标签:
IplImage* img = cvCloneImage(m_sourceImage);
IplImage* grayImage = cvCreateImage(cvGetSize(img), IPL_DEPTH_8U, 1);
//IplImage* redImage = cvCreateImage(cvGetSize(img), IPL_DEPTH_8U, 1);
//cvSplit(img, NULL, NULL, redImage, NULL);
cvCvtColor(img, grayImage, CV_RGB2GRAY);
//IplImage* img = cvCreateImage(cvGetSize(m_sourceImage), IPL_DEPTH_8U, 1);
//cvCvtColor(m_sourceImage, img, CV_RGB2GRAY);
int total = img->height*img->width;
int cluster_num = 2;
CvMat *row = cvCreateMat(img->height, img->width, CV_32FC3);
//cvConvert(redImage, row);
cvConvert(img, row);//转一下类型!
CvMat *clusters = cvCreateMat(total, 1, CV_32SC1);
// CvArr* cvReshapeMatND(const CvArr* arr,
// int sizeof_header, CvArr* header,
// int new_cn, int new_dims, int* new_sizes);
//
// arr :输入数组
// sizeof_header :输出头的大小,对于IplImage, CvMat 和 CvMatND 各种结构输出的头均是不同的.
// header:被添充的输出头.
// new_cn:新的通道数,如果new_cn = 0 则通道数保持原样
// new_dims:新的维数.如果new_dims = 0 则维数保持原样。
// new_sizes
// 新的维大小.只有当 new_dims = 1值被使用,因为要保持数组的总数一致,因此如果 new_dims = 1, new_sizes 是不被使用的
cvReshape(row, row, 0, total); //把图像转成数据矩阵,但注意实际数据未变,只是访问顺序变了。
cvKMeans2(row, cluster_num, clusters, cvTermCriteria(CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, 10, 1.0));
cvReshape(clusters, clusters, 0, img->width); //聚类完的结果再reshape回来比较方便看~
int i = 0, j = 0;
CvScalar s;
IplImage* resImg = cvCreateImage(cvSize(img->width, img->height), 8, 1);//生成用来显示结果的图像
s = cvGet2D(img, i, j);
vector <int> v1, v2; //存放分类后的灰度值
for (i = 0; i < img->height; i++)
{
for (j = 0; j < img->width; j++)
{
double val = cvGetReal2D(grayImage, i, j);
if (clusters->data.i[i*img->width + j] == 0)
{
v1.push_back(val); //处理完成后的图像的白色区域
s.val[0] = 255;
cvSet2D(resImg, i, j, s);//注意循环顺序
}
else
{
v2.push_back(val); //处理完成后的图像的黑色区域
s.val[0] = 0;
cvSet2D(resImg, i, j, s);
}
}
}
double thresh1 = accumulate(v1.begin(), v1.end(), 0) / v1.size();
double thresh2 = accumulate(v2.begin(), v2.end(), 0) / v2.size();
if (thresh2 > thresh1) //如果黑色区域的灰度值均值大于白色区域
{
cvNot(resImg, resImg); //图像取反
}
IplConvKernel *element = cvCreateStructuringElementEx(5, 5, 2, 2, CV_SHAPE_ELLIPSE);
cvSmooth(resImg, resImg, CV_MEDIAN);
cvErode(resImg, resImg, element, 1);
cvDilate(resImg, resImg, element, 1);
cvReleaseStructuringElement(&element);
cvSaveImage("s2.jpg", m_sourceImage);
cvSaveImage("b2.jpg", resImg);
ShowImage(resImg, IDC_PIC2);
int key = cvWaitKey(0);
cvReleaseImage(&img);//记得释放内存
cvReleaseImage(&resImg);
cvReleaseMat(&row);
cvReleaseMat(&clusters);
上述代码,对图像的处理结果进行了校正,因为,K-Mean聚类,只是简单的将目标区与背景区进行分类,而不能明确的标记出目标区还是背景区,所以,根据经验,将灰度值均值较大的部分作为目标区;
而灰度值较小的部分标记为背景区;
以下为未校正图像与校正后图像的对比:

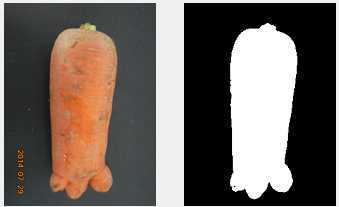
如上图所示:左侧图像为未做校正的处理效果,右侧图像为校正后的图像;
由于此方法只是简单的根据图像的灰度值对图像进行二值化,所以,很难对复杂背景的图像进行分割;相关的算法,在以后的学习中再进行完善与补充。
标签:
原文地址:http://www.cnblogs.com/lingtianyulong/p/4230575.html