标签:
HQL原文来自:http://slaytanic.blog.51cto.com/2057708/782175/ Slaytanic老师
关于Hadoop的介绍来自:http://www.cnblogs.com/shishanyuan/p/4629300.html 石山园老师,他的Hadoop博客写得很好,有兴趣可以去看下
Hive 是facebook开源的一个基于hadoop框架的查询工具,也就是说,需要用hive的话,就要先安装hadoop。
Hadoop的生态系统大致如下:
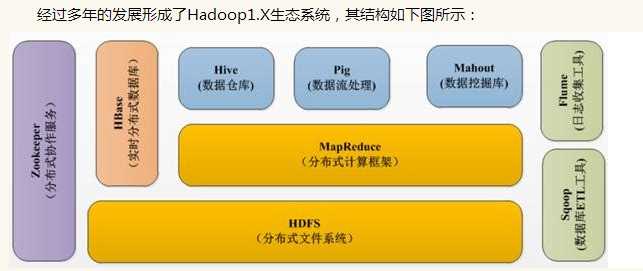
l HDFS--Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上,HDFS为HBase等工具提供了基础。
l MapReduce--Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型,MapReduce把任务分为map(映射)阶段和reduce(化简)。由于MapReduce工作原理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
l Hbase--HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
l Zookeeper--用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
l Pig--它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
l Hive--Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
l Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
l Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop。
比如我们公司,目前就是通过flume将存放在X台服务器上的数据拉回来,在拉取的过程中它会将每台服务器每个时段(每10分钟为一个时段)的txt文件合并起来,文件命名为:YYYY-MM-DD_hh_mm.tmp. 拉取回来的数据放在flumetable里,将它们的后缀变为log,之后按批次放入datatable里,之后每个批次的数据会被分成两个表(在hive中计算),这两个表再通过各种计算和join操作,得出报表,推送到sql server上,以便前端做呈现。(这段我自己写得所以很渣,这是目前数据处理流程,貌似有遗漏,看来我自己也没有多了解,还需要再学习,毕竟连自己公司的流程都不清楚,即便我并不是数据挖掘工程师。)
OK,下面入正题:
1.字段的数据类型。
hive实际上为了数据挖掘的需要,对hive表的字段设置了数据类型,对于经常where的,还可以设置index。
数据类型分以下几种
STRING 不定长字符串
TINYINT 3位长整型数
SMALLINT 5位长整型
INT 10位整型
BIGINT 19位整型
FLOAT 浮点数
DOUBLE 双精度
BOOLEAN 布尔型,也就是TRUE和FALSE
不同的整型数有不同的位数限制,这个创建表的时候需要注意一下,别因为位数不够造成数据截取。位数过大,又会造成元数据的空间浪费。
还有三种不常用到的
STRUCTS 结构体
ARRAY 数组
MAP 这个不知道该怎么翻译合适
2.创建数据表。
hive的数据表分为两种,内部表和外部表。
内部表指hive创建并通过load data inpath进数据库的表,这种表可以理解为数据和表结构都保存在一起的数据表。当你通过DROP TABLE table_name 删除元数据中表结构的同时,表中的数据也同样会从hdfs中被删除。
外部表指在表结构创建以前,数据已经保存在hdfs中了,通过创建表结构,将数据格式化到表的结构里。当DROP TABLE table_name 的时候,hive仅仅会删除元数据的表结构,而不会删除hdfs上的文件,所以,相比内部表,外部表可以更放心大胆的使用。
之前我一直不明白内部表和外部表的区别,经过老师一说,迅速懂了。内部表是先有结构后有数据,外部表示先有数据,然后建立个结构把数据放进去了。当我们drop table时,内部表是连表带数据一个不留地都删除了;外部表只把结构删了,数据还在,所谓留的青山在,不怕没柴烧。
3、内部表建表语句:
CREATE TABLE database.table1
(
column1 STRING COMMENT ‘comment1‘,
column2 INT COMMENT ‘comment2‘
);
4、外部表建表语句:
下面是hdfs中文件不用LZO压缩,纯文本保存时,如何创建外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS database.table1
(
column1 STRING COMMENT ‘comment1‘,
column2 STRING COMMENT ‘comment2‘
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION ‘hdfs:///data/dw/asf/20120201‘;
下面是,当hdfs中的文件用LZO压缩后,如何创建外部表,当然你需要hadoop-gpl的支持才能以文本形式读取lzo文件。
CREATE EXTERNAL TABLE IF NOT EXISTS database.table1
(
column1 STRING COMMENT ‘comment1‘,
column2 STRING COMMENT ‘comment2‘
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS INPUTFORMAT
"com.hadoop.mapred.DeprecatedLzoTextInputFormat" OUTPUTFORMAT
"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
LOCATION ‘hdfs:///data/dw/asf/20120201‘;
标红部分是十分操蛋的,网上几乎所有涉及该单词的文章基本全是复制粘贴抄的,无一例外,全部写成SORTED,如果你找的hive中文资料不是Slaytanic老师这篇,恐怕创建外部表都会报错。
--我一般用的比较多的都是内部表,所以对外部表没有什么发言权。另:为什么老师创建内部表的时候不指定分隔符呢?不指定也可以么?
5、内部表加载数据
l 从本地文件系统中加载数据:
Load data local inpath’文件的本地存储路径’overwrite into table basedatadb.table1;
如果加了overwrite,原本表中的数据就会被覆盖掉。
l 从HDFS中加载数据:
Load data inpath’文件在HDFS中的存储路径’ into table basedatadb.table1;
这个我本人还没有用过
6、分区
l 建分区
Alter table basedatadb.table1 add partition(day=’2015-07-26’);
l 删除分区:
Alter table basedatadb.table1 drop partition(day=’2015-07-26’);
未完待续,后续会补充复制表结构、增加新列~~~~想到了再补。没想到写博客居然这么费时间,原本计划半小时2篇的(/(ㄒoㄒ)/~~,其实不能算写,只是在复制老师们的总结,然后再加上自己的疑问和总结,实在不能算自己的作品。不过我还是会努力地,希望有一天能原创出自己的分享博客)。
标签:
原文地址:http://www.cnblogs.com/cyfighting/p/4678517.html