标签:技术分享 1.3 结构 格式 open ora sheet 知识点 客户
本课程难度为一般,属于初级级别课程,适合具有hadoop基础的用户。
https://pan.baidu.com/s/1a_Pjl8uJ2d_-r1hbN05fWA
(若文件中没有添加的配置项,则系统为默认值,不会对该实验产生影响)
.bashrc:由于平台环境与该实验hadoop版本不匹配问题,需要对.bashr文件中末尾处的环境变量做修改
$ vim /home/hadoop/.bashrc
修改为:
export HADOOP_HOME=/home/hadoop/hdfs
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/hadoop/hdfs/bin:/home/hadoop/hdfs/sbin
由于本实验不会用到hbase和hive,所以相关环境变量删除。
提醒:修改了配置文件后,如何使变量生效?上一节我们有使用到过,大家自行回顾一下。
core-site.xml:$ vim/home/hadoop/hdfs/etc/hadoop/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
常用配置项说明:
fs.defaultFS这是默认的HDFS路径。当有多个HDFS集群同时工作时,用户在这里指定默认HDFS集群,该值来自于hdfs-site.xml中的配置。fs.default.name这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在/tmp/hadoop-${user.name}这个路径中。更多说明请参考core-default.xml,包含配置文件所有配置项的说明和默认值。
hdfs-site.xml:$ vim/home/hadoop/hdfs/etc/hadoop/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
常用配置项说明:
dfs.replication它决定着系统里面的文件块的数据备份个数。对于一个实际的应用,它应该被设为3(这个数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)dfs.data.dir这是DataNode结点被指定要存储数据的本地文件系统路径。DataNode结点上的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的值为file://${hadoop.tmp.dir}/dfs/data这个路径只能用于测试的目的,因为它很可能会丢失掉一些数据。所以这个值最好还是被覆盖。dfs.name.dir这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。更多说明请参考hdfs-default.xml,包含配置文件所有配置项的说明和默认值。
mapred-site.xml:$ cp/home/hadoop/hdfs/etc/hadoop/mapred-site.xml.template/home/hadoop/hdfs/etc/hadoop/mapred-site.xml
$ vim/home/hadoop/hdfs/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
常用配置项说明:
mapred.job.trackerJobTracker的主机(或者IP)和端口。更多说明请参考mapred-default.xml,包含配置文件所有配置项的说明和默认值
yarn-site.xml:$ vim/home/hadoop/hdfs/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
常用配置项说明:
yarn.nodemanager.aux-services通过该配置,用户可以自定义一些服务更多说明请参考yarn-default.xml,包含配置文件所有配置项的说明和默认值
hadoop-env.sh:$ sudo vim/home/hadoop/hdfs/etc/hadoop/hadoop-env.sh
修改 JAVA_HOME 如下:
exportJAVA_HOME=/usr/lib/jvm/java-8-oracle
exportHADOOP_CONF_DIR=/home/hadoop/hdfs/etc/hadoop
这样简单的伪分布式模式就配置好了。
在使用hadoop前,必须格式化一个全新的HDFS安装,通过创建存储目录和NameNode持久化数据结构的初始版本,格式化过程创建了一个空的文件系统。由于NameNode管理文件系统的元数据,而DataNode可以动态的加入或离开集群,因此这个格式化过程并不涉及DataNode。同理,用户也无需关注文件系统的规模。集群中DataNode的数量决定着文件系统的规模。DataNode可以在文件系统格式化之后的很长一段时间内按需增加。
$ hadoop namenode -format
会输出如下信息,则表格式化HDFS成功:
DEPRECATED: Use ofthisscript to execute hdfs commandisdeprecated.
Instead use the hdfs commandforit.
INFO namenode.NameNode: STARTUP_MSG:/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = [你的主机名]/[你的ip]
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.6
...
...
INFO util.GSet: Computing capacity for map NameNodeRetryCache
INFO util.GSet: VM type = 64-bit
INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
INFO util.GSet: capacity = 2^15 = 32768 entries
INFO namenode.NNConf: ACLs enabled? false
INFO namenode.NNConf: XAttrs enabled? true
INFO namenode.NNConf: Maximum size of an xattr: 16384
INFO namenode.FSImage: Allocated new BlockPoolId: BP-549895748-192.168.42.3-1489569976471
INFO common.Storage: Storage directory /home/hadoop/hadop2.6-tmp/dfs/name has been successfully formatted.
INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
NFO util.ExitUtil: Exiting with status 0
INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at [你的主机名]//[你的ip]
************************************************************/
hadoop@c81af9a07ade:/opt/hadoop-2.7.6/bin$ jps
$ start-dfs.sh
输出如下(可以看出分别启动了namenode, datanode, secondarynamenode,因为我们没有配置secondarynamenode,所以地址为0.0.0.0):
Starting namenodeson[]
hadoop@localhost‘spassword:
localhost: starting namenode, loggingto/usr/local/hadoop/logs/hadoop-hadoop-namenode-G470.out
hadoop@localhost‘spassword:
localhost: starting datanode, loggingto/usr/local/hadoop/logs/hadoop-hadoop-datanode-G470.out
localhost: OpenJDK64-BitServer VMwarning: You have loadedlibrary/usr/local/hadoop/lib/native/libhadoop.so.1.0.0which might have disabled stack guard. The VM will trytofix the stack guard now.
localhost: It‘shighly recommended that you fix thelibrarywith‘execstack-c <libfile>‘,orlink itwith‘-z noexecstack‘.
