标签:
检索模型分为两种,一种是boolean model 一种是ranked retrieval
一 boolean查找:
1 binary decision:is document relevant or not?
文档只有相关和不相关两种,并没有排行
2 presence of term is necessary and sufficient for match
我们只需要记录每个文档有那些词汇就ok了
3 我们查询时的操作可以有 and和or都是集合操作
二 ranked algorithm:
1 frequency of document terms
文档中单词出现的频率,比如 文档1 出现love出现了10次,文档2 出现love出现了5次,
那么当搜索词为love时,文档1应该排在文档2之前
2 not all search terms necessarily present in document
这点主要是和boolean来分别。比如你要搜索love girl 那么在boolean search中文档必须既出现love和girl才会被我们检索到。而这一点ranked search不同,即使文档只有love没有girl也会被搜索到,只是排名会略低而已。
3 Incarnations:
1)vector space model
2)probabilistic model
3)web search engines
basis:
bag of words = like a set but also records a count for each element
boolean model:
搜索:
1 具体的搜索关键词
2 boolean operators(and or not but xor) note: xor = exlusive or
文档:
overall document collection forms maximal document set
优缺点:
文档:需要很高的专业知识去分类
用户:1 用户不会写boolean queries
2 用户想要有相关性的排名----这也是为什么boolean model不适合web search的原因
vector space model:
文档:
1 文档被表述为 bag of words
2 文档是 high-dimensional vector space
1 每个词汇都是一个方向
2 词汇的频率或者频率的变量是向量的值
查询:
queries 也被表示为类似的向量(for terms that exist in index)
具体方法:
1 选择那些与查询有最高相关性的文档
2 document-query 相似度是排名的准则
3 搜索返回的文档数量变得没有boolean model那么重要,用户从上往下查看直到满意为止
Score system:
1 distance
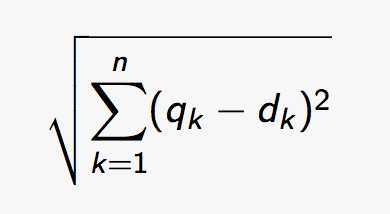
问题 freqency overweighted 比如 冠词 a不是很重要,但是出现得很多也会使文件排名降低
2 cos
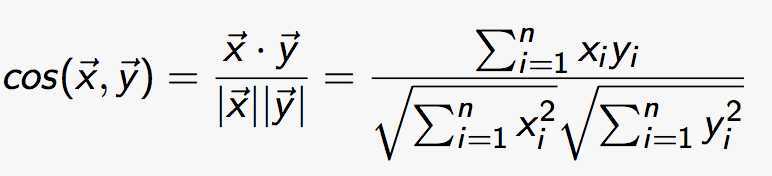
vector-space model采用得就是这种方法
通过这篇文章我们解决了boolean model和怎么测算向量之间得相似度问题。
下一篇文章将会重点讲述怎么具体得去操纵term。
标签:
原文地址:http://www.cnblogs.com/AlexWei/p/4176174.html