标签:class rect tle nump raw build img ack 默认
1.StackOverflowError
问题:简单代码记录 :
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
大概场景就是我想把数量比较多的文件合并成一个大rdd,从而导致了栈溢出;
解决:很明显是方法递归调用太多,我之后改成了几个小任务进行了合并;这里union也可能会造成最终rdd分区数过多
2.java.io.FileNotFoundException: /tmp/spark-90507c1d-e98 ..... temp_shuffle_98deadd9-f7c3-4a12(No such file or directory) 类似这种
报错:Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 76.0 failed 4 times, most recent failure: Lost task 0.3 in stage 76.0 (TID 341, 10.5.0.90): java.io.FileNotFoundException: /tmp/spark-90507c1d-e983-422d-9e01-74ff0a5a2806/executor-360151d5-6b83-4e3e-a0c6-6ddc955cb16c/blockmgr-bca2bde9-212f-4219-af8b-ef0415d60bfa/26/temp_shuffle_98deadd9-f7c3-4a12-9a30-7749f097b5c8 (No such file or directory)
场景:大概代码和上面差不多:
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
rdd.map( ... )
解决:简单的map都会报错,怀疑是临时文件过多;查看一下rdd.partitions.length 果然有4k多个;基本思路就是减少分区数
可以在union的时候就进行重分区:
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day,numPartitions) .... )
} //这里因为默认哈希分区,并且分区数相同;所有最终union的rdd的分区数不会增多,贴一下源码以防说错
/** Build the union of a list of RDDs. */
def union[T: ClassTag](rdds: Seq[RDD[T]]): RDD[T] = withScope {
val partitioners = rdds.flatMap(_.partitioner).toSet
if (rdds.forall(_.partitioner.isDefined) && partitioners.size == 1) {
/*这里如果rdd的分区函数都相同则会构建一个PartitionerAwareUnionRDD:m RDDs with p partitions each
* will be unified to a single RDD with p partitions*/
new PartitionerAwareUnionRDD(this, rdds)
} else {
new UnionRDD(this, rdds)
}
}
或者最后在重分区
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
rdd.repartition(numPartitions)
3.java.lang.NoClassDefFoundError: Could not initialize class com.tzg.scala.play.UserPlayStatsByUuid$
at com.tzg.scala.play.UserPlayStatsByUuid$$anonfun$main$2.apply(UserPlayStatsByUuid.scala:42)
at com.tzg.scala.play.UserPlayStatsByUuid$$anonfun$main$2.apply(UserPlayStatsByUuid.scala:40)
场景:用scala 写的一个类,把所有的常量都放到了类的成员变量声明部分,结果在加载这个类的成员变量时报错
反编译成java字节码类似这UserPlayStatsByUuid$.class 类部分public final class implements Serializable
public final class implements Serializable {
public static final MODULE$; private final int USER_OPERATION_OPERATION_TYPE;
public int USER_OPERATION_OPERATION_TYPE() { return this.USER_OPERATION_OPERATION_TYPE; } static { new (); }
private Object readResolve(){return MODULE$; }
private () {MODULE$ = this; this.USER_OPERATION_OPERATION_TYPE = 4;}
}
报错部分类字节码:
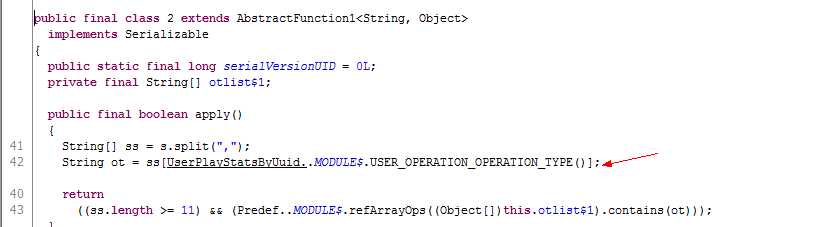
解决:这里只是搞清楚了在加载类的一个成员变量失败,导致抛出NoClassDefFoundError:Could not initialize class,没有找到比较好的详细说明的文档;简单粗暴的方式就是把这些常量移出类的声明体,那么在初始化时肯定不会加载失败了
4.ContextCleaner Time Out
17/01/04 03:32:49 [ERROR] [org.apache.spark.ContextCleaner:96] - Error cleaning broadcast 414
akka.pattern.AskTimeoutException: Timed out
解决:spark-submit增加了两个参数:
--conf spark.cleaner.referenceTracking.blocking=true \
--conf spark.cleaner.referenceTracking.blocking.shuffle=true \
参考自spark-issue:SPARK-3139
5. java.lang.NoSuchMethodError: scala.Predef$.ArrowAssoc(Ljava/lang/Object;)
解决:scala环境和spark环境不匹配,spark1.x 对应scala10 ; spark2.x 对应scala11
标签:class rect tle nump raw build img ack 默认
原文地址:http://www.cnblogs.com/arachis/p/Spark_prog.html