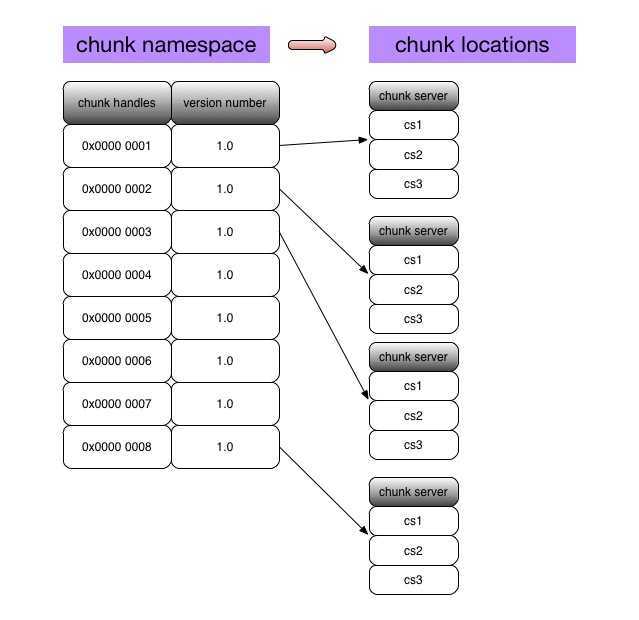
garbage collection
Look at the above 2nd picture(GFS file system namespace), where there‘s a "delete timestamp". When a file/folder is deleted, gfs records the timestamp. Master‘s background‘s gc process will scan, discover and remove these files/folders, and all the related meta data(chunk handles, chunk locations).
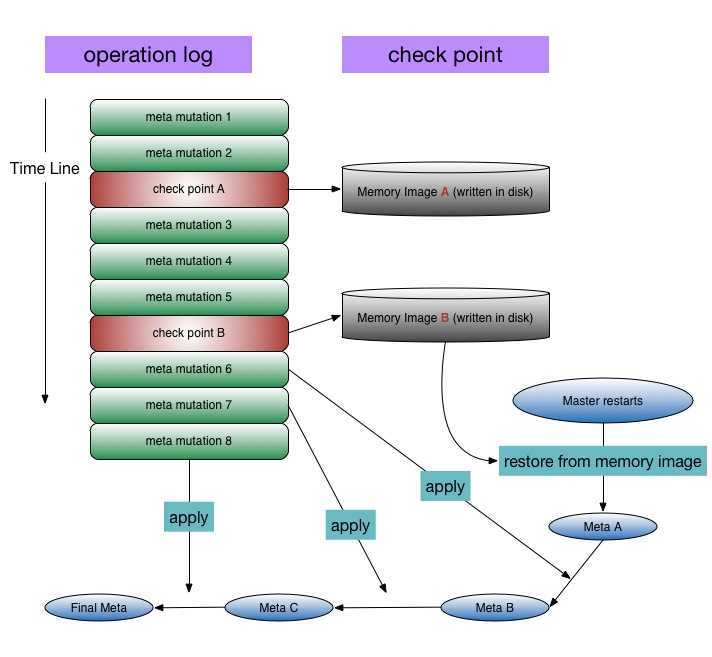
operation log and check point
All the mutations on the file system are ensured sequenced(syncronized, no concurrent mutation) by master. The mutations are recorded into operation log. When master restarts, operation logs are used to rebuild the file system meta data. Check points are "snap shots" of meta data structures; it‘s used for building metas quickly, as operation logs can become quite large.
