标签:des style class blog code java
原文:SQL Server 索引和表体系结构(二)
非聚集索引
概述
对于非聚集索引,涉及的信息要比聚集索引更多一些,由于整个篇幅比较大涉及接下来的要写的“包含列的索引”,“索引碎片”等一些知识点,可能要结合起来阅读理解起来要更容易一些。非聚集索引和聚集索引一样都是B-树结构,但是非聚集索引不改变数据的存储方式,所以一个表允许建多个非聚集索引;非聚集索引的叶层是由索引页而不是由数据页组成,索引行包含索引键值和指向表数据存储位置的行定位器,
既可以使用聚集索引来为表或视图定义非聚集索引,也可以根据堆来定义非聚集索引。非聚集索引中的每个索引行都包含非聚集键值和行定位符。此定位符指向聚集索引或堆中包含该键值的数据行。
正文
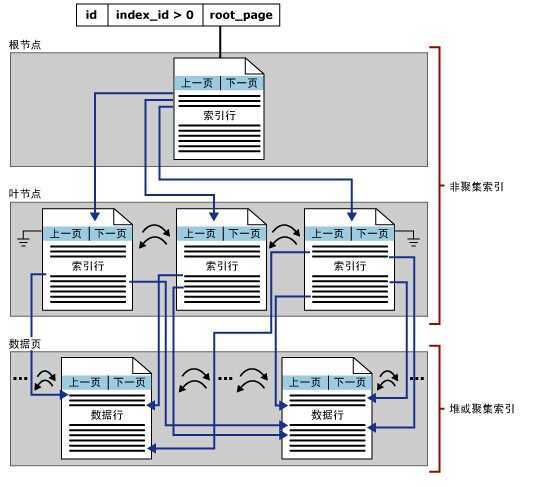
非聚集索引 Index_id>1 可以结合语句查询

SELECT o.name AS table_name,p.index_id, i.name AS index_name , au.type_desc AS allocation_type, au.data_pages, partition_number,p.rows, x.first_page,x.root_page,x.first_iam_page,x.filegroup_id,x.total_pages,x.used_pages FROM sys.allocation_units AS au JOIN sys.partitions AS p ON au.container_id = p.partition_id JOIN sys.objects AS o ON p.object_id = o.object_id JOIN sys.indexes AS i ON p.index_id = i.index_id AND i.object_id = p.object_id join sys.system_internals_allocation_units as x on au.container_id=x.container_id ORDER BY o.name, p.index_id;
非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述:
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
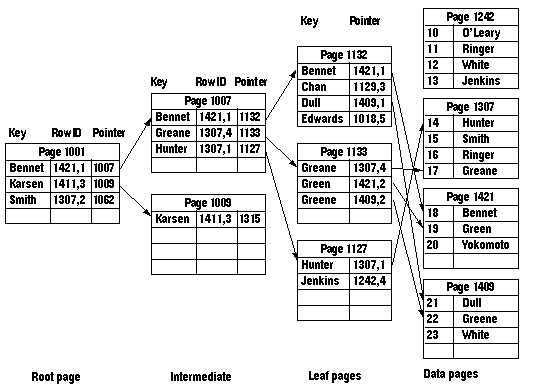
A)叶子结点并非数据结点
B)叶子结点为每一真正的数据行存储一个“键-指针”对
C)叶子结点中还存储了一个指针偏移量,根据页指针及指针偏移量可以定位到具体的数据行。
D)类似的,在除叶结点外的其它索引结点,存储的也是类似的内容,只不过它是指向下一级的索引页的。
聚集索引是一种稀疏索引,数据页上一级的索引页存储的是页指针,而不是行指针。而对于非聚集索引,则是密集索引,在数据页的上一级索引页它为每一个数据行存储一条索引记录。
注意:上图中的数据页是聚集索引或者堆数据行,而不是非聚集索引的数据页,在非聚集索引中不存在数据页,非聚集索引中的叶子层和根节点与中间节点有点不同,它的指针是指向数据行,且如果非聚集索引如果是包含列索引,那么包含列仅仅存储在叶级别,而键值可以存储在所有级别,这块会在接下来的包含列索引中讲述。
对于根与中间级的索引记录,它的结构包括:
A)索引字段值
B)RowId(即对应数据页的页指针+指针偏移量)。在高层的索引页中包含RowId是为了当索引允许重复值时,当更改数据时精确定位数据行。
C)下一级索引页的指针
对于叶子层的索引对象,它的结构包括:
A)索引字段值
B)RowId
由于索引建值存储在索引页中,所以检索单独的索引键值效率是很高的,因为不需要定位到数据页在索引页中就能找到数据,对于当个字段建索引非聚集索引所占的空间要小于聚集索引,因为非聚集索引不需要存储数据行,对于建全覆盖索引除外。
世界上没有绝对完美的事情,索引也是一样,给我们带来查询效率的同时也会有弊端
总结
这篇文章更重要的是讲述索引的存储结构和查找方式,没有讲述索引的一些基本概念和语句的写法,网上有很多写的很好这方面的文章。希望写这篇文章能给大家带来帮助,文章中有一些内容是从别的作者哪里拷贝过来的,因为我觉得原作者(KissKnife)在这方面已经讲述的非常到位,所以借鉴了一下,同样如果文章中有讲述的不合理的地方还望大家提出。
|
备注: 作者:沉寂的石头 博客:http://www.cnblogs.com/chenmh 欢迎大家转载,但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 欢迎大家拍砖 |
SQL Server 索引和表体系结构(二),布布扣,bubuko.com
标签:des style class blog code java
原文地址:http://www.cnblogs.com/lonelyxmas/p/3783733.html