标签:style blog http io os 使用 sp for strong
深入理解计算机系统,对我来说是部大块头。说实话,我没有从头到尾完完整整的全部看完,而是选择性的看了一些我自认为重要的或感兴趣的章节,也从中获益良多,看清楚了计算机系统的一些本质东西或原理性的内容,这对每个想要深入学习编程的程序员来说都是至关重要的。只有很好的理解了系统到底是如何运行我们代码的,我们才能针对系统的特点写出高质量、高效率的代码来。这本书我以后还需要多研究几遍,今天就先总结下书中我已学到的几点知识。
编写高效的程序需要下面几类活动:
让编译器展开循环
说到程序优化,很多人都会提到循环展开技术。现在编译器可以很容易地执行循环展开,只要优化级别设置的足够高,许多编译器都能例行公事的做到这一点。用命令行选项“-funroll-loops”调用gcc,会执行循环展开。
性能提高技术:
说到性能提高,可能有人会有一些说法:
(1)不要过早优化,优化是万恶之源;
(2)花费很多时间所作的优化可能效果不明显,不值得;
(3)现在内存、CPU价格都这么低了,性能的优化已经不是那么重要了。
……
其实我的看法是:我们也许不必特地把以前写过的程序拿出来优化下,花费N多时间只为提升那么几秒或几分钟的时间。但是,我们在重构别人的代码或自己最初开始构思代码时,就需要知道这些性能提高技术,一开始就遵守这些基本原则来写代码,写出的代码也就不需要让别人来重构以提高性能了。另外,有的很简单的技术,比如说将与循环无关的复杂计算或大内存操作的代码放到循环外,对于整个性能的提高真的是较明显的。
如何使用代码剖析程序(code profiler,即性能分析工具)来调优代码?
程序剖析(profiling)其实就是在运行程序的一个版本中插入了工具代码,以确定程序的各个部分需要多少时间。
Unix系统提供了一个profiling叫GPROF,这个程序产生两类信息:
首先,它确定程序中每个函数花费了多少CPU时间。
其次,它计算每个函数被调用的次数,以执行调用的函数来分类。还有每个函数被哪些函数调用,自身又调用了哪些函数。
使用GPROF进行剖析需要3个步骤,比如源程序为prog.c。
1)编译: gcc -O1 -pg prog.c -o prog(只要加上-pg参数即可)
2)运行:./prog
会生成一个gmon.out文件供 gprof分析程序时候使用(运行比平时慢些)。
3)剖析:gprof prog
分析gmon.out中的数据,并显示出来。
剖析报告的第一部分列出了执行各个函数花费的时间,按照降序排列。
剖析报告的第二部分是函数的调用历史。具体例子可参考网上资料。
GPROF有些属性值得注意:
静态链接和动态链接一个很重要的区别是:动态链接时没有任何动态链接库的代码和数据节真正的被拷贝到可执行文件中,反之,链接器只需拷贝一些重定位和符号表信息,即可使得运行时可以解析对动态链接库中代码和数据的引用。
存储器映射
指的是将磁盘上的空间映射为虚拟存储器区域。Unix进程可以使用mmap函数来创建新的虚拟存储器区域,并将对象映射到这些区域中,这属于低级的分配方式。
一般C程序会使用malloc和free来动态分配存储器区域,这是利用堆的方式。
造成堆利用率很低的主要原因是碎片,当虽然有未使用的存储器但不能用来满足分配请求时,就会发生这种现象。
有两种形式的碎片:内部碎片和外部碎片。两者的区别如下:
现代OS提供了三种方法实现并发编程:
(1)基于进程的并发服务器
构造并发最简单的就是使用进程,像fork函数。例如,一个并发服务器,在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。为了了解这是如何工作的,假设我们有两个客户端和一个服务器,服务器正在监听一个监听描述符(比如描述符3)上的连接请求。下面显示了服务器是如何接受这两个客户端的请求的。 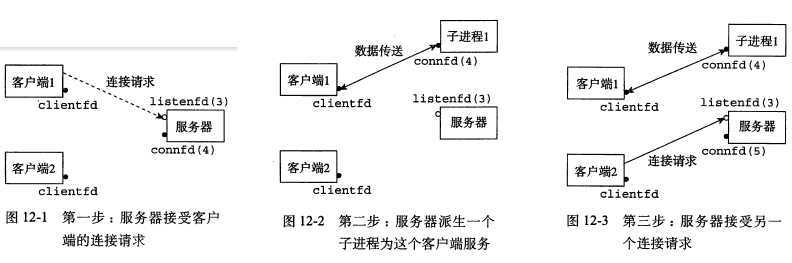
关于进程的优劣,对于在父、子进程间共享状态信息,进程有一个非常清晰的模型:共享文件表,但是不共享用户地址空间。进程有独立的地址控件爱你既是优点又是缺点。由于独立的地址空间,所以进程不会覆盖另一个进程的虚拟存储器。但是另一方面进程间通信就比较麻烦,至少开销很高。
(2)基于I/O多路复用的并发编程
比如一个服务器,它有两个I/O事件:1)网络客户端发起连接请求,2)用户在键盘上键入命令行。我们先等待那个事件呢?没有那个选择是理想的。如果accept中等待连接,那么无法响应输入命令。如果在read中等待一个输入命令,我们就不能响应任何连接请求(这个前提是一个进程)。
针对这种困境的一个解决办法就是I/O多路复用技术。基本思想是:使用select函数,要求内核挂起进程,只有在一个或者多个I/O事件发生后,才将控制返给应用程序。
I/O多路复用的优劣:由于I/O多路复用是在单一进程的上下文中的,因此每个逻辑流程都能访问该进程的全部地址空间,所以开销比多进程低得多;缺点是编程复杂度高。
(3)基于线程的并发编程
每个线程都有自己的线程上下文,包括一个线程ID、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。由于线程运行在单一进程中,因此共享这个进程虚拟地址空间的整个内容,包括它的代码、数据、堆、共享库和打开的文件。所以我认为不存在线程间通信,线程间只有锁的概念。
线程执行的模型。线程和进程的执行模型有些相似。每个进程的生明周期都是一个线程,我们称之为主线程。但是大家要有意识:线程是对等的,主线程跟其他线程的区别就是它先执行。
一般来说,线程的代码和本地数据被封装在一个线程例程中(就是一个函数)。该函数通常只有一个指针参数和一个指针返回值。
在Unix中线程可以是joinable(可结合)或者detached(分离)的。joinable可以被其他线程杀死,detached线程不能被杀死,它的存储器资源有系统自动释放。
线程存储器模型,每个线程都有它自己的独立的线程上下文,包括线程ID、栈、栈指针、程序计数器、条件码和通用目的寄存器。每个线程和其他线程共享剩下的部分,包括整个用户虚拟地址空间,它是由代码段、数据段、堆以及所有的共享库代码和数据区域组成。不同线程的栈是对其他线程不设防的,也就是说:如果一个线程以某种方式得到一个指向其他线程的指针,那么它可以读取这个线程栈的任何部分。
什么样的变量多线程可以共享,什么样的不可以共享?
有三种变量:全局变量、本地自动变量(局部变量)和本地静态变量,其中本地自动变量每个线程的本地栈中都存有一份,不共享。而全局变量和静态变量可以共享。
标签:style blog http io os 使用 sp for strong
原文地址:http://www.cnblogs.com/lanxuezaipiao/p/4141351.html