标签:注意 mat 执行 run 意思 div 重写 ssi block
在VPC功能实现第一篇中,简单介绍了一下VPC网络对租户间隔离能力的提升以及基于路由提供的一系列网络功能。在这一篇中,将继续介绍VPC网络中十分重要的一个内容:网络带宽的控制,共享以及分离。
首先是对第一篇中,端口转发功能的样例代码,all-in-one http service 风格的实现。
核心功能:
find_router_ip = "ip netns exec qrouter-{router_id} ifconfig |grep -A1 qg- | grep inet | awk ‘{{print $2}}‘".format(router_id=router_id)
(status, output) = commands.getstatusoutput(find_router_ip)
run_router_dnat = "ip netns exec qrouter-{router_id} iptables -t nat -D PREROUTING -d {router_gwip} -p {protocol} --dport {router_port} -j DNAT --to-destination {vm_ip}:{vm_port}".format(router_id=router_id,router_gwip=router_gwip,protocol=protocol,router_port=router_port,vm_ip=vm_ip,vm_port=vm_port)
(status, output) = commands.getstatusoutput(run_router_dnat)
Git repo地址
在readme中有简单的介绍,通过最基本的rest请求即可实现功能。
Demo级的代码,逻辑十分好理解,根据输入的router_uuid ,找到 L3 节点上的命名空间,修改iptables实现转发功能即可。
如果要在环境中正式使用,建议引入数据库作为转发记录的存储。引入了数据存储后推荐加入额外的两个流程:
1. 一致性
在通过commands或popen等执行系统命令的时候,通过不同的return status 及回显作逻辑分支或try-exception。保证调用功能时的数据库里的存储规则和nat表上规则一致性。
如果nat规则的写入和代码里不同——不是直接在preforward主链而是在neutron-l3的子链里写入,会发现执行某些网络操作之后,nat规则会丢失,这是因为Neutron-l3-agent在router所控制的floating_ip发生变动时,自身会重写nat表中自身子链的规则,这是neutron自己对l3数据一致性的保证。
2. 恢复
在l3节点所有配置清零重置后,能够恢复之前各命名空间内的nat规则。这个功能简单说就是一个读取数据库规则并解析执行的批量过程,也和Neutron的sync过程相似。
另外,从安全角度考虑,结合 keystone 加一层认证是更好的。
接下来进入带宽控制的主题。
Neutron在以OVS组网时提供的 qos_policy功能实际上调用的是 ovs已有的对挂接在ovs-br上port的bandwidth limit,但只能控制 port 的出流量,是单向的。
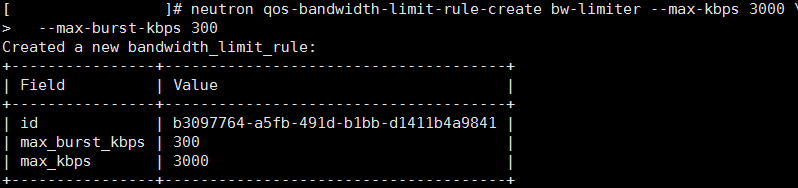
如同:
ovs-vsctl set interface nic-id ingress_policing_rate=xxx
ovs-vsctl set interface nic-id ingress_policing_burst=xxx
底层都绕不开linux TC: Tc (Linux) - Wikipedia
TC规则涉及到队列(queue),分类器(class)和过滤器(filter)三个概念.
队列用来实现控制网络的收发速度.通过队列,linux可以将网络数据包缓存起来,然后根据用户的设置,在尽量不中断连接(如TCP)的前提下来平滑网络流量.需要注意的是,linux对接收队列的控制不够好,所以我们一般只用发送队列,即“控发不控收”,。
class用来表示控制策略.很显然,很多时候,我们很可能要对不同的IP实行不同的流量控制策略,这时候我们就得用不同的class来表示不同的控制策略了.
