标签:
本文是Heritrix的使用的高级篇,针对对Heritrix已经能够运行的码农朋友们!
我们在抓取网页的时候,网页的链接中往往会包含有js、css、图片、视频等文件,第一次执行抓取任务的时候,许多农民朋友们可能会发现抓取速度令人着急,可能是由于抓取了太多的不必要的数据文件,尤其是视频文件,少则几十兆,多则上百兆,这严重影响了我们的抓取的速度,还有一些缓存文件,配置文件等等。
那么如何才能做到只抓取html网页呢?(这里暂且不讨论抓取抓取指定域名的html网页,在之后的文章中可能会列出来!)
由于我们只对html文件中的链接感兴趣,所以去除了以下三个extractor。
ExtractorCSS
ExtractorJS
ExtractorSWF
修改前:

修改后:

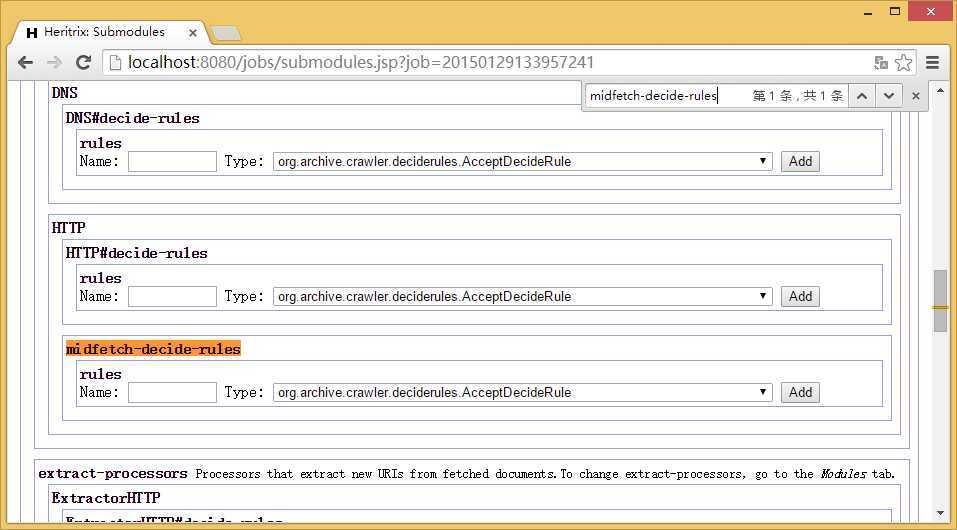
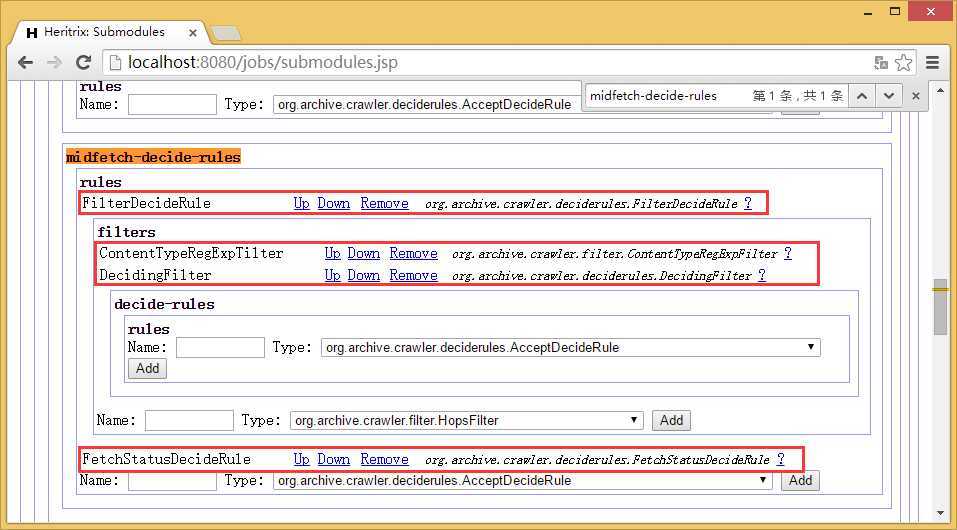
添加org.archive.crawler.deciderules.FilterDecideRule到midfetch-decide-rules
添加org.archive.crawler.filter.ContentTypeRegExpFilter和org.archive.crawler.deciderules.DecidingFilter
然后添加org.archive.crawler.deciderules.FetchStatusDecideRule到DecidingFilter
修改前:
修改后:
修改 regexp: 的值为“text/html*”【没有引号】
修改target-status的值为200
修改后为:
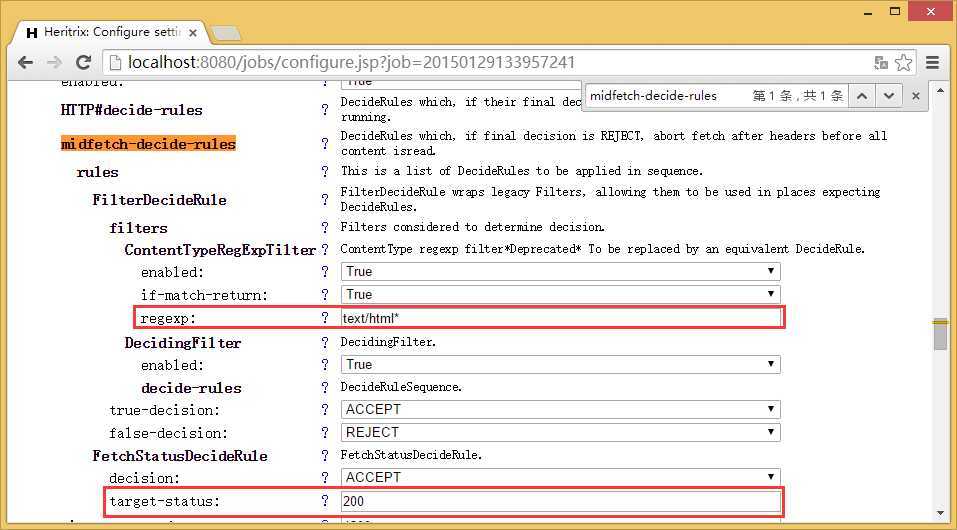
这样Heritrix就不会下载除了Content-Type为text/html并且Status Code为200之外的其他文件。
到此,设置就基本结束了!【本方法经实践检验】
===========================参考网址===========================
http://www.360doc.com/content/13/1122/14/13518188_331292907.shtml
===========================参考网址===========================
标签:
原文地址:http://www.cnblogs.com/zhjsll/p/4260992.html