标签:style set utf-8 span 中文 imp 下载 read com
中文分词
import jieba book=open(‘F:\\xiyouji.txt‘,‘r‘,encoding=‘utf-8‘) #读入待分析的字符串 str=book.read() book.close() for i in ‘,。!、 \n “ ” ;‘: str=str.replace(i,‘‘) words=jieba.cut(str) word=set(words) #计数字典 dic={} for i in word: if len(i)>1: dic[i]=str.count(i) str=list(dic.items()) #排序 str.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(str[i])
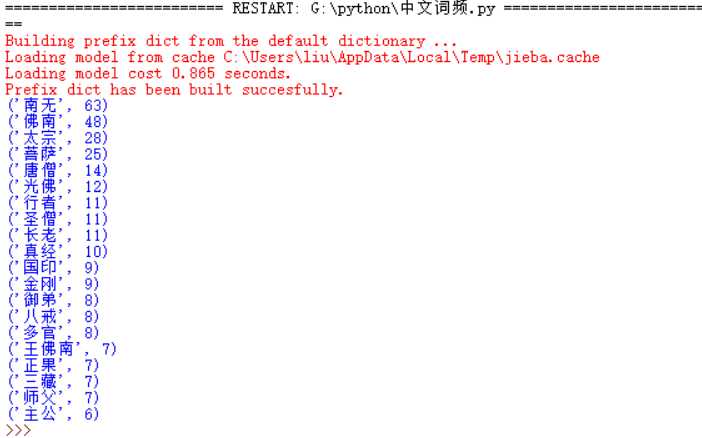
从词频统计结果出来可以看出此小说是西游记,主要人物有唐僧,八戒等,讲述他们取西经的过程。
标签:style set utf-8 span 中文 imp 下载 read com
原文地址:http://www.cnblogs.com/lkm123/p/7610574.html