chunk server
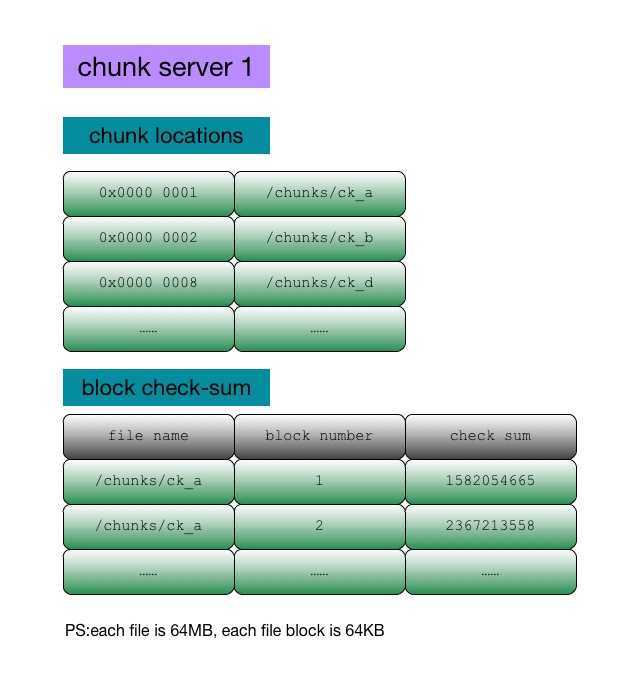
data structure
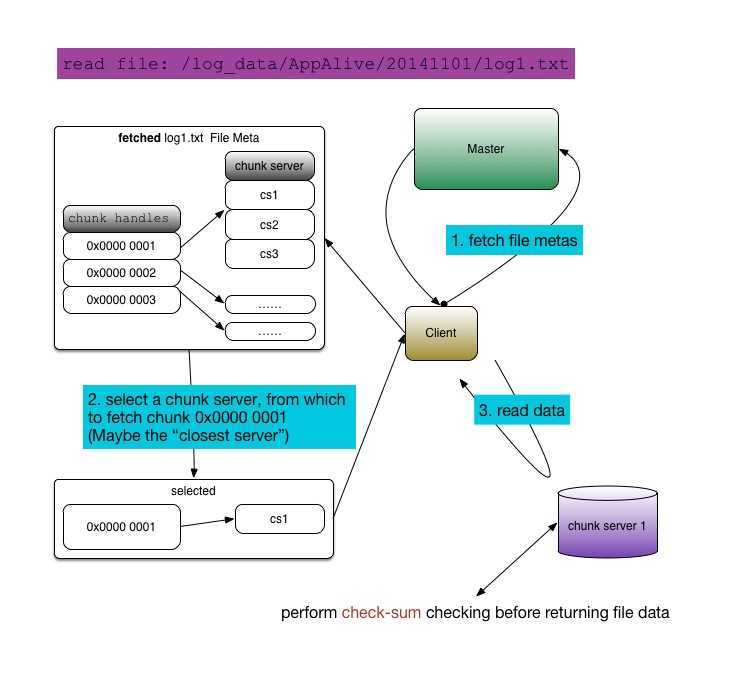
read
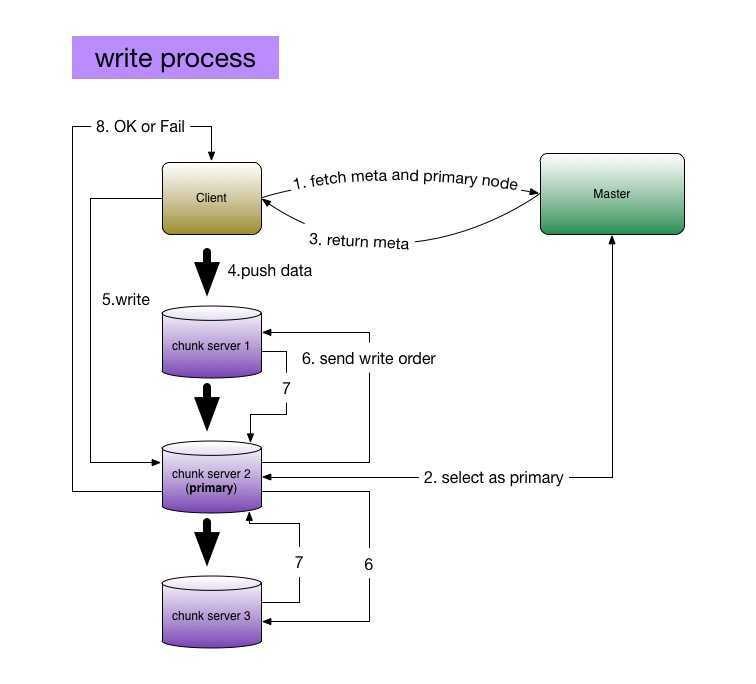
write
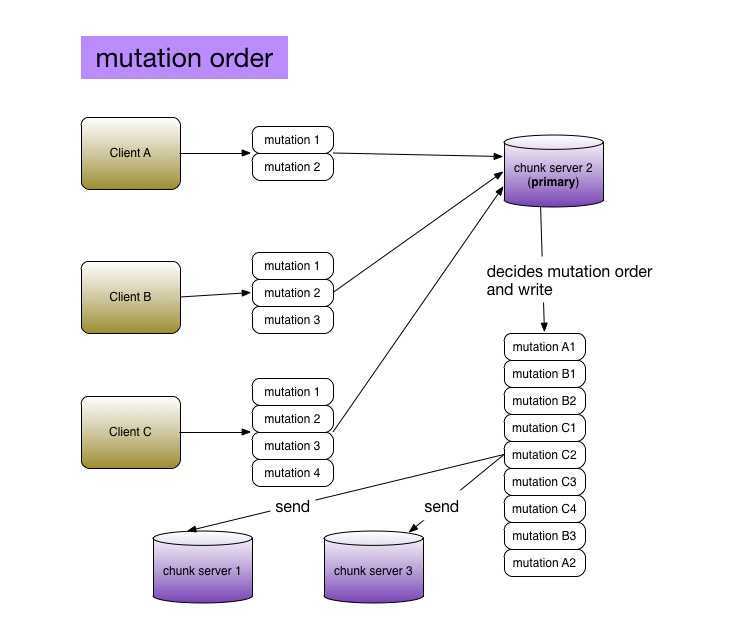
mutation order
Look at above diagram, step 6 "send write order". When multiple clients write to a file concurrently(step 1~5), the primary chunk server decides a mutation order. It performs these mutations according to this order, then sends it to all other replica servers.
