标签:迭代 psi 好处 输出 改进 性能 oid 现象 margin
增加了候选区域选择,先选择几个候选区,然后在候选区中做检测。
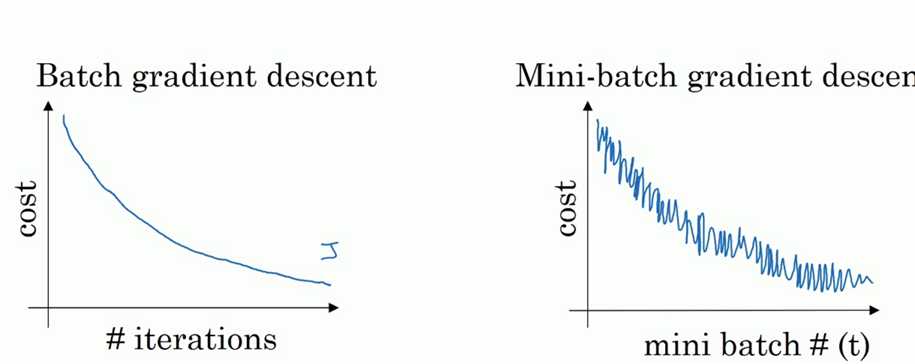
我们已知在梯度下降中需要对所有样本进行处理过后然后走一步,那么如果我们的样本规模的特别大的话效率就会比较低。假如有500万,甚至5000万个样本(在我们的业务场景中,一般有几千万行,有些大数据有10亿行)的话走一轮迭代就会非常的耗时。这个时候的梯度下降叫做full batch。 所以为了提高效率,我们可以把样本分成等量的子集。 例如我们把100万样本分成1000份, 每份1000个样本, 这些子集就称为mini batch。然后我们分别用一个for循环遍历这1000个子集。 针对每一个子集做一次梯度下降。 然后更新参数w和b的值。接着到下一个子集中继续进行梯度下降。 这样在遍历完所有的mini batch之后我们相当于在梯度下降中做了1000次迭代。 我们将遍历一次所有样本的行为叫做一个 epoch,也就是一个世代。 在mini batch下的梯度下降中做的事情其实跟full batch一样,只不过我们训练的数据不再是所有的样本,而是一个个的子集。 这样在mini batch我们在一个epoch中就能进行1000次的梯度下降,而在full batch中只有一次。 这样就大大的提高了我们算法的运行速度。
如上图,左边是full batch的梯度下降效果。 可以看到每一次迭代成本函数都呈现下降趋势,这是好的现象,说明我们w和b的设定一直再减少误差。 这样一直迭代下去我们就可以找到最优解。 右边是mini batch的梯度下降效果,可以看到它是上下波动的,成本函数的值有时高有时低,但总体还是呈现下降的趋势。 这个也是正常的,因为我们每一次梯度下降都是在min batch上跑的而不是在整个数据集上。 数据的差异可能会导致这样的效果(可能某段数据效果特别好,某段数据效果不好)。但没关系,因为他整体的是呈下降趋势的。
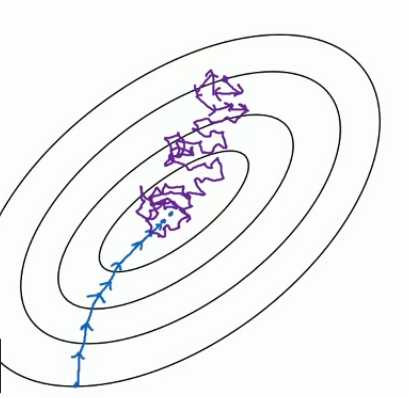
下面的蓝色的部分是full batch的而上面是mini batch。 就像上面说的mini batch不是每次迭代损失函数都会减少,所以看上去好像走了很多弯路。 不过整体还是朝着最优解迭代的。 而且由于mini batch一个epoch就走了5000步,而full batch一个epoch只有一步。所以虽然mini batch走了弯路但还是会快很多。
