标签:
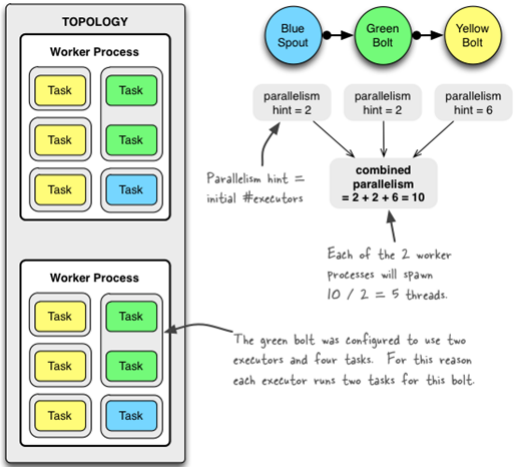
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //set tasks number to 4
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
Storm的并行度、Grouping策略以及消息可靠处理机制简介
标签:
原文地址:http://my.oschina.net/zc741520/blog/409949