标签:
有时,控制流依赖于thread索引。同一个warp中,一个条件分支可能导致很差的性能。通过重新组织数据获取模式可以减少或避免warp divergence(该问题的解释请查看warp解析篇)。
我们现在要计算一个数组N个元素的和。这个过程用CPU编程很容易实现:
int sum = 0; for (int i = 0; i < N; i++) sum += array[i];
那么如果Array的元素非常多呢?应用并行计算可以大大提升这个过程的效率。鉴于加法的交换律等性质,这个求和过程可以以元素的任意顺序来进行:
数组的切割主旨是,用thread求数组中按一定规律配对的的两个元素和,然后将所有结果组合成一个新的数组,然后再次求配对两元素和,多次迭代,直到数组中只有一个结果。
比较直观的两种实现方式是:
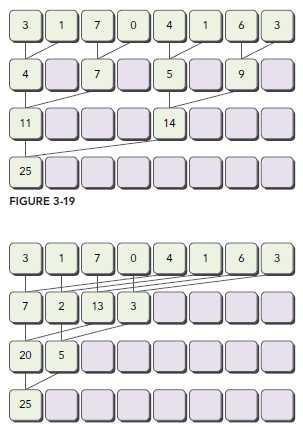
下图展示了两种方式的求解过程,对于有N个元素的数组,这个过程需要N-1次求和,log(N)步。Interleaved pair的跨度是半个数组长度。
下面是用递归实现的interleaved pair代码(host):
int recursiveReduce(int *data, int const size) { // terminate check if (size == 1) return data[0]; // renew the stride int const stride = size / 2; // in-place reduction for (int i = 0; i < stride; i++) { data[i] += data[i + stride]; } // call recursively return recursiveReduce(data, stride); }
上述讲的这类问题术语叫reduction problem。Parallel reduction是指降低并行程度,是并行算法中非常关键的一种操作。
这部分以neighbored pair为参考研究:
在这个kernel里面,有两个global memory array,一个用来存放数组所有数据,另一个用来存放部分和。所有block独立的执行求和操作。__syncthreads(关于同步,请看前文)用来保证每次迭代,所有的求和操作都做完,然后进入下一步迭代。
__global__ void reduceNeighbored(int *g_idata, int *g_odata, unsigned int n) { // set thread ID unsigned int tid = threadIdx.x; // convert global data pointer to the local pointer of this block int *idata = g_idata + blockIdx.x * blockDim.x; // boundary check if (idx >= n) return; // in-place reduction in global memory for (int stride = 1; stride < blockDim.x; stride *= 2) { if ((tid % (2 * stride)) == 0) { idata[tid] += idata[tid + stride]; } // synchronize within block __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = idata[0]; }
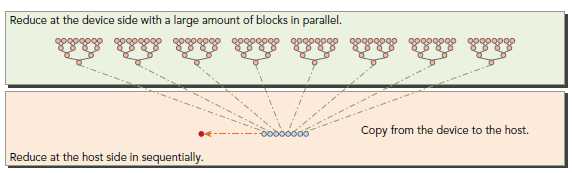
因为没有办法让所有的block同步,所以最后将所有block的结果送回host来进行串行计算,如下图所示:
main代码:

int main(int argc, char **argv) { // set up device int dev = 0; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); printf("%s starting reduction at ", argv[0]); printf("device %d: %s ", dev, deviceProp.name); cudaSetDevice(dev); bool bResult = false; // initialization int size = 1<<24; // total number of elements to reduce printf(" with array size %d ", size); // execution configuration int blocksize = 512; // initial block size if(argc > 1) { blocksize = atoi(argv[1]); // block size from command line argument } dim3 block (blocksize,1); dim3 grid ((size+block.x-1)/block.x,1); printf("grid %d block %d\n",grid.x, block.x); // allocate host memory size_t bytes = size * sizeof(int); int *h_idata = (int *) malloc(bytes); int *h_odata = (int *) malloc(grid.x*sizeof(int)); int *tmp = (int *) malloc(bytes); // initialize the array for (int i = 0; i < size; i++) { // mask off high 2 bytes to force max number to 255 h_idata[i] = (int)(rand() & 0xFF); } memcpy (tmp, h_idata, bytes); size_t iStart,iElaps; int gpu_sum = 0; // allocate device memory int *d_idata = NULL; int *d_odata = NULL; cudaMalloc((void **) &d_idata, bytes); cudaMalloc((void **) &d_odata, grid.x*sizeof(int)); // cpu reduction iStart = seconds (); int cpu_sum = recursiveReduce(tmp, size); iElaps = seconds () - iStart; printf("cpu reduce elapsed %d ms cpu_sum: %d\n",iElaps,cpu_sum); // kernel 1: reduceNeighbored cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice); cudaDeviceSynchronize(); iStart = seconds (); warmup<<<grid, block>>>(d_idata, d_odata, size); cudaDeviceSynchronize(); iElaps = seconds () - iStart; cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost); gpu_sum = 0; for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i]; printf("gpu Warmup elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n", iElaps,gpu_sum,grid.x,block.x); // kernel 1: reduceNeighbored cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice); cudaDeviceSynchronize(); iStart = seconds (); reduceNeighbored<<<grid, block>>>(d_idata, d_odata, size); cudaDeviceSynchronize(); iElaps = seconds () - iStart; cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost); gpu_sum = 0; for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i]; printf("gpu Neighbored elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n", iElaps,gpu_sum,grid.x,block.x); cudaDeviceSynchronize(); iElaps = seconds() - iStart; cudaMemcpy(h_odata, d_odata, grid.x/8*sizeof(int), cudaMemcpyDeviceToHost); gpu_sum = 0; for (int i = 0; i < grid.x / 8; i++) gpu_sum += h_odata[i]; printf("gpu Cmptnroll elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n", iElaps,gpu_sum,grid.x/8,block.x); /// free host memory free(h_idata); free(h_odata); // free device memory cudaFree(d_idata); cudaFree(d_odata); // reset device cudaDeviceReset(); // check the results bResult = (gpu_sum == cpu_sum); if(!bResult) printf("Test failed!\n"); return EXIT_SUCCESS; }
初始化数组,使其包含16M元素:
int size = 1<<24;
kernel配置为1D grid和1D block:
dim3 block (blocksize, 1); dim3 block ((siize + block.x – 1) / block.x, 1);
编译:
$ nvcc -O3 -arch=sm_20 reduceInteger.cu -o reduceInteger
运行:
$ ./reduceInteger starting reduction at device 0: Tesla M2070 with array size 16777216 grid 32768 block 512 cpu reduce elapsed 29 ms cpu_sum: 2139353471 gpu Neighbored elapsed 11 ms gpu_sum: 2139353471 <<<grid 32768 block 512>>> Improving Divergence in Parallel Reduction
考虑上节if判断条件:
if ((tid % (2 * stride)) == 0)
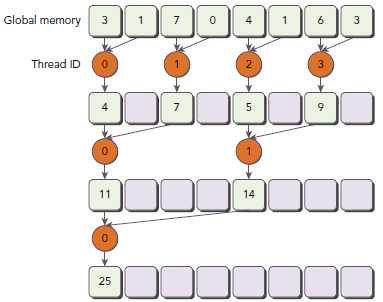
因为这表达式只对偶数ID的线程为true,所以其导致很高的divergent warps。第一次迭代只有偶数ID的线程执行了指令,但是所有线程都要被调度;第二次迭代,只有四分之的thread是active的,但是所有thread仍然要被调度。我们可以重新组织每个线程对应的数组索引来强制ID相邻的thread来处理求和操作。如下图所示(注意途中的Thread ID与上一个图的差别):
新的代码:
__global__ void reduceNeighboredLess (int *g_idata, int *g_odata, unsigned int n) { // set thread ID unsigned int tid = threadIdx.x; unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x; // convert global data pointer to the local pointer of this block int *idata = g_idata + blockIdx.x*blockDim.x; // boundary check if(idx >= n) return; // in-place reduction in global memory for (int stride = 1; stride < blockDim.x; stride *= 2) { // convert tid into local array index int index = 2 * stride * tid; if (index < blockDim.x) { idata[index] += idata[index + stride]; } // synchronize within threadblock __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = idata[0]; }
注意这行代码:
int index = 2 * stride * tid;
因为步调乘以了2,下面的语句使用block的前半部分thread来执行求和:
if (index < blockDim.x)
对于一个有512个thread的block来说,前八个warp执行第一轮reduction,剩下八个warp什么也不干;第二轮,前四个warp执行,剩下十二个什么也不干。因此,就彻底不存在divergence了(重申,divergence只发生于同一个warp)。最后的五轮还是会导致divergence,因为这个时候需要执行threads已经凑不够一个warp了。
