标签:blog http io ar os 使用 sp java for
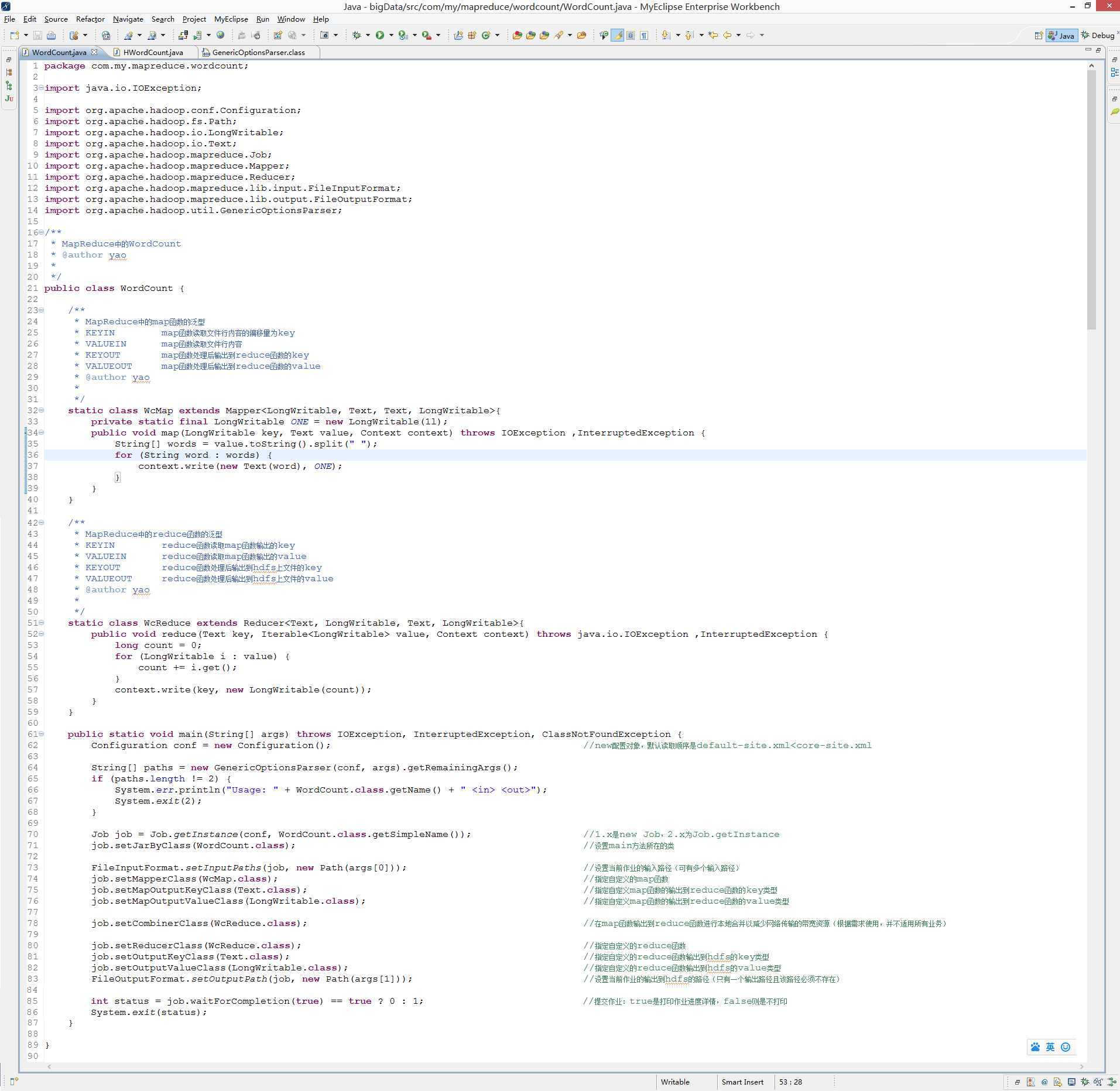
package com.my.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* MapReduce中的WordCount
* @author yao
*
*/
public class WordCount {
/**
* MapReduce中的map函数的泛型
* KEYIN map函数读取文件行内容的偏移量为key
* VALUEIN map函数读取文件行内容
* KEYOUT map函数处理后输出到reduce函数的key
* VALUEOUT map函数处理后输出到reduce函数的value
* @author yao
*
*/
static class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{
private static final LongWritable ONE = new LongWritable(1l);
public void map(LongWritable key, Text value, Context context) throws IOException ,InterruptedException {
String[] words = value.toString().split(" ");
for (String word : words) {
context.write(new Text(word), ONE);
}
}
}
/**
* MapReduce中的reduce函数的泛型
* KEYIN reduce函数读取map函数输出的key
* VALUEIN reduce函数读取map函数输出的value
* KEYOUT reduce函数处理后输出到hdfs上文件的key
* VALUEOUT reduce函数处理后输出到hdfs上文件的value
* @author yao
*
*/
static class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
public void reduce(Text key, Iterable<LongWritable> value, Context context) throws java.io.IOException ,InterruptedException {
long count = 0;
for (LongWritable i : value) {
count += i.get();
}
context.write(key, new LongWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration(); //new配置对象,默认读取顺序是default-site.xml<core-site.xml
String[] paths = new GenericOptionsParser(conf, args).getRemainingArgs();
if (paths.length != 2) {
System.err.println("Usage: " + WordCount.class.getName() + " <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, WordCount.class.getSimpleName()); //1.x是new Job,2.x为Job.getInstance
job.setJarByClass(WordCount.class); //设置main方法所在的类
FileInputFormat.setInputPaths(job, new Path(args[0])); //设置当前作业的输入路径(可有多个输入路径)
job.setMapperClass(WcMap.class); //指定自定义的map函数
job.setMapOutputKeyClass(Text.class); //指定自定义map函数的输出到reduce函数的key类型
job.setMapOutputValueClass(LongWritable.class); //指定自定义map函数的输出到reduce函数的value类型
job.setCombinerClass(WcReduce.class); //在map函数输出到reduce函数进行本地合并以减少网络传输的带宽资源(根据需求使用,并不适用所有业务)
job.setReducerClass(WcReduce.class); //指定自定义的reduce函数
job.setOutputKeyClass(Text.class); //指定自定义的reduce函数输出到hdfs的key类型
job.setOutputValueClass(LongWritable.class); //指定自定义的reduce函数输出到hdfs的value类型
FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置当前作业的输出到hdfs的路径(只有一个输出路径且该路径必须不存在)
int status = job.waitForCompletion(true) == true ? 0 : 1; //提交作业:true是打印作业进度详情,false则是不打印
System.exit(status);
}
}
标签:blog http io ar os 使用 sp java for
原文地址:http://www.cnblogs.com/mengyao/p/4109129.html