标签:
hadoop 起源
涉及到了:lucene,solr,nutch,hadoop
@auther ayy
@date 2014/12/21
1、lucene、nutch、solr
Lucene是由Doug Cutting创建的一个基于java的全文搜索工具包,它是Apache下一个很有名的项目。主要功能有:处理索引、拼写检查、一些分析和分词。
(lucene最初发布于个人网站和sourceforge,2001年,成为apache的项目jakarta的一个子项目)
solr和nutch本来也都是lucene下的子项目,但后来nutch成为了一个单独的项目。nutch的主要功能是:抓取数据,提取相关信息,它可以认为是google的一个微型版本。
solr是基于lucene的server端程序,主要功能为:提供了HTTP,python,xml,json等相关的API和管理的相关功能。
2、hadoop本来是nutch下的一个用于分布式处理的子项目,后来成为了apache下的一个项目。之前nutch可以使用hadoop进行分布式的数据抓取和处理。
(2003-2004 google开放了GFS和MapReduce的实现细节,Doug Cutting用了两年业余时间实现了DFS和MapReduce机制,使得nutch性能得以飙升。
2005年,hadoop本来属于apache项目lucene的子项目nutch的一部分正式被引入apache子项目。)
3、hadoop 子项目家族
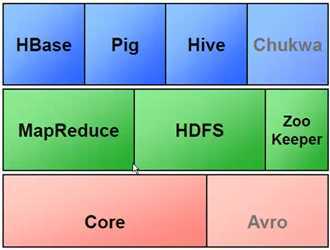
最下面是hadoop的核心代码,在核心代码基础上,实现了hadoop的两个支柱MapReduce和HDFS。
Pig 针对非java程序员,一个轻量级的语言,输入数据处理,数据分析的命令。系统可以转换为MapReduce的程序。
Hive 相当于SQL到MapReduce的一个映射器。针对数据库工程师,Hive将SQL转化为MapReduce的分布式任务。因此也可以将Hive理解为一个分布式数据库,大概可以支持到SQL92的部分标准。
HBase 是一个NoSQL、基于列式存储的数据库。好处:提高相应速度,减少IO量。也是目前比较热门的技术。
zooKeeper 协调工具。
Chukwa 数据收集器,可以将服务器产生的数据收集起来。
4、 hadoop 的架构
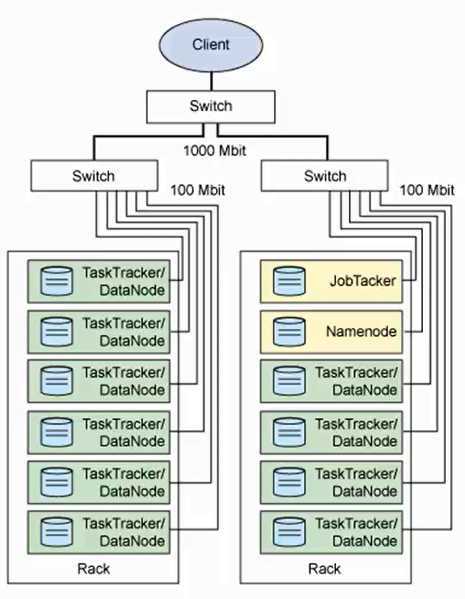
HDFS
Namenode 记录文件是如何被分割成块,以及这些块存在哪些节点上。 缺点:单点故障
数据读取过程:
数据写入过程:
SecondNamenode 与namenode进行通信,并周期性的保存HDFS的元数据。但是目前当namenode遇到故障,需要人工将secondnamenode接入。
Datanode 将HDFS的数据块写入当前机器的文件系统。
MapReduce
JobTracker 决定哪些文件参与处理,将任务切割为task,并分配到相应的节点。hadoop会将task分配到其对应数据的节点。jobtracker还要监控task的进度,向用户汇报,并重启失败的task。
TaskTracker 与JobTracker交互,并执行任务。
标签:
原文地址:http://www.cnblogs.com/ayy2014/p/4177038.html