标签:style blog java http tar color
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机,增加更多的slave只需重复slave部分的内容即可。
系统版本:
1. 为master和slave机器安装JDK环境
下载jdk,如果安装版本“1.7.0_60”,官方下载地址为:java下载
解压jdk: tar -xvf jdk-7u60-linux-i586.tar.gz
在/usr/local/下新建java文件夹:mkdir /usr/local/java
将解压文件移动到创建的java/文件夹下:sudo mv jdk1.7.0_60 /usr/local/java
修改/etc/profile文件:sudo vi /etc/profile
在文件末尾添加jdk路径:

输入 source /etc/profile 使java生效
测试java是否完全安装:java -version #若出现版本信息则说明安装成功
2. 修改namenode(master)和子节点(slave)机器名:
sudo vi /etc/hostname
![]()
修改后需重启才生效:sudo reboot
3. 修改namenode(master)节点映射ip
sudo vi /etc/hosts #添加slave和master的机器名及其对应ip
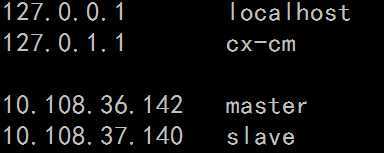
PS:master、slave分别是namenode和datanode机器名,即hostname的名字
4. 为master和slave分别创建hadoop用户及用户组,并赋予sudo权限
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop #第一个hadoop是用户组,第二个hadoop是用户名
下面为hadoop用户赋予sudo权限:修改 /etc/sudoers 文件
sudo vi /etc/sudoers
添加hadoop ALL=(ALL:ALL) ALL
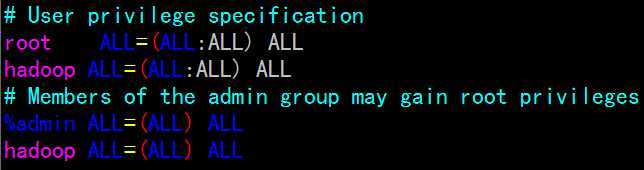
PS:该操作需要在所有master和slave主机上进行
5. 建立ssh无密码登陆环境
以hadoop身份登录系统:su hadoop
生成密钥,建立namenode与datanode的信任关系,ssh生成密钥有rsa和dsa方式,默认采用rsa方式:
在/home/hadoop目录下输入: ssh-keygen -t rsa -P ""
确认信息按回车,会在/home/hadoop/.ssh下生成文件:
将id_rsa.pub追加到authorized_keys授权文件中: cat id_rsa.pub >> authorized_keys
![]()
在各个子节点也生成密钥:ssh-keygen -t rsa -P ""
将master上的authorized_keys发送到各个子节点:
scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
下面测试ssh互信: ssh hadoop@slave1
如果不需要输入密码就可以登录成功则表示ssh互信成功建立
6. 安装hadoop(只需配置master主机,slave主机可以直接复制)
下载hadoop到/usr/local下:下载地址
解压hadoop-2.2.0.tar.gz:sudo tar -zxf hadoop-2.2.0.tar.gz
将解压出来的文件夹重命名为hadoop: sudo mv hadoop-2.2.0 hadoop
将hadoop文件夹的属主用户设为hadoop:sudo chown -R hadoop:hadoop hadoop
6.1 配置etc/hadoop/hadoop-env.sh文件
sudo vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到“export JAVA_HOME=”部分,修改为本机jdk路径

6.2 配置etc/hadoop/core-site.xml文件
sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
在<configuration></configuration>中间添加如下内容:
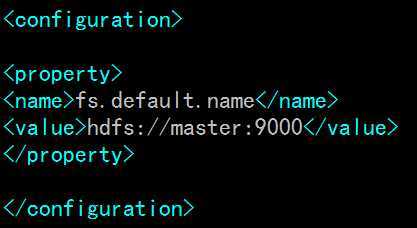
PS:master为namenode主机名,即/etc/hosts文件里的名字
6.3 配置etc/hadoop/mapred-site.xml文件,若路径下没有此文件,则将mapred-site.xml.template重命名
sudo vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
在<configuration></configuration>中间添加如下内容:
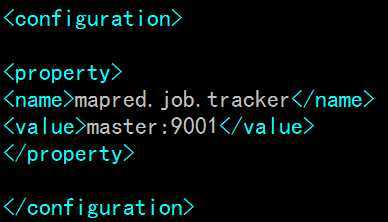
PS:master为namenode主机名,即/etc/hosts文件里的名字
6.4 配置hdfs-site.xml文件,若路径下没有此文件,则将hdfs-site.xml.template重命名
sudo vi hdfs-site.xml
在<configuration></configuration>中间添加如下内容:
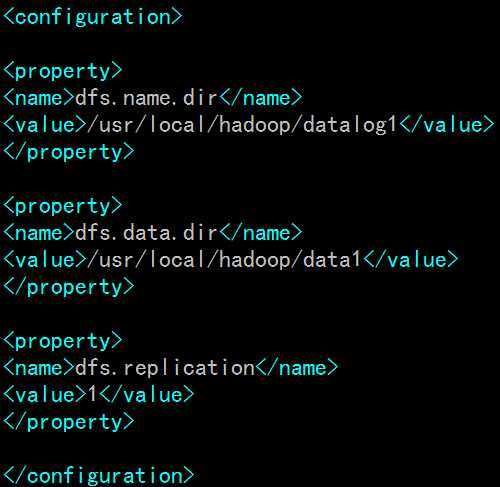
PS:若有多个slave节点,则将<value>间的内容可改为:
6.5 向slaves文件中添加slave主机名,一行一个