filter用来将用户划入到具体的控制策略中(即不同的class中).正如前述,我们要对A,B两个IP实行不同的控制策略(C,D),这时,我们可 用filter将A划入到控制策略C,将B划入到控制策略D,filter划分的标志位可用u32打标功能或IPtables的set-mark功能来实 现。
Tc控发不控收,注意发送指的是发出/上传/出网/上行 的意思,因此原生ovs bandwidth limit在单纯的对外提供数据的服务场景下是足够适用的。但是在提供用户上传功能、云主机软件更新等需要下行流量的场景则无法约束,更别提当云主机被入侵,攻击者植入程序产生或作为肉鸡发起对其它被攻击对象的爆发性大规模下行流量了。在做了双向的流量控制后,也更能分担监控、抗D等系统的压力。因此无论是用户业务需求还是平台层考量,双向QoS都是有意义的。
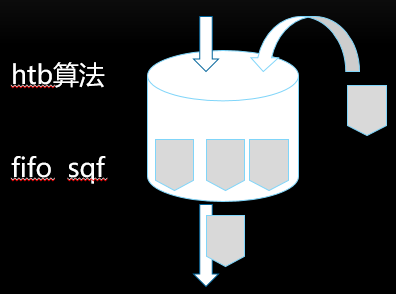
tc中的htb(令牌桶)算法简单描述:
假如用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中;
假设桶最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃;
当一个n个字节的数据包到达时,就从令牌桶中删除n个令牌,并且数据包被发送到网络;
如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外;
算法允许最长b个字节的突发,但从长期运行结果看,数据包的速率被限制成常量r。对于在流量限制外的数据包可以以不同的方式处理:
它们可以被丢弃;
它们可以排放在队列中以便当令牌桶中累积了足够多的令牌时再传输;
它们可以继续发送,但需要做特殊标记,网络过载的时候将这些特殊标记的包丢弃。
注意:令牌桶算法不能与另外一种常见算法“漏桶算法(Leaky Bucket)”相混淆。这两种算法的主要区别在于“漏桶算法”能够强行限制数据的传输速率,而“令牌桶算法”在能够限制数据的平均传输速率外,还允许某种程度的突发传输。在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
在用原生tc代替neutron qos policy时,可以使用两种模式:
1. 云主机模式
即只对云主机做流量控制,这里要提一下计算节点上云主机连接网卡的原理。
在计算节点ip a的话,我们可以看到大量的虚拟网卡,在libvirt的虚机xml文档中,可以明确看到云主机与连接网卡的信息。
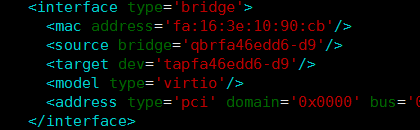
但除了tap设备外,计算节点上还有qvo,qvb,qbr。这些分别是什么呢。
openstack neutron 解释的很详细,可以直接参考。
不难归纳出 上行流量控制:
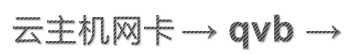 下行流量控制:
下行流量控制:
由前文,tc控制网卡设备的发出流量,所以当我们对上行或下行想做限制的时候,实际tc生效的设备只能是方向路径上的设备。故云主机模式的qos控制,可以分别对 qvo和 qvb设备进行规则写入,即可实现上下行双向控制。
tc qdisc del dev qvo233 root //删除原有规则
tc qdisc add dev qvo233 root handle 1: htb default 100 //创建htb队列
tc class add dev qvo233 parent 1: classid 1:1 htb rate 1gbit //
tc qdisc add dev qvo233 parent 1:1 sfq perturb 10 //sfq队列,避免单会话永占
tc class add dev qvo233 parent 1: classid 1:100 htb rate 10mbit ceil 10mbit //子类100 带宽10mb
tc qdisc add dev qvo233 parent 1:100 sfq perturb 10
