标签:
一、概述
1.PL/Proxy 是一个采用PL Language语言的数据库分区系统。
目的:轻松访问分区数据库
概念图
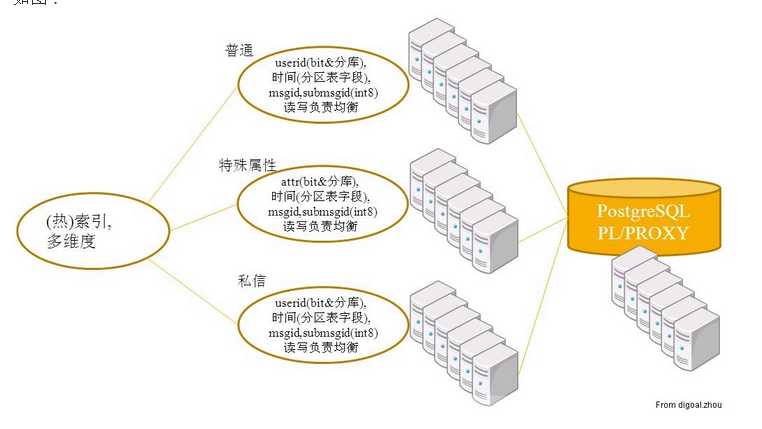
2.特性
3.个人理解:pl/proxy不是一个软件,与pgbouncer和pgpool不同。只是个在PostgreSQL数据库基础之上添加一些.sql文件,通过数据库执行这些文件最后实现集群的功能,而且能实现数据插入的负载均衡,这与pgxc插入数据时有点相似,它使用一种随机算法或者轮循方式将数据插入到数据节点当中。
通俗的介绍:PL/Proxy方式的集群是这样的:有很多安装了PostgreSQl数据库的计算机,有台计算机是头头,我们把这个头头叫做proxy,其他的叫做database0,database1……。当然名字叫什么是无所谓的,关键是有个是头头,其他的受头头指挥。
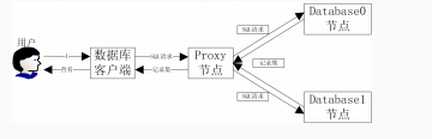
二、数据流的处理过程
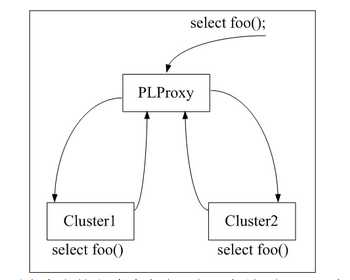
流程叙述:首先需要明确的是plproxy只能对用户自定的方法才有效,如果想达到对sql语句的无条件转发,plproxy是做不到的,比如希望所有的select * from tablename 都转发到cluster1上,所有的update语句都转发到cluster2上,是不能通过plproxy做到的。plproxy能做到的是:在plproxy cluster上定义foo()函数,在cluster1和cluster2上也定义foo()函数,cluster1和cluster2上的foo()函数的定义是完全相同的,包括函数参数都是相同的;二者和plproxy cluster上的foo()定义均不同。
4.在代理节点和各个数据库节点中安装plpgsql---createlang plpgsql <数据库名称>
标签:
原文地址:http://www.cnblogs.com/eagle-dtq/p/4290290.html