normal mutation fail
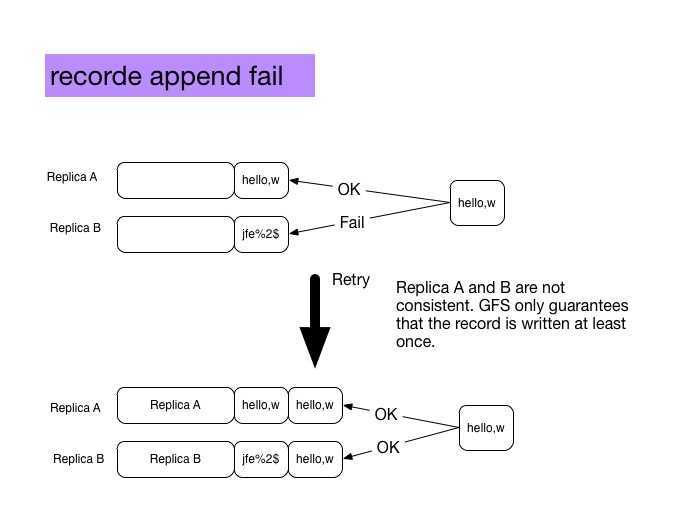
If write failed on one replica, the whole write operation is considered failed(although others are successful). Write will be retried on all replicas. Because applying the same mutation on the same replica more than once will not produce a diffrent replica, so the retry operation will not affect the successful replicas.
record append fail
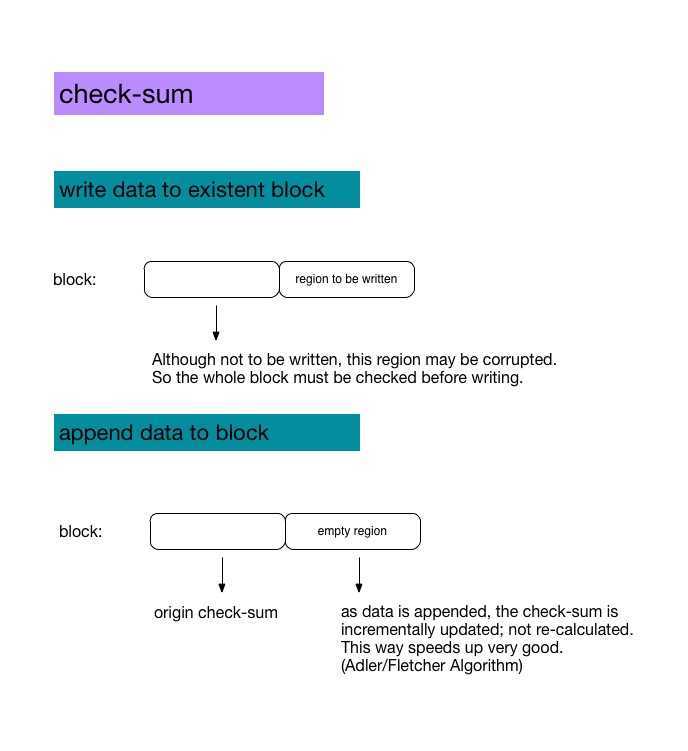
check-sum
Disk data may be corrupted for various reasons. Gfs uses check-sums to check data integrity. As we can see from the chunk server data structure diagram, a chunk server stores check-sums of replica‘s blocks. During read/write/append operations, check-sums are compared to detect data corruption.
When data corruption is raised, the corrupted replica will be discarded. Master will re-replicate to ensure enough replicas.
replica balance
Pressure distribution is key to high performance. So replica balance is very important. Master should have a topology graph of all its chunk servers and do replica balancing across machines, racks, swithces and diffrent network regions.
snap shot
stale replica
标签:des style blog http io ar color os sp
原文地址:http://www.cnblogs.com/linghuaichong/p/4097777.html