标签:put 消息 oba 贝叶斯 images splay default blog 朴素
朴素贝叶斯分类是基于贝叶斯概率的思想,假设属性之间相互独立,求得各特征的概率,最后取较大的一个作为预测结果(为了消弱罕见特征对最终结果的影响,通常会为概率加入权重,在比较时加入阈值)。朴素贝叶斯是较为简单的一种分类器。
属性独立性:事件B的发生不对事件A的发生造成影响,这样的两个事件叫做相互独立事件。然而其属性独立性假设在现实世界中多数不能成立,例如: “spring”的后面更有可能跟着“MVC”。
A和B中至少有一件事情发生:A∪B; A与B同时发生:A∩B(或AB);如果P(AB) =P(A)P(B),称A,B 相互独立。即:从数学上说,若N (N≥2) 个事件相互独立,则必须满足这样的条件:其中任意k (N ≥ k ≥2)个事件同时发生的概率等于该k个事件单独发生时的概率的乘积。
例:假设事件相互独立,P(spring) = 0.2,P(MVC) = 0.8, 则 P(spring MVC) = 0.2 * 0.8=0.16。
很多时候,无法将朴素贝叶斯求得的结果作用于实际,因为朴素的假设(属性之间相互独立)会使其得到错误的结果。
朴素贝叶斯假设各特征项是独立的,整体概率=各特征项概率的乘积,计算出特征集在每个分类的概率后进行比较,最大值即预测结果。
根据概率公式,在实际应用中是:
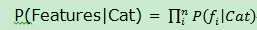
下面以垃圾邮件过滤器为例,描述贝叶斯分类的实际应用。
早期的邮件过滤器使用的基于规则的朴素贝叶斯分类,典型的规则包括:大写的过度使用、与医药相关的单词、过于花哨的HTML等。
这种过滤有两个问题:
1.如果垃圾制造者知道规律就能绕开过滤器,其行为变得更加隐蔽。
2.某些被当作垃圾的分类中某些情况下并不适用(可能是正常内容)。
本例将在开始阶段和逐渐接收到更多消息后,由人们告诉它哪些是垃圾,哪些不是,不断学习后,程序对垃圾信息的界定逐渐形成自己的观点。这是典型的监督学习中的分类。
下面是实现过程的描述:
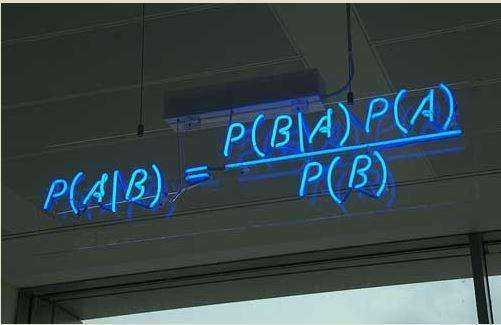
由上图的公式可推导:
P(cat|doc) = P(doc|cat) * P(cat) / P(doc)
= P(FeatureSet|cat) * P(cat) / P(doc)
= [(P(F1|cat) * P(F2|cat) * … * P(Fn|cat)] * P(cat) / P(doc)
= ∏(Fn|cat) * P(cat) / P(doc)
由于绝大多数doc的内容都不同,可认为P(doc)是一个固定值1,计算P(doc)没有意义。由此上式可等价为[(P(F1|cat) * P(F2|cat) * … * P(Fn|cat)] * P(cat)
伪代码:
docProbability = [(P(F1|cat) * P(F2|cat) * … * P(Fn|cat)] * P(cat)
docProbability.setDefaultValue(1)
compute docProbability:
Features.forEach(f -> { docProbability *= P(f|cat)}) = Features.forEach(f->{docProbability *= fc[f][cat] / cc[cat]})
catProbabilty = P(cat) = cc[cat] / cc.all
最终 P(cat|doc) ≈ docProbability / catProbabilty
5. 当训练数据较少时,避免将普通doc归为bad非常重要。为解决这个问题,为每个分类设置阈值。对于一个doc来说,其概率与所有其他分类的概率相比,要大于阈值,即:
P(cat|doc) / P(other|doc) > threshold。
例如:假设过滤到bad的阈值是3, 则当P(bad|doc) / P(good|doc) > 3时才能划分到bad类中。
如果good的阈值是1, 则 P(good|doc) > P(bad|doc)是就能划分到good类中。
对于 1 < P(bad|doc) / P(good|doc) < 3, 划分到unknow,可令unknow = good。
函数predict(doc) 是最终暴露的方法,使用threshold处理分类。
6.添加训练集,使用predict方法判断测试项属于哪个分类。
参考文献:
《集体智慧编程》
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
标签:put 消息 oba 贝叶斯 images splay default blog 朴素
原文地址:http://www.cnblogs.com/bigmonkey/p/7306125.html