标签:
Hibernate
Hibernate是轻量级Java EE应用的持久层解决方案,Hibernate不仅管理者Java类到数据库表的映射(包括Java 数据类型到SQL数据类型的映射),还提供数据查询和获取数据的方法,可以大幅度的缩短使用JDBC处理数据持久化的时间。
目前主流的数据库依然是关系型,如db2.oracle
对象关系数据库映射(ORM object/relation mapping):Hibernate ORM,其作用就是去映射对象和关系型数据库的,以达到程序中的业务逻辑和数据访问组件相分离。java是面向对象编程,它完成了对象模型和基于SQL的关系模型的映射关系,Hibernate允许开发者使用面向对象的方式来操作关系型数据库。
Hibernate则采用低侵入式的设计,即采用普通的Java对象(POJO),而不必继承Hibernate 的某个超类或者实现Hibernate的某个接口。
Hibernate 的支持,使得JavaEE应用的OOA (面向对象分析)、OOD(面向对象设计)和OOP(面向对象编程)但到了持久层数据库访问时,又必须重返关系型数库的访问方式
ORM是面向对象程序设计语言与关系型数据库发展不同步时的中间解决方案。随着面向对象数据库的发展 ,其理论逐步完善,最终会取代关系型数据库。只不过这个过程不会一蹴而就,ORM框架在此期间仍将蓬勃发展。但是随着面对对象数据库的出现,ORM工具会自动的消亡。
面向对象的优势:
(1)面向对象的建模、操作
(2)多态、继承
(3)摒弃难以理解的过程
(4)简单易用易理解
关系型数据库优势:
(1)大量数据的查找和排序
(2)集合数据连接操作、映射
(3)数据库访问的并发、事务
(4)数据库的约束和隔离
当我们采用ORM框架之后,应用程序不再直接访问底层的数据库,而是以面向对象的方式来操作持久化对象(例如创建、修改、删除等),而ORM框架则将这些面向对象操作转换成底层的SQL操作。
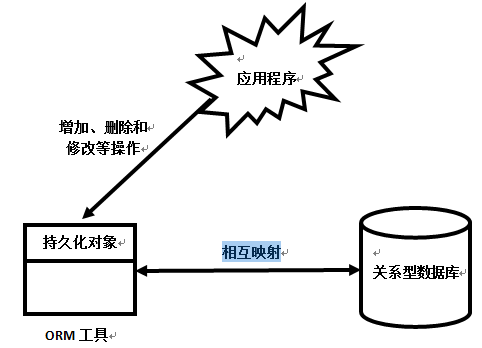
正如上图所示ORM工具的唯一作用就是把持久化对象的操作转换成对数据库的操作,从此程序员可以以面向对象的方式操作持久化对象,而ORM框架则负责转换成对应的SQL(结构化查询语言)操作。
2. 基本映射方式
ORMapping基本规则:
类和表映射。
实例和数据库表中的一条数据映射。
实例的属性和数据库表中的字段映射。
表名和类名可以不一样。
一个类可以映射多个表。
一个表可以映射多个对象。
类的属性字段名可以和数据库里面的字段名不一样。
类的属性字段个数可以和数据库里面的字段个数不一样。
类的属性字段顺序可以和数据库里面的字段顺序不一样。
类的属性字段类型和数据库里面的字段类型不一样,但是要能互相转换。
数据库表里面可以没有主键,但是对象里面一定要设置主键字段。
数据库表之间的关系就映射成为对象之间的关系。
XXX.cfg.xml 配置文件
XXX.hbm.xml 映射文件‘
映射文件的命名规则是,使用持久化类的类名,并使用扩展名hbm.xml.
映射文件需要在hibernate.cfg.xml中注册,最好与领域对象类放在同一目录中,这样修改起来很方便.
ORM工具提供了持久化类和数据表之间的映射关系 ,通过这种关系的映射过渡,我们可以很方便地通过持久化类对数据表进行操作。实际上,所有ORM工具大致上都遵循相同的映射思路。
ORM基本映射有如下这几条映射关系:
(1) 数据表映射类:
持久化类被映射到一个数据表。当我们使用这个持久化类来创建实例、修改属性、删除实例时,系统自动会转换为对这个表进行CRUD操作,下图显示了这种映射关系。
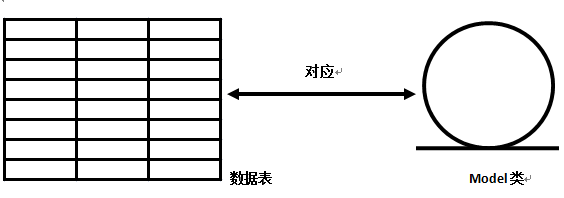
正如上图所示,受ORM管理的持久化类(就是一个普通的Java类)对应一个数据表,只要我们对这个持久化类进行操作,系统可以转换成对对应数据表的操作。
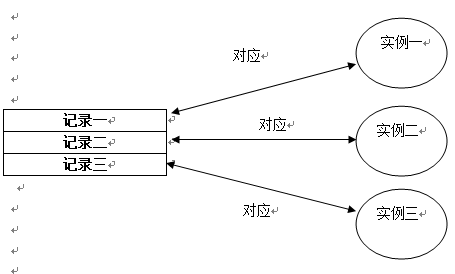
(2) 数据表的行映射对象(即实例):
持久化类会生成很多的实例,每个实例就对应数据表中的一行记录。当我们在应用中修改持久化类的某个实例时,ORM工具将会转换成对对应数据表中的特定行的操作。每个持久化对象对应数据表的一行记录。如下图所示:
(3) 数据表的列(字段)映射对象的属性:
当我们在应用中修改某个持久化对象的制定属性时(持久化数据映射到数据行),ORM将会转换成对对应表中指定数据行、指定列的操作。数据表列被映射到对象属性的示意图如下表示:

基于这些基本的映射方式,ORM工具可完成对对象模型和关系模型之间的相互映射。由此可见,在ORM框架中,对象持久化是一种中间媒介,应用程序只需要操作持久化对象,ORM框架则负责将这种操作转换为底层数据库操作——这种转换对开发者来说透明,无需开发者关心,从而将开发者从关系模型中解放出来,使得开发者能够以面向对象的思维操作关系型数据库。
持久化
狭义的理解: “持久化”仅仅指把域对象永久保存到数据库或本地硬盘中的对象;广义的理解,“持久化”包括和数据库相关的各种操作。
保存:把域对象永久保存到数据库。
更新:更新数据库中域对象的状态。
删除:从数据库中删除一个域对象。
加载:根据特定的OID,把一个域对象从数据库加载到内存。
查询:根据特定的查询条件,把符合查询条件的一个或多个域对象从数据库加载内在存中。
2.为什么要持久化?