自从2012年以来,CNN网络模型取得了非常大的进步,而这些进步的推动条件往往就是模型深度的增加。从AlexNet的几层,到VGG和GoogleNet的十几层,甚至到ResNet的上百层,网络模型不断加深,取得的效果也越来越好,然而网络越深往往就越难以训练。我们知道,CNN网络在训练的过程中,前一层的参数变化影响着后面层的变化(因为前面层的输出是后面的输入),而且这种影响会随着网络深度的增加而不断放大。在CNN训练时,绝大多数都采用mini-batch使用随机梯度下降算法进行训练,那么随着输入数据的不断变化,以及网络中参数不断调整,网络的各层输入数据的分布则会不断变化,那么各层在训练的过程中就需要不断的改变以适应这种新的数据分布,从而造成网络训练困难,难以拟合的问题。
(可以这样想,比如网络中每一层都是一个人,今天前面一层的人说要你往左走3,明天有让你往左走2,第三天又让你往右走5,结果三天下来,你还在原地,这样就让你的进度变慢了。PS:我是这样理解的,如有问题,请指出)
BN算法解决的就是这样的问题,他通过对每一层的输入进行归一化,保证每层的输入数据分布是稳定的,从而达到加速训练的目的。
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。

1.用卷积在每个格子检验
2.输出标签为【x, y, w, h, c】,在吴恩达的网易云公开课上优势另一种说法
3.非极大值抑制算法选择框
1.梯度消失
我们知道,神经网络的优化都是通过梯度下降的方法来优化的。每次我正向计算的时候计算出Loss,然后我需要知道,究竟怎样调整参数矩阵才能使得我的Loss更小,预测和事实更接近,所以我们需要通过back propogation来对传播梯度,但是在传播的过程中,会出现一些我们没有预料到的问题。
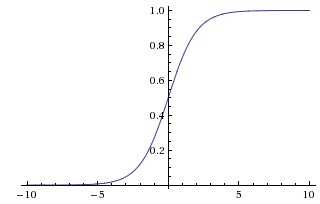
这是Sigmoid的函数图像,我们可以看到,Sigmoid函数把[-INF,INF]上的值映射到了[-1,1]之间。这个映射可以增加非线性性,但是有个问题,就是当输入值足够大或者足够小的时候,输出值基本上不变,这个时候函数的梯度值基本上为0。这就达不到梯度下降的功能了
为了解决这个问题,引入了新的非线性单元,ReLU。其实表达式也非常简单。我们可以看到,不管输入值多大,梯度值都是存在的,这就在一定程度上解决了梯度消失的问题,因而ReLU也比Sigmoid在性能上要更好。.
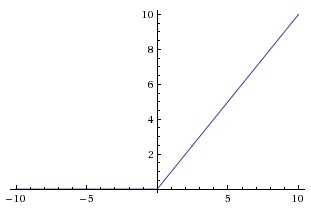
但是因为梯度连乘的问题,梯度消失的问题依然存在。我们通过正常的back propagation进行计算,
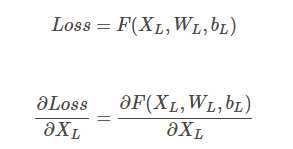
但是这个时候,如果网络很深很深,就会出现这样的情况
