标签:c style class blog code java
今天在做一个大业务的数据删除时,看到下面的性能曲线图
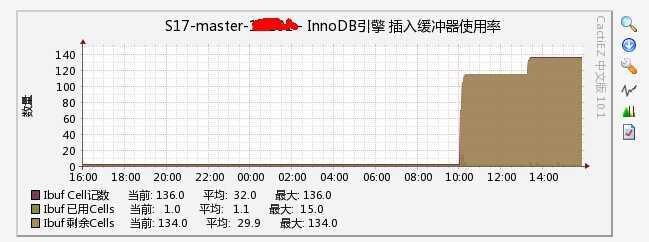
在删除动作开始之后,insert buffer 大小增加到140。对于这些状态参数的说明

插入缓冲,并不是缓存的一部分,而是物理页,对于非聚集索引的插入或更新操作,不是每一次直接插入索引页.而是先判断插入的非聚集索引页是否在缓冲池中.如果在,则直接插入,如果不再,则先放入一个插入缓冲区中.然后再以一定的频率执行插入缓冲和非聚集索引页子节点的合并操作.
使用条件:非聚集索引,非唯一
如果merges/merged的值等于3/1,则代表插入缓冲对于非聚集索引页的IO请求大约降低了3倍
InnoDB Insert Buffer Usage Ibuf Cell Count 分段大小 Ibuf Used Cells 插入缓冲区的大小 Ibuf Free Cells "自由列表"的长度
可以这样理解,在平时正常业务下,需要合并的二级索引基本没有,在做批量大删除的时候,产生了很多需要合并的二级索引改变。
看看合并操作节省了多少IO请求,(1034310+3)/113909=9.08,
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 134, seg size 136, 113909 merges merged operations: insert 3, delete mark 2319764, delete 1034310 discarded operations: insert 0, delete mark 0, delete 0 Hash table size 288996893, node heap has 304687 buffer(s) 1923.58 hash searches/s, 1806.60 non-hash searches/s
摘录一段朋友博客上对于insert buffer的说明
一,插入缓冲(Insert Buffer/Change Buffer):提升插入性能 只对于非聚集索引(非唯一)的插入和更新有效,对于每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,如果在则直接插入;若不在,则先放到Insert Buffer 中,再按照一定的频率进行合并操作。这样通常能将多个插入合并到一个操作中,提升插入性能。使用插入缓冲的条件: * 非聚集索引 * 非唯一 插入缓冲最大使用空间为1/2的缓冲池大小,不能调整大小,在plugin innodb中,升级成了Change Buffer。不仅对insert,对update、delete都有效。其参数是: innodb_change_buffering,设置的值有:inserts、deletes、purges、changes(inserts和deletes)、all(默认)、none。 可以通过参数控制其使用的大小: innodb_change_buffer_max_size,默认是25,即缓冲池的1/4。最大可设置为50。在5.6中被引入。 上面提过在一定频率下进行合并,那所谓的频率是什么条件? 1)辅助索引页被读取到缓冲池中。正常的select先检查Insert Buffer是否有该非聚集索引页存在,若有则合并插入。 2)辅助索引页没有可用空间。空间小于1/32页的大小,则会强制合并操作。 3)Master Thread 每秒和每10秒的合并操作。