Starting secondary namenodes [0.0.0.0]
hadoop@0.0.0.0‘spassword:
0.0.0.0: starting secondarynamenode, loggingto/usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-G470.out
$ start-yarn.sh
打开浏览器
http://localhost:8088进入ResourceManager管理页面http://localhost:50070进入HDFS页面启动伪分布后,如果活跃节点显示为零,说明伪分布没有真正的启动。原因是有的时候数据结构出现问题会造成无法启动datanode。如果使用hadoop namenode -format重新格式化仍然无法正常启动,原因是/tmp中的文件没有清除,则需要先清除/tmp/hadoop/*再执行格式化,即可解决hadoop datanode无法启动的问题。具体步骤如下所示:
# 删除hadoop:/tmp
$ hadoop fs -rmr /tmp
# 停止hadoop
$ stop-all.sh
# 删除/tmp/hadoop*
$ rm -rf /tmp/hadoop*
# 格式化
$ hadoop namenode -format
# 启动hadoop
$ start-all.sh
测试验证还是使用上一节的 WordCount。
不同的是,这次是伪分布模式,使用到了 hdfs,因此我们需要把文件拷贝到 hdfs 上去。
首先创建相关文件夹(要一步一步的创建):
$ hadoop dfs -mkdir /user$ hadoop dfs -mkdir /user/hadoop$ hadoop dfs -mkdir /user/hadoop/input创建多层目录的简便方法:
$ hadoop dfs -mkdir-p /user/hadoop/input
先将文件拷贝到 hdfs 上:
$ hadoop dfs -put/etc/protocols/user/hadoop/input

# 如果存在上一次测试生成的output,由于hadoop的安全机制,直接运行可能会报错,所以请手动删除上一次生成的output文件夹
$ hadoop jar/home/hadoop/hdfs/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.6-sources.jar wordcount/user/hadoop/input output
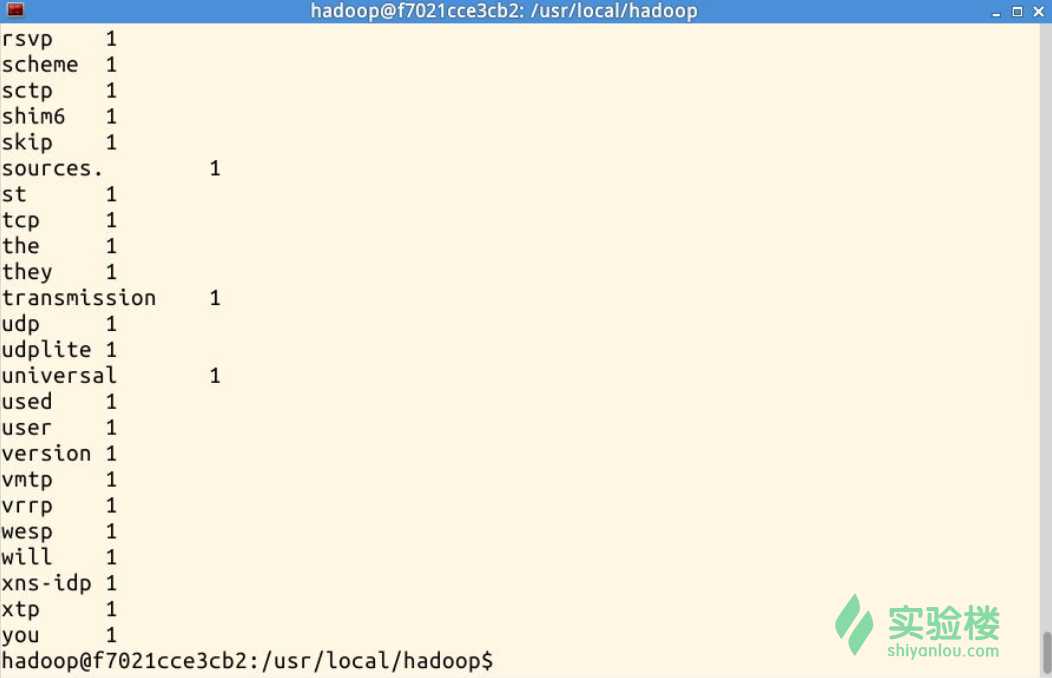
执行过程截图(部分):
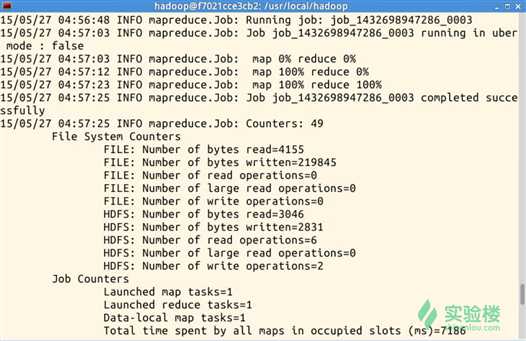
$ hadoop dfs -cat/user/hadoop/output/*
$ stop-dfs.sh
$ stop-yarn.sh
本实验讲解如何在单机模式下继续部署Hadoop为伪分布模式。
伪分布模式和单机模式配置上的区别主要是哪些?是否可以推论出如何部署真实的分布式Hadoop环境?
本实验参考下列文档内容制作:
实验楼练习平台:http://www.shiyanlou.com/register?inviter=NTY0MzE5NjA1NjM3
标签:技术分享 1.3 结构 格式 open ora sheet 知识点 客户
原文地址:https://www.cnblogs.com/AndyWong/p/9201645.html