// kernel 2: reduceNeighbored with less divergence cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice); cudaDeviceSynchronize(); iStart = seconds(); reduceNeighboredLess<<<grid, block>>>(d_idata, d_odata, size); cudaDeviceSynchronize(); iElaps = seconds() - iStart; cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost); gpu_sum = 0; for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i]; printf("gpu Neighbored2 elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n",iElaps,gpu_sum,grid.x,block.x);
运行结果:
$ ./reduceInteger Starting reduction at device 0: Tesla M2070 vector size 16777216 grid 32768 block 512 cpu reduce elapsed 0.029138 sec cpu_sum: 2139353471 gpu Neighbored elapsed 0.011722 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> gpu NeighboredL elapsed 0.009321 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
新的实现比原来的快了1.26。我们也可以使用nvprof的inst_per_warp参数来查看每个warp上执行的指令数目的平均值。
$ nvprof --metrics inst_per_warp ./reduceInteger
输出,原来的是新的kernel的两倍还多,因为原来的有许多不必要的操作也执行了:
Neighbored Instructions per warp 295.562500 NeighboredLess Instructions per warp 115.312500
再查看throughput:
$ nvprof --metrics gld_throughput ./reduceInteger
输出,新的kernel拥有更大的throughput,因为虽然I/O操作数目相同,但是其耗时短:
Neighbored Global Load Throughput 67.663GB/s NeighboredL Global Load Throughput 80.144GB/s Reducing with Interleaved Pairs
Interleaved Pair模式的初始步调是block大小的一半,每个thread处理像个半个block的两个数据求和。和之前的图示相比,工作的thread数目没有变化,但是,每个thread的load/store global memory的位置是不同的。
Interleaved Pair的kernel实现:
/// Interleaved Pair Implementation with less divergence __global__ void reduceInterleaved (int *g_idata, int *g_odata, unsigned int n) { // set thread ID unsigned int tid = threadIdx.x; unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x; // convert global data pointer to the local pointer of this block int *idata = g_idata + blockIdx.x * blockDim.x; // boundary check if(idx >= n) return; // in-place reduction in global memory for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) { if (tid < stride) { idata[tid] += idata[tid + stride]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = idata[0]; }
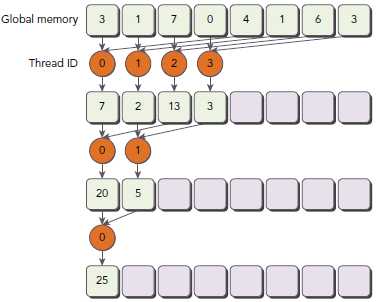
注意下面的语句,步调被初始化为block大小的一半:
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
下面的语句使得第一次迭代时,block的前半部分thread执行相加操作,第二次是前四分之一,以此类推:
if (tid < stride)
下面是加入main的代码:
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice); cudaDeviceSynchronize(); iStart = seconds(); reduceInterleaved <<< grid, block >>> (d_idata, d_odata, size); cudaDeviceSynchronize(); iElaps = seconds() - iStart; cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost); gpu_sum = 0; for (int i = 0; i < grid.x; i++) gpu_sum += h_odata[i]; printf("gpu Interleaved elapsed %f sec gpu_sum: %d <<<grid %d block %d>>>\n",iElaps,gpu_sum,grid.x,block.x);
运行输出:
$ ./reduce starting reduction at device 0: Tesla M2070 with array size 16777216 grid 32768 block 512 cpu reduce elapsed 0.029138 sec cpu_sum: 2139353471 gpu Warmup elapsed 0.011745 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> gpu Neighbored elapsed 0.011722 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> gpu NeighboredL elapsed 0.009321 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> gpu Interleaved elapsed 0.006967 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
这次相对第一个kernel又快了1.69,比第二个也快了1.34。这个效果主要由global memory的load/store模式导致的(这部分知识将在后续博文介绍)。
will present next day, good nigh every one!
CUDA 8 ---- Branch Divergence and Unrolling Loop
标签:
原文地址:http://www.cnblogs.com/1024incn/p/4548056.html
