标签:
最近学习主题模型pLSA、LDA,就想拿来试试中文。首先就是找文本进行切词、去停用词等预处理,这里我找了开源工具IKAnalyzer2012,下载地址:
https://code.google.com/p/ik-analyzer/
由于太多,而且名称我也搞不清楚,不知道下载哪个。后来我下载了IKAnalyzer2012.zip 压缩文件。

压缩后,按照说明说,需要配置

然而这里开始我连IKAnalyzer2012.jar安装部署否不清楚,后来慢慢摸索才弄清楚:
首先在Eclipse中建一个Java工程,我这里名称是“FC”,然后右键JRE System Library.jar ,点击Build Path-->Configure Build Path
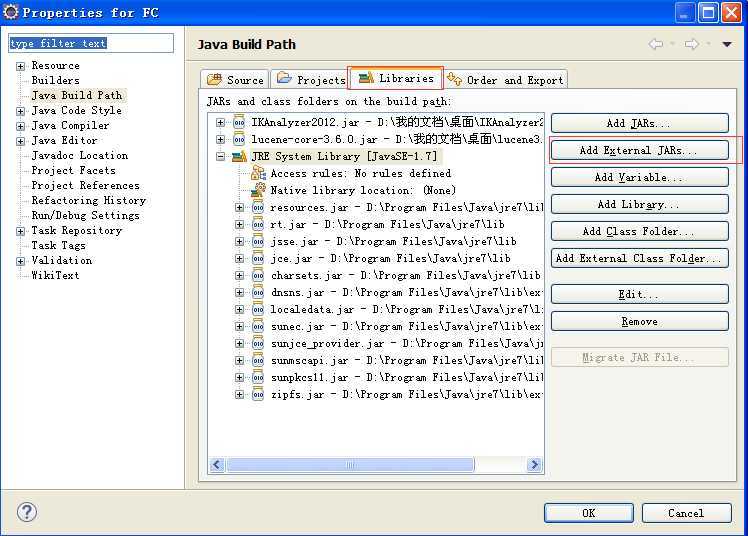
添加上IKAnalyzer2012.jar,确定。
stopwords.dic 是停用词文件,可以自己建一个ext.dic 即自定义词典,以及分词扩张配置文件(主要用于调取stopwords.dic, ext.dic), 我们将其加入到FC--scr下
由于会经常配合lucene-core使用,这个jar包可以从这里下载:http://grepcode.com/snapshot/repo1.maven.org/maven2/org.apache.lucene/lucene-core/3.6.1
安装如上进行配置。
我这里的配置后的工程目录如下:
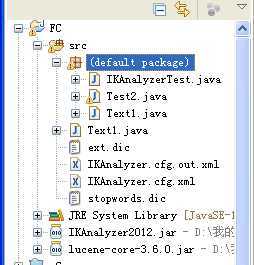
另外,双击scr下IKAnalyzer.cfg.xml文件,配置如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopwords.dic;</entry> </properties>
这里给一个分词演示程序:IKAnalyzerTest.java
在C盘根目录下,见一个需要分词的txt文档(注意,这里需要用软件Notepad2 对该内容转成UTF-8编码格式,将内容复制到Notepad中,点击文件 --编码--UTF-8--保存成txt文件即可):
李天一,现名李冠丰。著名歌唱家李双江和知名歌唱家梦鸽之子。根据司法机关公布资料显示,李天一出生于1996年4月。曾就读北京海淀区中关村第三小学、人民大学附中、美国Shattuck-St. Mary‘s School(沙特克圣玛丽学院)冰球学校。2011年9月6日,因与人斗殴被拘留教养1年。2012年9月19日,李天一被解除教养。2013年2月22日,因涉嫌轮奸案被刑事拘留,后因可查资料显示未成年,移交少管所。3月7日,中央电视台新闻中心官方微博发布了一条消息,称李天一因涉嫌强奸罪,已被检察机关批捕。2013年9月,李双江一篇旧文证实李天一成年。
在ext.dic中设置个性词典为:李双江、李天一、梦鸽。 stopwords.dic中用的是中文的常用停用词,这里可以在百度文库中下载(注意,用notepad转成UTF-8后保存)。
import java.io.*;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.StringReader;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class Text1 {
public static void main(String[] args) throws IOException {
String filePath = "C:\\test.txt";
String news=new String();
BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(filePath), "UTF8"));
String str;
while ((str = in.readLine()) != null) {
news+=str;
}
in.close();
System.out.println(news);
IKAnalyzer analyzer = new IKAnalyzer(true);
StringReader reader = new StringReader(news);
TokenStream ts = analyzer.tokenStream("", reader);
CharTermAttribute term = ts.getAttribute(CharTermAttribute.class);
while(ts.incrementToken()){
System.out.print(term.toString()+"|");
}
analyzer.close();
reader.close();
System.out.println();
StringReader re = new StringReader(news);
IKSegmenter ik = new IKSegmenter(re,true);
Lexeme lex = null;
File f = new File("C://jieguo.txt");
f.delete();
String path="C://jieguo.txt"; //%%%%%%
while((lex=ik.next())!=null){
System.out.print(lex.getLexemeText()+"|");
try {
FileWriter fw=new FileWriter(path,true);
PrintWriter pw=new PrintWriter(fw);
pw.print(lex.getLexemeText()+"|");
pw.close();
//bw.close();
fw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace(); }
}
}
}
分词后的文件,我这里仍然放在C盘根目录下,结果:
李天一|现名|李|冠|丰|著名|歌唱家|李双江|知名|歌唱家|梦鸽|之子|司法机关|公布|资料|显示|李天一|出生于|1996年|4月|曾|就读|北京|海淀区|中关村|第三|小学|人民大学|附中|美国|shattuck-st.|mary|s|school|沙特|克|圣玛丽|学院|冰球|学校|2011年|9月|6日|与人|斗殴|拘留|教养|1年|2012年|9月|19日|李天一|解除|教养|2013年|2月|22日|因涉嫌|轮奸案|刑事拘留|后|可查|资料|显示|未成年|移交|少管所|3月|7日|中央电视台|新闻中心|官方|微|博|发布|一条|消息|称|李天一|因涉嫌|强奸罪|已被|检察机关|批捕|2013年|9月|李双江|一篇|旧|文|证实|李天一|
标签:
原文地址:http://www.cnblogs.com/huadongw/p/4222866.html