持久化技术封装了数据访问细节,为大部分业务逻辑提供面向对象的API。
● 通过持久化技术可以减少访问数据库数据次数,增加应用程序执行速度;
● 代码重用性高,能够完成大部分数据库操作;
● 松散耦合,使持久化不依赖于底层数据库和上层业务逻辑实现,更换数据库时只需修改配置文件而不用修改代码。
Corpinfo.hbm.xml 映射文件代码如下
<hibernate-mapping>
<class name="cn.poka.cashman.model.CorpInfo" table="T_CORPINFO">
注:使用class元素定义一个持久化类,name是持久化类的java全名,table对应数据库表名
<id name="corpid" column="corpid"> 注:id定义了该属性到数据库表主键字段的映射
name标识属性名字,column表主键字段的名字,如果没有column默认与name一样
<generator class="assigned" />注:指定主键有什么生成,推荐使用uuid,assigned指用户手工填入
</id>
<property name="corpname" column="corpname"></property>
<property name="parentcorpid" column="parentcorpid"></property>
<property name="corpstate" column="corpstate"></property>
<property name="blankid" column="BLANKID"></property>
<property name="blankName" column="BLANKNAME"></property>
注:
</class>
</hibernate-mapping>
首先要说的是,Hibernate中ORM里对应的映射文件BEAN,必须实现序列化.因为BEAN里的数据需要存入数据库(要转化为二进制保存),进行存取工作.
JAVA类的数据 ,如果要进行相关的存储工作(如写文件,网络传输,写数据库等),那么这个数据的类 就必须实现序列化接口 (java.io.Serializable).
序列化 : 把对象转换 为二进制数据(如网络传输,存储数据库等),必须实现序列化接口 (java.io.Serializable).
持久化 : 把对象保存 在介质上(如写文件,读文件不是), 没有接口实现,一般指方法调用.
对象只有在序列化之后才能进行持久化存储,从持久化存储介质加载的数据通过反序列化转变成运行时对象。
对象的寿命通常随着生成该对象的程序的终止而终止。有时候,可能需要将对象的状态保存下来,在需要时再将对象恢复。我们把对象的这种能记录自己的状态以便将来再生的能力叫作对象的持续性(persistence)。
把Java对象转换为字节序列的过程称为对象的序列化。把字节序列恢复为Java对象的过程称为对象的反序列化。
public class CorpInfo implements java.io.Serializable {
private static final long serialVersionUID = -5261344533120040922L;
私有静态长整型定义了一个私有的 静态的 不可改变的 long类型的 名字是serialVersionUID的 值是-2231556599205500951L的常量
实现序列化接口时定义的序列化id,反序列化的时候可以根据这个id重新生成对象
什么情况下需要序列化
a)当你想把的内存中的对象写入到硬盘的时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
再稍微解释一下:a)比如说你的内存不够用了,那计算机就要将内存里面的一部分对象暂时的保存到硬盘中,等到要用的时候再读入到内存中,硬盘的那部分存储空间就是所谓的虚拟内存。在比如过你要将某个特定的对象保存到文件中,我隔几天在把它拿出来用,那么这时候就要实现Serializable接口;
b)在进行java的Socket编程的时候,你有时候可能要传输某一类的对象,那么也就要实现Serializable接口;最常见的你传输一个字符串,它是JDK里面的类,也实现了Serializable接口,所以可以在网络上传输。
c)如果要通过远程的方法调用(RMI)去调用一个远程对象的方法,如在计算机A中调用另一台计算机B的对象的方法,那么你需要通过JNDI服务获取计算机B目标对象的引用,将对象从B传送到A,就需要实现序列化接口。
对象要实现序列化,是非常简单的,只需要实现Serializable接口就可以了。
public class Test implements Serializable
标签:
原文地址:http://www.cnblogs.com/shareyezi/p/4442742.html