7.向slave节点分发配置文件
将配置文件发送到所有slave子节点上,先将文件复制到子节点/home/hadoop/下面(子节点也用hadoop用户登录:su hadoop)
sudo scp /etc/hosts hadoop@slave1:/home/hadoop
scp -r /usr/local/hadoop hadoop@slave1:/home/hadoop
PS:slave1为slave子节点名,若有多个slave节点,应全部分发
在datanode机器上(slave节点)将文件移动到与master相同的路径下
sudo mv /home/hadoop/hosts /etc/hosts (在子节点上执行)
sudo mv /home/local/hadoop /usr/local/ (在子节点上执行)
PS:若提示mv文件夹,则加上-r 参数
加入所属用户: sudo chown -R hadoop:hadoop hadoop (在子节点上执行)
PS:子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
配置完成
PS:可以将hadoop命令路径写入/etc/profile文件,这样我们就可以自如使用hadoop、hdfs命令了,否则在使用命令时都要加入/bin/hadoop这样的路径:
sudo vi /etc/profile

输入:source /etc/profile
8. 运行wordcount示例
首先进入/usr/local/hadoop/目录,重启hadoop
cd /usr/local/hadoop/sbin
./stop-all.sh
cd /usr/local/hadoop/bin
./hdfs namenode -format # 格式化集群
cd /usr/local/hadoop/sbin
./start-all.sh
可以在namenode上查看连接情况
hdfs dfsadmin -report #下面是我的机器的结果
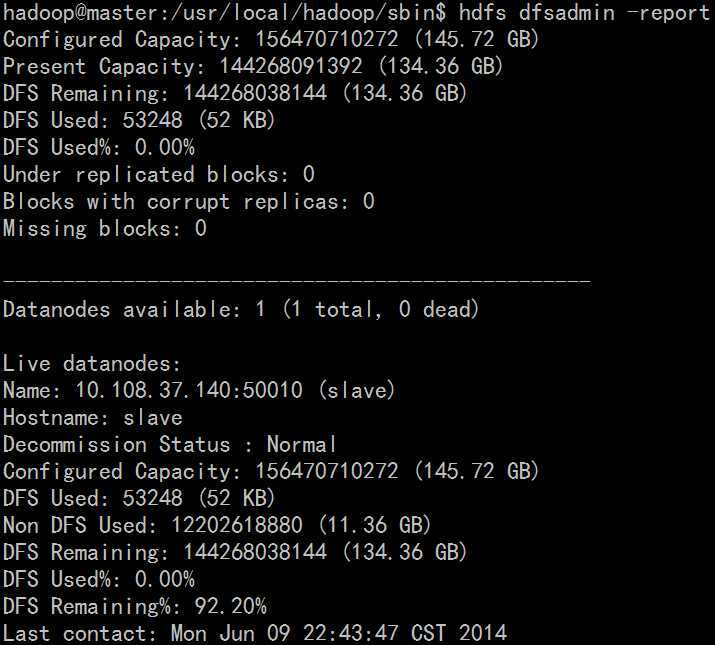
假设有测试文件test1.txt和test2.txt,首先创建目录/input
hadoop dfs -mkdir /input
将测试文件上传至hadoop:
hadoop dfs -put test1.txt /input/
hadoop dfs -put test2.txt /input/
子节点离开安全模式,否则可能会导致无法读取input的文件:
hdfs dfsadmin –safemode leave
运行wordcount程序:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input/ /output
查看结果
hadoop dfs -cat /output/part-r-00000
PS:再次运行时需要删除output文件夹 :hadoop dfs -rmr /output
Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创),布布扣,bubuko.com
Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
标签:style blog java http tar color
原文地址:http://www.cnblogs.com/tec-vegetables/p/3778358.html