tc class add dev qvo233 parent 1: classid 1:101 htb rate 100mbit ceil 100mbit
//子类101 带宽100mb
tc qdisc add dev qvo233 parent 1:101 sfq perturb 10
tc filter add dev qvo233 protocol ip parent 1: prio 1 u32 match ip src 10.0.0.0/8 flowid 1:101
tc filter add dev qvo233 protocol ip parent 1: prio 1 u32 match ip src 172.16.0.0/12 flowid 1:101
tc filter add dev qvo233 protocol ip parent 1: prio 1 u32 match ip src 192.168.0.0/16 flowid 1:101
上面即是对qvo233这个设备的带宽控制,实际为下行规则。默认子类为100 (10mb),但是当源地址为 10.0.0.0/8 和 172.16.0.0/12、192.168.0.0/16 时,使用子类101 (100mb),这样保证私有地址间带宽为百兆,而公网流量的带宽为十兆。
为什么私有地址间的流量也要做限制?是因为即使是用户VPC内云资产产生的东西向流量,仍要占用计算节点物理网卡的实际带宽,以及用于构建 VXLAN 网络的交换机处理能力,考虑到云资产较多的情景,因此是不得不注意的。
顺带一提,公网流量既包含 L3 节点的南北向流量,也包含L3节点上网关路由到实际云资产所在宿主机的东西向流量。 带宽在 L3 处更容易出现瓶颈。
2. VPC模式
对VPC与外网间的流量控制可以更灵活,在系列第一篇里介绍了VPC的路由,而这个路由实际上通过至少两张网卡连接了租户内网与外部网络,
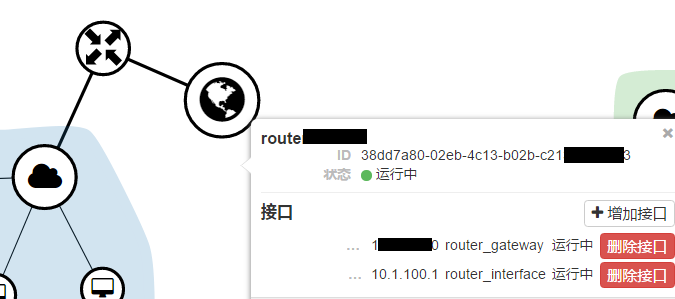
上图左上角的路由,有两张网卡,内连VPC的router_interface 与外连外部网络的 router_gateway。
在 L3_agent上也可以看出来:
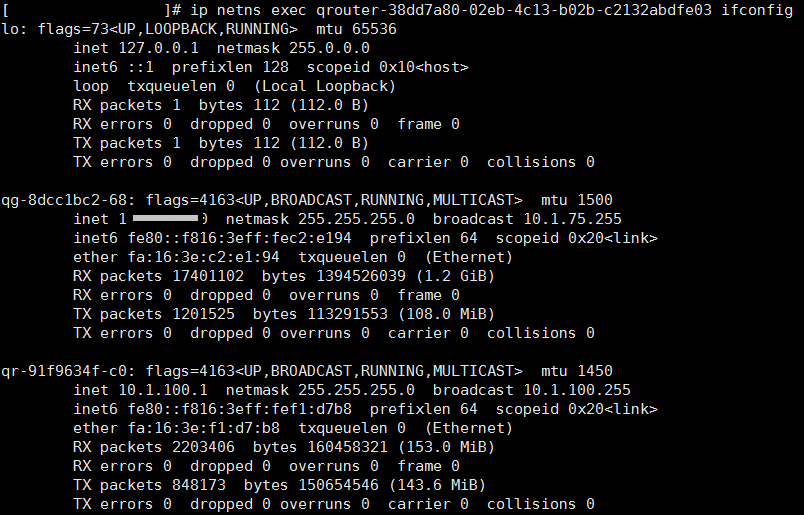
qg为外部网络的网卡,qr为VPC内某一网络的网关。
在限制vpc总体的上行流量时,实际将 tc 规则写在 qg 即可,在限制VPC总体下行流量时,将tc 规则写在 qr 即可。
这是VPC共享带宽的一种思路。
如此实现了VPC内所有云资产的公网流量共享,无需再限制云主机单台的公网带宽,其实这种在公有云场景更满足用户预期,因为这样用户就不必为每一台VPC内的云资产带宽买单,只用支付总体带宽费即可。
在实现了VPC内云资源和外网流量的共享后,就有了新的问题,当发生资源抢占时该怎么办。
如果任由抢占,那么我们使用的随机序列算法就会生效,每隔10秒重新分配队列。
但这对有良好业务规划的用户来说并不合理,用户可能需要某些业务能保持一定的独占性。
所以我们通过对 不同子类带宽的划分 以及 filter 规则的细化,即可实现源或目的不同转发路径的带宽控制,对floating IP 以及 上一篇中的 NAT 功能同样适用 。
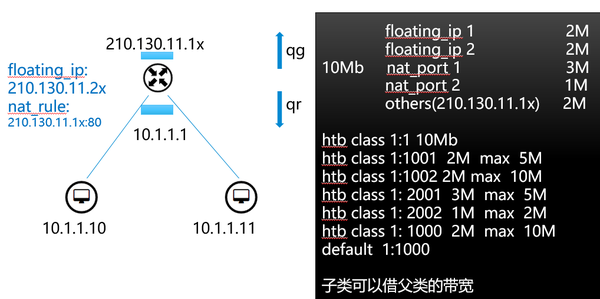
上图的样例设计即可满足 部分云资产的带宽独占性,同时在总共享带宽未满的情况下,可以进行借用的场景功能。
系列下一篇 《深入浅出新一代云网络——VPC中的那些功能与基于OpenStack Neutron的实现(三)》中将给出实现QOS带宽控制的类似开头DNAT功能 rest api 的demo代码,并展开下一块内容——VPC网络中实现互联互通的路由技术与隧道技术,和场景案例。
系列上一篇 :http://www.cnblogs.com/opsec/p/6823437.html
深入浅出新一代云网络——VPC中的那些功能与基于OpenStack Neutron的实现(二)
标签:注意 mat 执行 run 意思 div 重写 ssi block
原文地址:http://www.cnblogs.com/opsec/p/6895746.html