标签:变化 情况下 自身 图片 多项式拟合 简单 估计 upload 统一
这是关于PRML第二章的学习笔记。主要从内容思想的理解,具体的理论推导需要结合原文以及概率论的知识。这一章主要讲概率分布,概率分布的?个作?是在给定有限次观测x1, … , xN的前提下,对随机变量x的概率分布p(x)建模。这个问题被称为密度估计,分为二元 多元 高斯 以及先验分布 beta 狄利克雷分布,最后将这些分布统一到指数簇家族一类中。
引言:概率分布分为两个经典学派,频率学派和贝叶斯学派。 频率学派关注数据,认为数据是不会说谎的,一切以数据为中心,采用最大似然函数来求取data 的概率。而贝叶斯学派则认为数据是不完全准确的,有些是数据的测量误差,有些是无法避免的仪器误差,或者说测量时有其他因素的干扰,总之一句话,数据不完全可信。所以贝叶斯会默认给数据添加一份先验概率,这是一份经验知识。而证实贝叶斯有效的就是第一章里的多项式拟合里的损失函数。当我们的先验知识是有效的,贝叶斯会非常有效,一般会是这样的,但如果先验知识无效,或者说这种先验知识是有局限性条件时,贝叶斯反而会造成更大误差。比若说投硬币,默认大家认识的硬币就是0.5 0.5 的概率,但如果这种硬币有问题,投硬币的概率是0.4 0.6,但如果你还是加入0.5 0.5的先验进去,那就不行了。
一、 二元变量(?元随机变量x ∈ {0, 1})
1, 伯努利分布与二项分布
伯努利分布(Bernoulli distribution)又名两点分布或0-1分布。伯努利试验是只有两种可能结果的单次随机试验,即对于一个随机变量X而言,x的概率分布。

二项分布(Binomial distribution)是n重伯努利试验成功次数的离散概率分布。如果试验E是一个n重伯努利试验,每次伯努利试验的成功概率为p,X代表成功的次数,则X的概率分布是二项分布,记为X~B(n,p)
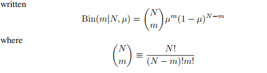
2, Beta分布(二项分布的先验分布)(后验概率分布(正?于先验和似然函数的乘积)就会有着与先验分布相同的函数形式。这个性质被叫做共轭性(conjugacy))。数据少时用最大似然方法估计参数会过拟合,而贝叶斯方法认为模型参数有一个先验分布,因此共轭分布在贝叶斯方法中很重要,现在看二项式分布的共轭分布beta分布:

二、多项式变量:?元变量可以?来描述只能取两种可能值中的某?种这样的量。然?,我们经常会遇到可以取K个互斥状态中的某?种的离散变量。
1,多项式分布:由K个互斥变量的分布以及最大最大似然估计引入:m1, … ,mK在参数μ和观测总数N条件下的联合分布,多项式分布:

2, 狄利克雷分布(多项式的先验分布)

