标签:最优 结果 基础 com odi hal object instance 算法
Background
1) “Patch-level image representation”的优势
2) “Patch-level image representation”现存的问题(这里特指与CNN结合方法的问题)
3)object classification and discovery概念
Given an input image and its category labels (e.g., image- level annotations), object classi cation is to learn object classi ers for classifying which object classes (e.g., person) appear in testing images.1 Similar to object detection, object discovery is to learn object detectors for detecting the location of objects in input images, as shown in the bottom of Fig. 1. 如下图所示

4)Multiple Instance Learning (MIL)概念
In MIL, a set of bags and bag labels are given, and each bag consists of a collection of instances, where instances labels are unknown for training. MIL has two constraints: (1) if a bag is positive, at least one instance in the bag should be positive; (2) if a bag is negative, all instances in the bag should be negative. 如果我们将图像理解为bag,patch理解为instance,这样就可以在patch or image -level基础上采用MIL的框架了。
5)本文追求的目标
在只给定image-level annotations的前提下,在MIL框架下实现端到端的网络设计,该网络能够同时完成object classification and discovery(也就是多任务学习)。
Main Points
我们首先看看这篇paper的框架
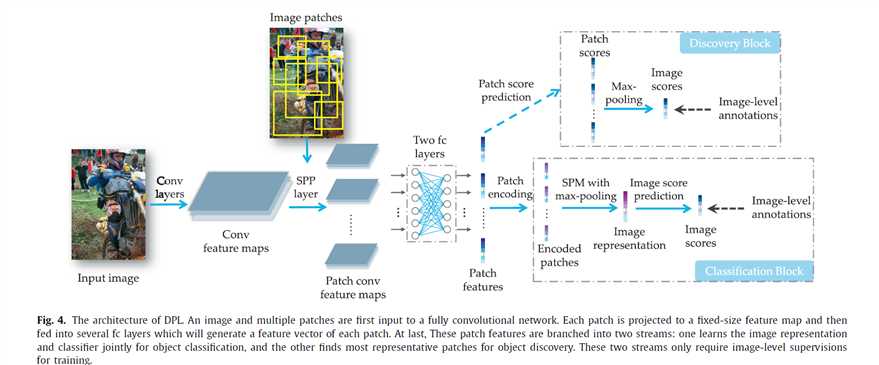
下面我们简单分析一下这个网络结构的要点:
1)采用VGG或者Alexnet生成feature maps,采用Selective Search方法生成Bounding boxes。
