标签:
最近写脚本发现正则也挺有用的,于是就研究了一下。
总结起来使用正则表达式来匹配中文、韩文、日文、拉丁等范围的字符非常方便。这里也用到了unicode编码表相关知识,下面给出wiki的具体链接,有兴趣的童鞋可以去看看。
Unicode字符平面映射:
http://zh.wikipedia.org/wiki/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84
Unicode字符列表:
http://zh.wikipedia.org/wiki/Unicode%E5%AD%97%E7%AC%A6%E5%88%97%E8%A1%A8
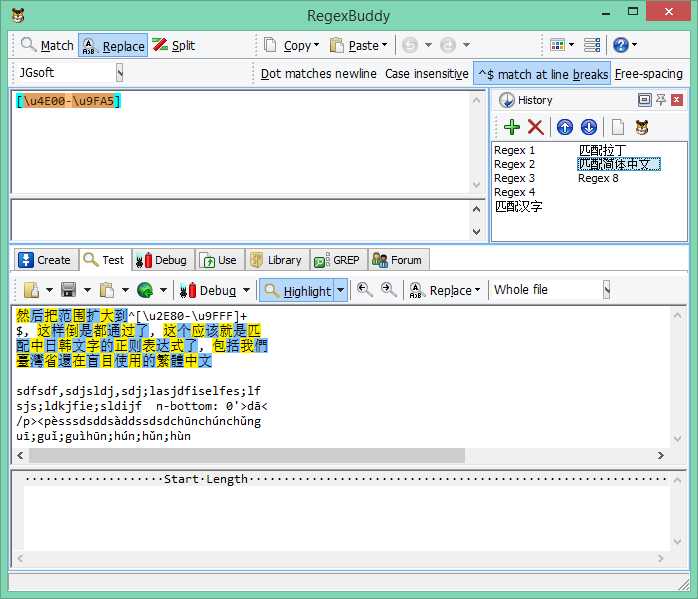
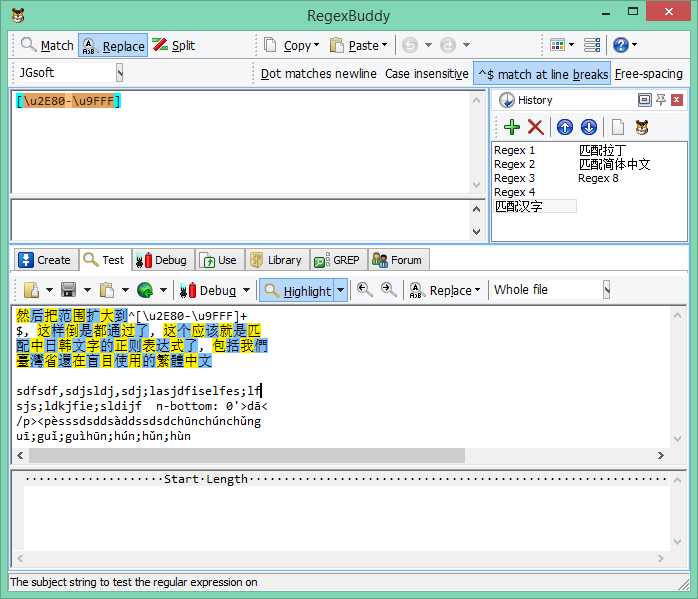
中(包括繁体)日韩字符:[\u2E80-\u9FFF]
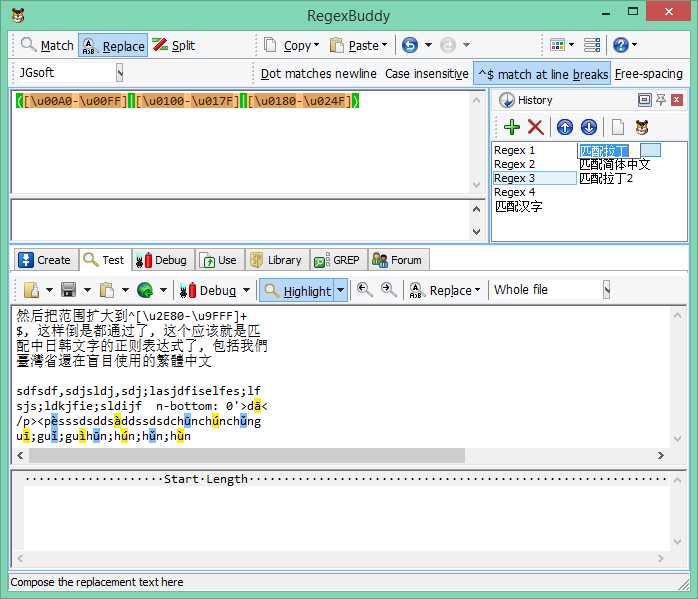
拉丁字符:([\u00A0-\u00FF]|[\u0100-\u017F]|[\u0180-\u024F])
这里拉丁我的典型应用时匹配汉字的音标:
下面是测试文档:
然后把范围扩大到^[\u2E80-\u9FFF]+
$, 这样倒是都通过了, 这个应该就是匹
配中日韩文字的正则表达式了, 包括我們
臺灣省還在盲目使用的繁體中文
sdfsdf,sdjsldj,sdj;lasjdfiselfes;lf
sjs;ldkjfie;sldijf n-bottom: 0‘>dā<
/p><pèsssdsddsàddssdsdchūnchúnchǔng
uī;guǐ;guìhūn;hún;hǔn;hùn
匹配结果截图:
标签:
原文地址:http://www.cnblogs.com/superstargg/p/4437261.html