三、高斯分布:
1,高斯分布的介绍
(1)高斯分布的定义
?斯分布,也被称为正态分布,?泛应?于连续型随机变量分布的模型中。根据中心极限定理,大量随机变量的和呈正态分布,这样解释了随机误差是正态分布的原因。对于?元变量x的情形,?斯分布可以写成下?的形式:
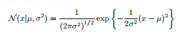
多元高斯分布:
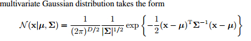
(2)高斯分布的几何理解:也就是我们平时看到的高斯分布是有一些规则或不规则的等高线表示
先给出样本到均值的马氏距离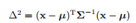
把协方差矩阵的逆 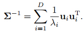 带入上式
带入上式
会得到以协方差矩阵的特征值平方根为轴长的标准椭圆方程 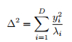
其中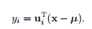
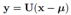
也就是原来的坐标系经过平移和旋转,由协方差矩阵特征向量组成的矩阵U负责旋转坐标轴:
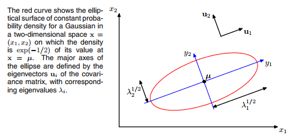
(3)介绍了高斯分布坐标变化后的形式,以及高斯分布的炬,同时分析了高斯分布的缺点(参数多,单峰)
2,条件高斯分布和边缘高斯分布,同时引出?斯变量的贝叶斯定理,这两个分布由高斯分布组成,自身也是高斯分布。(推导过程使用矩阵的变换完成,具体看原文):令x中的?阶项的系数矩阵等于协?差矩阵的逆矩阵Σ?1,令x中的线性项的系数等于Σ?1μ,这样我们就可以得到μ。
3,高斯分布的参数估计:极大似然估计、顺序估计。
极大似然估计就是最大化我们的似然函数。顺序估计每次考虑一个数据,通过递推公式进行参数更新,者更适合于有先验概率的贝叶斯方法。(同时也给出了一种通用的顺序估计方法)
4,高斯分布的贝叶斯推断:假定数据集的?斯分布的?差是已知的,?标是推断均值,它的先验分布是高斯分布。相反,假设均值是已知的,我们要推断?差,先验分布是Gam(λ | aN, bN)的Gamma分布,
5,混合高斯分布
通过将更基本的概率分布(例如?斯分布)进?线性组合的这样的叠加?法,可以被形式化为概率模型,被称为混合模型。?斯分布的线性组合可以给出相当复杂的概率密度形式。考虑K个?斯概率密度的叠加,混合高斯模型。
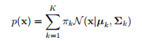
四、指数族分布:很多分布包括我们上面提到的二项式分布、beta分布、多项式分布、狄利克雷分布、高斯分布都可以转换成这种指数族的形式:其中η是参数,g(η)是归一化因子,u(x)是x的函数。
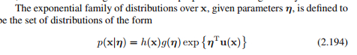
1,指数族分布的似然估计:
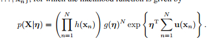
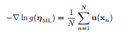
其中,我们收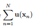 为充分统计量
为充分统计量
2,指数族分布的共轭先验分布,以及后验分布
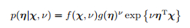

3,无信息先验:可以寻找?种形式的先验分布,被称为?信息先验。这种先验分布的?的是尽量对后验分布产?尽可能?的影响。这有时被称为“让数据??说话”。如果我们有?个由参数λ控制的分布p(x | λ),那么我们可以尝试假设先验分布p(λ) = 常数作为?个合适的先验分布。如果λ是?个有K个状态的离散变量,这就相当于把每种状态的先验概率设置为1/K。(分别介绍了平移不变性和缩放不变性两个实例)
五、非参数化方法:
前面概率分布都有具体的函数形式,并且由少量的参数控制。这些参数的值可以由数据集确定。这被称为概率密度建模的参数化(parametric)?法。这种?法的?个重要局限性是选择的概率密度可能对于?成数据来说,是?个很差的模型,从?会导致相当差的预测表现。从而提出非参数化方法。
1,密度估计的直方图方法:简单地把观测数量除以观测的总数N,再除以箱?的宽度Δi,得到每个箱?的概率的值。第?,为了估计在某个特定位置的概率密度,我们应该考虑位于那个点的某个邻域内的数据点。第?,为了获得好的结果,平滑参数的值既不能太?也不能太?。
2,核密度估计的方法与近邻?法:密度估计的形式:p(x) =K/NV
我们可以固定K然后从数据中确定V 的值,这就是K近邻?法。我们还可以固定V 然后从数据中确定K,这就是核?法。在极限N →∞的情况下,如果V 随着N?合适地收缩,并且K随着N增?,那么可以证明K近邻概率密度估计和核?法概率密度估计都会收敛到真实的概率密度。
核密度估计方法就是用核函数计数来代替K值。此我们回到局部概率密度估计的?般结果(2.246)。与之前固定V 然后从数据中确定K的值不同,我们考虑固定K的值然后使?数据来确定合适的V 值。k邻近方法,考虑?个以x为中?的?球体,然后我们想估计概率密度p(x)。并且,允许球体的半径可以?由增长,直到它精确地包含K个数据点。这样,概率密度p(x)的估计就可以得出,其中V 等于最终球体的体积。
k邻近密度估计可以分析出k邻近分类为什么选择最近k个对象最多分类的类型-最小化错误分类的概率
标签:变化 情况下 自身 图片 多项式拟合 简单 估计 upload 统一
原文地址:http://blog.csdn.net/u014248127/article/details/78777043