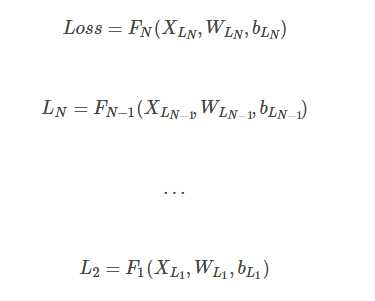
这个时候再做back propagation求偏导的话,就是
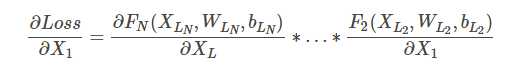
这个偏导就是我们求的gradient,这个值本来就很小,而且再计算的时候还要再乘stepsize,就更小了
所以通过这里可以看到,梯度在反向传播过程中的计算,如果N很大,那么梯度值传播到前几层的时候就会越来越小,也就是梯度消失的问题
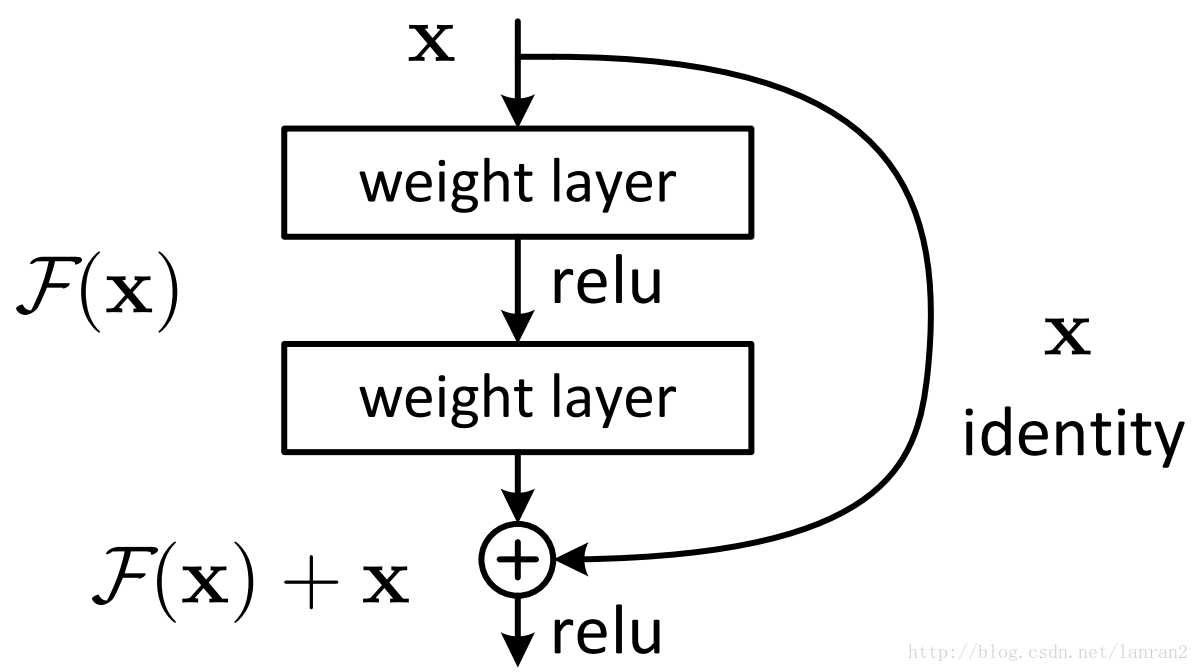
所以这个时候,DRN就出现了,它在神经网络结构的层面解决了这个问题
它将基本的单元改成了这个样子
其实也很明显,通过求偏导我们就能看到
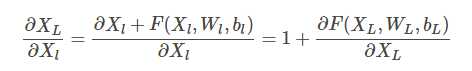
这样就算深度很深,梯度也不会消失了。
v1:
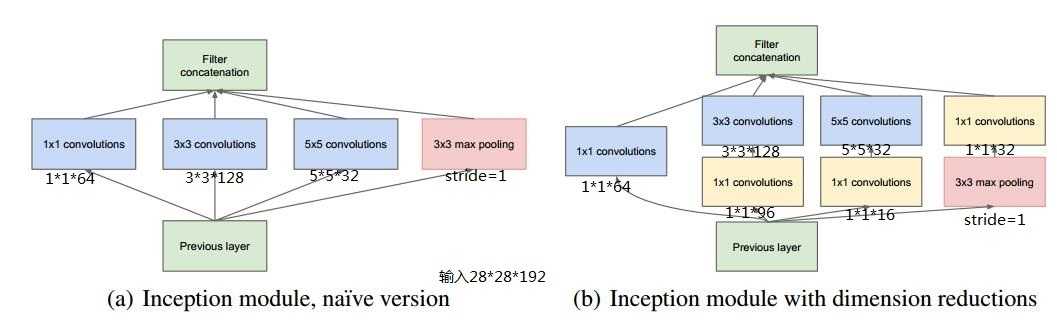
主要提出了Inceptionmodule结构(1*1,3*3,5*5的conv和3*3的pooling组合在一起),最大的亮点就是从NIN(Network in Network)中引入了1*1 conv
v2:
(1)加入了BN层,减少了InternalCovariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,从而增加了模型的鲁棒性,可以以更大的学习速率训练,收敛更快,初始化操作更加随意,同时作为一种正则化技术,可以减少dropout层的使用。
(2)用2个连续的3*3 conv替代inception模块中的5*5,从而实现网络深度的增加,网络整体深度增加了9层,缺点就是增加了25%的weights和30%的计算消耗。
v3:
(1) 将7*7分解成两个一维的卷积(1*7,7*1),3*3也是一样(1*3,3*1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,更加精细设计了35*35/17*17/8*8的模块。
(2)增加网络宽度,网络输入从224*224变为了299*299。
v4:
主要利用残差连接(Residual Connection)来改进v3结构。将Inception模块和ResidualConnection结合,提出了Inception-ResNet-v1,Inception-ResNet-v2,使得训练加速收敛更快,精度更高。
标签:迭代 psi 好处 输出 改进 性能 oid 现象 margin
原文地址:https://www.cnblogs.com/yuanninesuns/p/8921955.html