2)由于Bounding boxes的大小不一样,因此为了使得大小不同的patch能够输出相同大小的feature maps,作者在网络中引入了SPP layer(该层的作用是生成大小相同的feature maps,此处的大小指的是feature maps的size)。
3)通过全连接层提取每一个patch的feature vector。到此为止,采用的都是基本的CNN building blocks。
4)获取每个patch的feature vector 之后,在效果上,可以通过1x1的卷积核对该feature vector进行降维,也就是上述Patch encoding的过程。
5)在classification block中,因为我们进行object classification,并且我们只有image-level annotations,因此我们的目标是使得image-level annotations能够给我们的网络提供监督信号。很自然的,我们要将这些patch-level的representations转化为image-level的representation。在本文中作者采用的是SPM进行转化,其原理图示如下
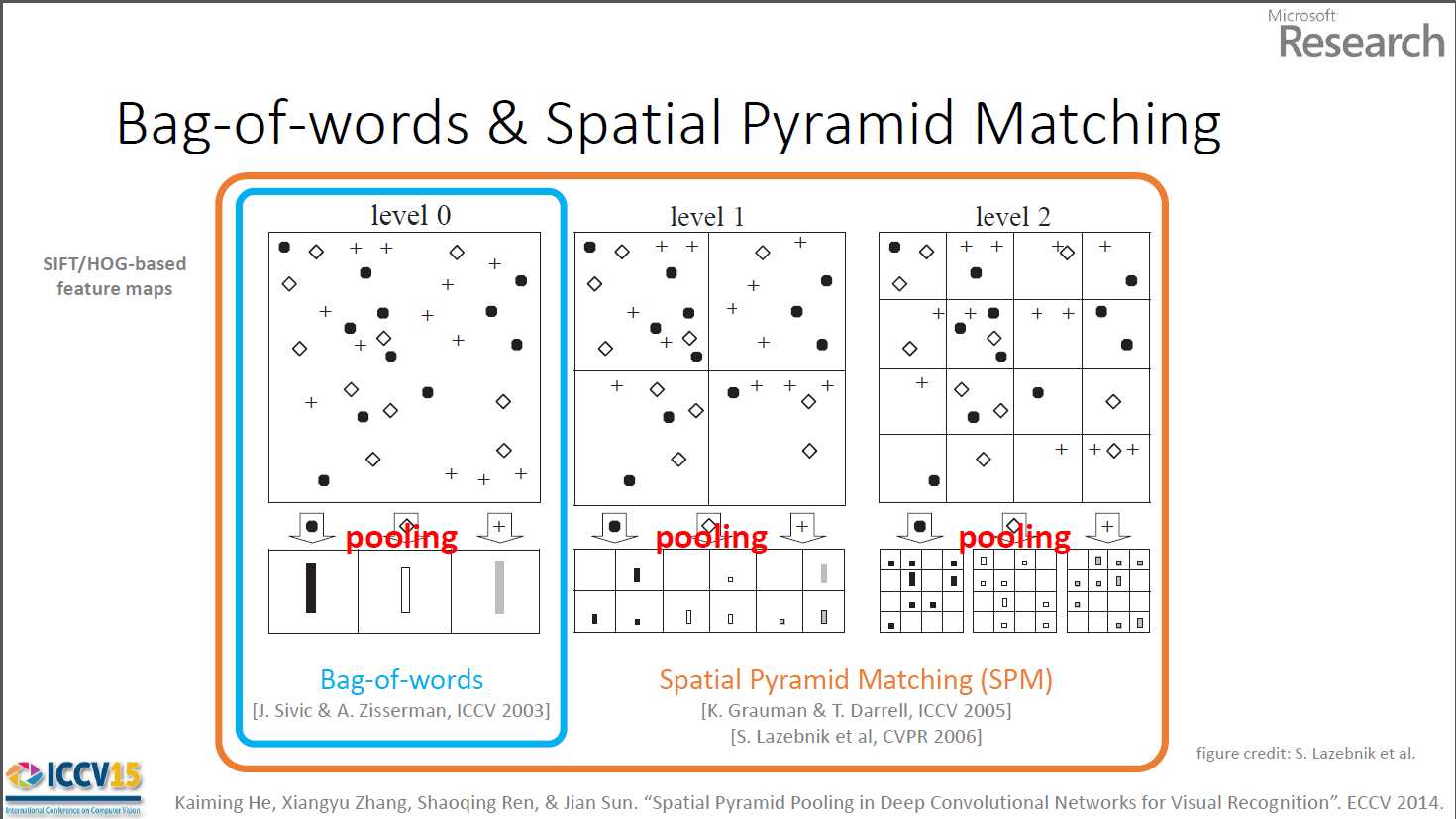
其实质就是将原始图像划分为grid,并对grid内的patch representations进行pooling,这样就可以得到固定的输出维度了。
6)之后就是CNN中常用的分类器和loss函数的选择问题了。
7)我们再来看看网络的另一只Discovery Blcok,其实也很简单,就是直接多每一个patch直接进行分类,然后将分类的结果通过max-pooling的形式整合为image-level的输出,这时就可以和image-level 的 Groundtruth进行对比了。
Summary
1)如何产生Bounding boxes?我们有现成的算法!
2)如果Bounding boxes大小不一致怎么办?我们有SPPlayer!
3)不同的图像可能生成的patch数目不一致,怎么保证这幅图像的image-level representation vector维度固定呢?我们有SPM!
4)对patch score进行max pooling的含义是什么?patch score代表这个patch属于每一类的值(值越大其属于某一类的可能性越大),max pooling就是做了一个选择“认定特定类最大score值对应的patch就是该类”。
5)有一个好想法,采用现有的框架尽快实现,哈哈!
论文笔记 Deep Patch Learning for Weakly Supervised Object Classi cation and Discovery
标签:最优 结果 基础 com odi hal object instance 算法
原文地址:http://www.cnblogs.com/everyday-haoguo/p/Note-DPL.html