标签:style blog class code java tar
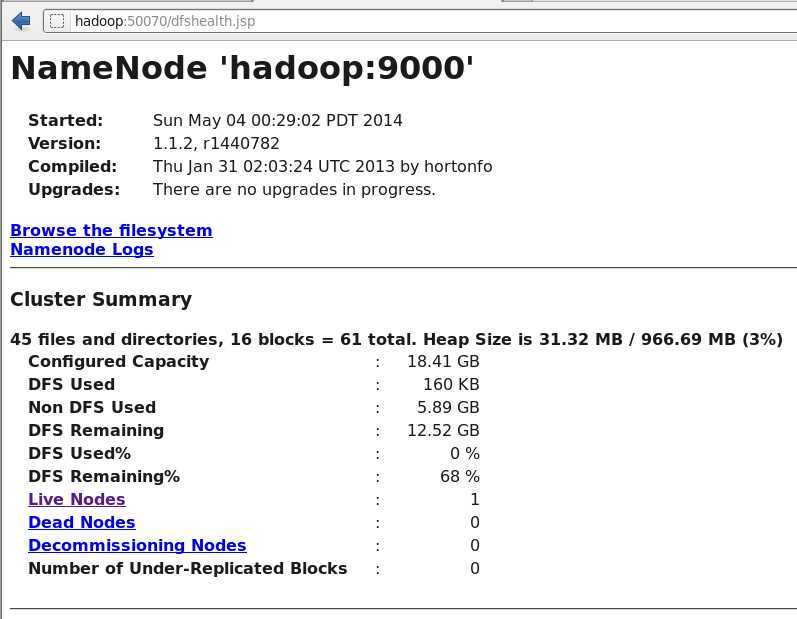
HDFS 分布式文件系统
主从结构,一个namenoe和多个datanode, 分别对应独立的物理机器
1) NameNode是主服务器,管理文件系统的命名空间和客户端对文件的访问操作。NameNode执行文件系统的命名空间操作,比如打开关闭重命名文件或者目录等,它也负责数据块到具体DataNode的映射
2)集群中的DataNode管理存储的数据。负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建删除和复制工作。
3)NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode
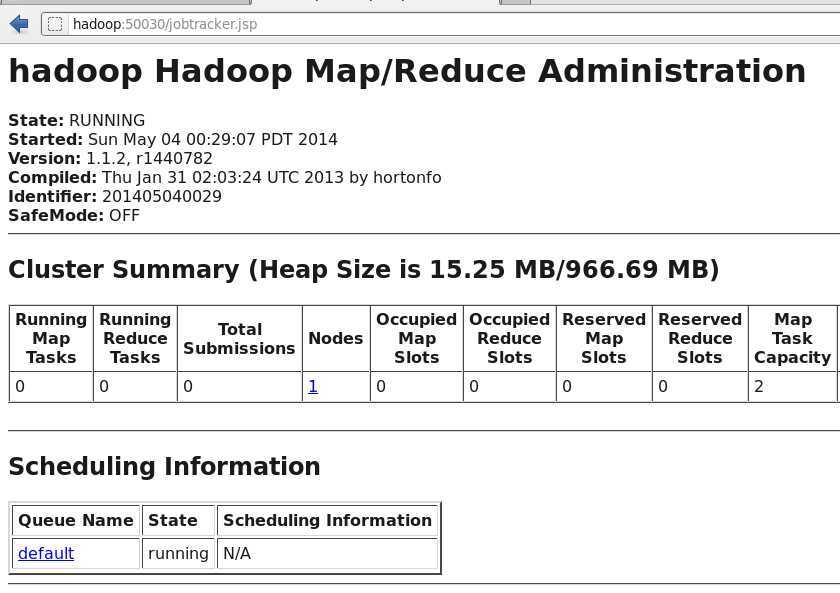
MapReduce 并行计算框架
主从结构,一个JobTracker和多个TaskTracker
1) MapReduce是由一个单独运行在主节点上的JobTacker和运行在每个集群从节点上的TaskTracker共同组成的。JobTacker负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。总结点监控他们的执行情况,
并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务
2) MapReduce模型原理是利用一个输入的key/value对集合来产生一个输出的key/value队集合,使用Map和Reduce函数来计算
3) MapReduce将大数据分解为成百上千小数据集,每个数据集分别由集群中的一个节点(一般是一台计算机)并行处理生成中间结果,后然这些中间结果又由大量的节点合并,形成最终结果
1)hadoop集群三种模式:本地模式(单机模式),伪分布模式,全分布式模式
单机模式:没有守护进程,所有东西运行在jvm上,使用的是本地文件系统, 没有dfs,使用开发过程中运行mapreduce程序,是使用最少的一种模式
伪分布模式:在一台服务器上模拟集群安装环境, 即多个进程运行在一个服务器上;使用与开发和测试环境,所有 守护进程在同一台机子上
全分布式模式:N台主机组成一个Hadoop集群,Hadoop守护进程运行在每一台主机上;分布式模式中,主节点和从节点会分开
2) 网络连接方式
host-only:宿主机(windows)与客户机(虚拟机中的客户机)单独组网,与主机当前的网络是隔离的
bridge:宿主机和客户机网络是连接的,在同一个局域网中,可以相互访问
NAT(network address translation): 虚拟机不占用主机所在局域网ip,通过使用主机的NAT功能访问区域网和互联网,此种方式虚拟机不用设置静态ip,只需要使用DHCP功能自动获取ip即可(绝大多数上网使用此种方式)
3)SSH 使用ssh进行免密码登陆
产生秘钥: ssh-keygen -t rsa
目录:~/.ssh
公钥拷贝:cp id_rsa.pub authorized_keys
准备: ----关闭防火墙(内网中,安全性问题较小)
查看状态:service iptables status
关闭: service iptables stop
关闭防火墙的自动启动: chkconfig -list | grep iptables(查看)
chkconfig iptables off(关闭)
----修改ip (修改后 让其生效:server network restart, 然后使用ifconfig查看)
----修改hostname(/etc/sysconfig/network 更改主机名; etc/hosts 将主机名与ip地址绑定; )
----设置ssh自动登录(查看上面章节)
ssh-keygen -t rsa
cp id_rsa.pub authorized_keys
验证 ssh localhost
1. 安装jdk -----配置环境变量(/etc/profile java_home和path)----生效(source /etc/profile)---验证(java -version)
2. 安装hadoop(tar -zxvf hadoop-1.1.2.tar.gz)---重名名(mv hadoop-1.1.2 hadoop)----配置环境变量(hadoop_home和path)----生效(source /etc/profile)
3. 伪分布式集群:
修改hadoop_home/conf下配置文件 hadoop-env.sh core-site.cml hdfs-site.xml mapred-site.xml

1.hadoop-env.sh export JAVA_HOME=/usr/local/jdk/ 2.core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop:9000</value>【HDFS的访问路径】 此处改为自己对应的主机名如hadoop0 </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration> 3.hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> 【存储副本数】 </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> 4.mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>hadoop:9001</value> 【Jobtracker的访问路径】 </property> </configuration>
4. 启动
hadoop namenode -format(格式化)
start-all.sh
使用jps查看进程
JobTracker、DateNode、TaskTracker、SecondaryNameNode、NameNode
网址栏中输入 hostname:50070 查看namenode信息
输入 hostname:50030 产看mapreduce信息
关闭: stop-all.sh
1.规划集群各节点的功能
两台主机 主机1 hadoop0 namenode ; 主机2 hadoop1 datanode
2. 检查如下配置(同伪分布式安装):1)防火墙是否关闭 2)ip是否设置 3)主机名是否设置 4)/etc/hosts是否配置 5)自己主机的ssh免密码登录是否设置
3. 集群间ssh免密码登录配置
在hadoop0上执行:ssh-copy-id -l ~/.ssh/id_rsa.pub hadoop1 (当本机已经产生rsa authorization时, 通过ssh-copy-id 可以将认证传送到宿端主机)
在hadoop1上执行:ssh-copy-id -l ~/.ssh/id_rsa.pub hadoop0
使用ssh hadoop1验证
4. 配置/etc/hosts文件
例如在hadoop0的/etc/hosts文件中添加: 192.168.1.169 hadoop0
192.168.1.21 hadoop1
5. 其他节点上jdk和hadoop的安装
在hadoop0上执行:
scp -rq /usr/local/jdk hadoop1:/usr/local (-r递归复制整个目录, -q不显示进度条)
scp -rq /usr/local/hadoop hadoop1:/usr/local
scp -rq /etc/profile hadoop1:/etc
scp -rq /etc/hosts hadoop1:/etc
source /etc/profile
6. 配置集群
hadoop0下 修改hadoop_home/conf/slaves(存储datanode和tasktracker节点名称),将localhost改为hadoop1
7. 启动集群
在hadoop0中执行hadoop namenode -format
start-all.sh
(关闭: stop-all.sh)
8. jps查看进程
hadoop0上 NameNode 、SecondarayNameNode、JobTracker进程
hadoop1上 DataNode、TaskTracker
9. 常见启动错误
unknownHostException :设置主机名错误(查看/etc/sysconfig/network)
BindException:ip设置错误(查看/etc/hosts)
Name Node is in safe mode 文件系统在安全模式(分布式文件系统启动时,开始会有 安全模式,出于安全模式时文件系统中的内容不允许修改和删除,直至安全模式结束,安全模式是系统启动时检查各个datanode上数据块的有效性,可以等待一会或者关闭安全模式 hadoop dfsadmin -safemode leave)
hadoop学习笔记——基础知识及安装,布布扣,bubuko.com
标签:style blog class code java tar
原文地址:http://www.cnblogs.com/wishyouhappy/p/3706647.html