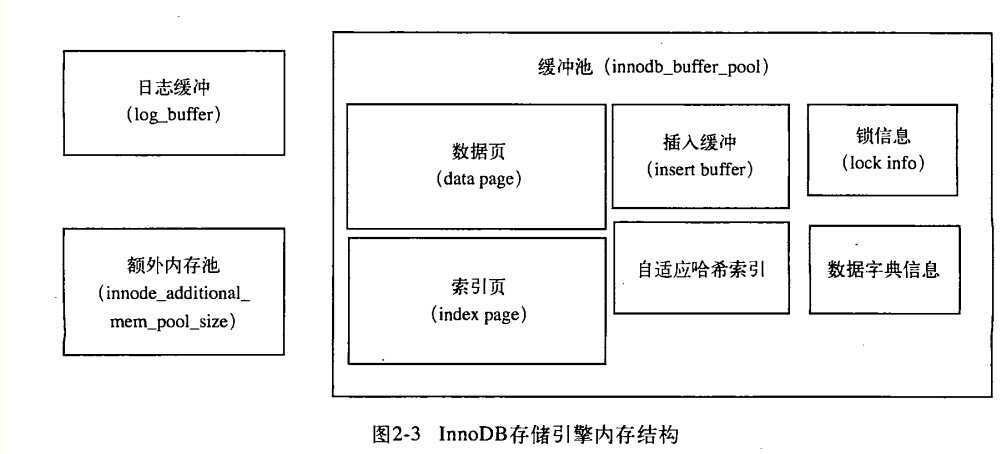
innodb buffer pool 包含的数据页类型有:索引页,数据页,undo页,插入缓冲(insert buffer),自适应哈希索引,innodb存储是锁信息,数据字典信息等,结构图如下
有几个问题需要回答
1:为什么会有insert buffer,insert buffer能帮我们解决什么问题?
2:insert buffer有什么限制,为什么会有这些限制?
先说第一个问题。
举个现实中的例子来做说明,我们去图书馆还书,对应图书馆来说,他是做了insert(增加)操作,管理员在1小时内接受了100本书,这时候他有2种做法把还回来的书归位到书架上
1)每还回来一本书,根据这本书的编码(书柜区-排-号)把书送回架上
2)暂时不做归位操作,先放到柜面上,等不忙的时候,再把这些书按照书柜区-排-号先排好,然后一次性归位
用方法1,管理员需要进出(IO)藏书区100次,不停的登高爬低完成图书归位操作,累死累活,效率很差。
用方法2,管理员只需要进出(IO)藏书区1次,对同一个位置的书,不管多少,都只要爬一次楼梯,大大减轻了管理员的工作量。
所以图书馆都是按照方法2来做还书动作的。但是你要说,我的图书馆就20本书,1个0.5米的架子,方法2和1管理起来都很方便,这种情况不在我们讨论的范围。当数据量非常小的时候,就不存在效率问题了。
关系数据库在处理插入操作的时候,处理的方法和上面类似,每一次插入都相当于还一本书,它也需要一个柜台来保存插入的数据,然后分类归档,在不忙的时候做批量的归位。这个柜台就是insert buffer.
我想这就是为什么会有insert buffer,更多的是处于性能优化的考虑。
再说第二个问题,有什么限制:“只对于非聚集索引(非唯一)的插入和更新有效”
为什么对于非聚集索引(非唯一)的插入和更新有效?
还是用还书的例子来说,还一本书A到图书馆,管理员要判断一下这本书是不是唯一的,他在柜台上是看不到的,必须爬到指定位置去确认,这个过程其实已经产生了一次IO操作,相当于没有节省任何操作。
所以这个buffer只能处理非唯一的插入,不要求判断是否唯一。聚集索引就不用说了,它肯定是唯一的,mysql现在还只能通过主键聚集。
在MYSQL里面,insert buffer的大小在代码里面设定的最大可以到整个innodb buffer pool size的50%。这其实是不科学的,能够想象一下一个100平米的图书馆,有50平米是做退书的柜台是什么样子的吗?
前面说到管理员图书归位的时候,他会选择在“不忙的时候”再去做,优先处理前台退书操作,这个在MYSQL里面是这样体现的:
1)每1秒,如果IO次数小于5,合并插入缓冲。
2)每10秒,IO次数小于200,合并最多5个插入缓冲。
innodb insert buffer 插入缓冲区的理解,布布扣,bubuko.com
标签:c style class blog code java
原文地址:http://www.cnblogs.com/zuoxingyu/p/3761461.html