标签:unsafe EAP 使用 location 不同 res 表示 key ble
假如我们有个 spark job 依赖关系如下
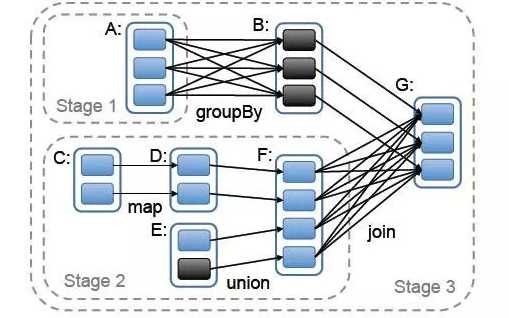
我们抽象出来其中的rdd和依赖关系:
E <-------n------, C <--n---D---n-----F--s---, A <-------s------ B <--n----`-- G
对应的划分后的RDD结构为:
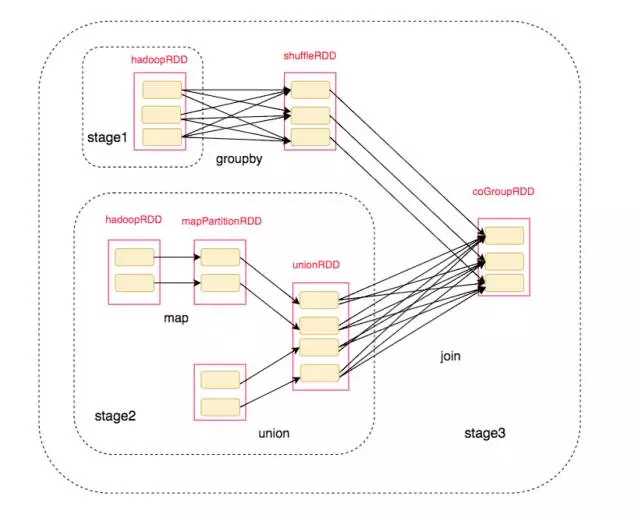
最终我们得到了整个执行过程:
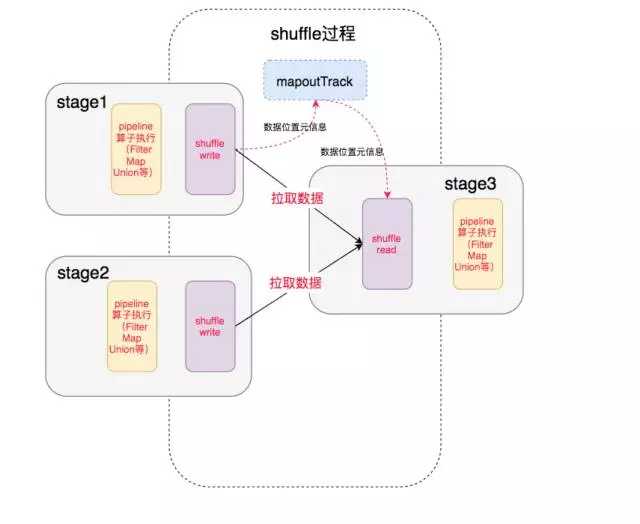
中间就涉及到shuffle 过程,前一个stage 的 ShuffleMapTask 进行 shuffle write, 把数据存储在 blockManager 上面, 并且把数据位置元信息上报到 driver 的 mapOutTrack 组件中, 下一个 stage 根据数据位置元信息, 进行 shuffle read, 拉取上个stage 的输出数据。
这篇文章讲述的就是其中的 shuffle write 过程。
Spark 0.8及以前 Hash Based Shuffle
Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
Spark 0.9 引入ExternalAppendOnlyMap
Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle
Spark 1.4 引入Tungsten-Sort Based Shuffle
Spark 1.6 Tungsten-sort并入Sort Based Shuffle
Spark 2.0 Hash Based Shuffle退出历史舞台
总结一下, 就是最开始的时候使用的是 Hash Based Shuffle, 这时候每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M R ,其中M是Map的个数,R是Reduce的个数。这样会产生大量的小文件,对文件系统压力很大,而且也不利于IO吞吐量。后面忍不了了就做了优化,把在同一core上运行的多个Mapper 输出的合并到同一个文件,这样文件数目就变成了 cores R 个了,
举个例子:
本来是这样的,3个 map task, 3个 reducer, 会产生 9个小文件,
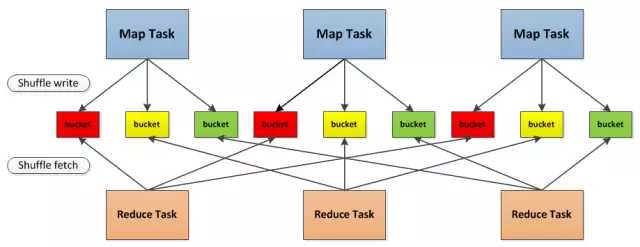
是不是很恐怖, 后面改造之后
4个map task, 4个reducer, 如果不使用 Consolidation机制, 会产生 16个小文件。
但是但是现在这 4个 map task 分两批运行在 2个core上, 这样只会产生 8个小文件
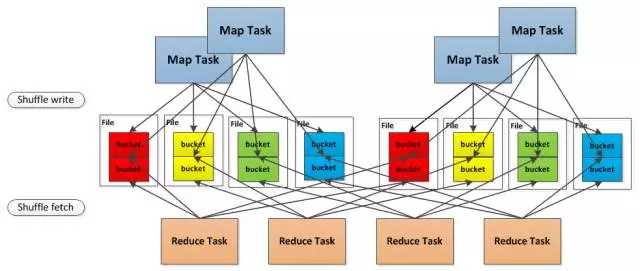
在同一个 core 上先后运行的两个 map task的输出, 对应同一个文件的不同的 segment上, 称为一个 FileSegment, 形成一个 ShuffleBlockFile,
后面就引入了 Sort Based Shuffle, map端的任务会按照Partition id以及key对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件, 再后面就就引入了 Tungsten-Sort Based Shuffle, 这个是直接使用堆外内存和新的内存管理模型,节省了内存空间和大量的gc, 是为了提升性能。
现在2.1 分为三种writer, 分为 BypassMergeSortShuffleWriter, SortShuffleWriter 和 UnsafeShuffleWriter,顾名思义,大家应该可以对应上,我们本着过时不讲的原则, 本文中只描述这三种 writer 的实现细节, Hash Based Shuffle 已经退出历史舞台了,我就不讲了。
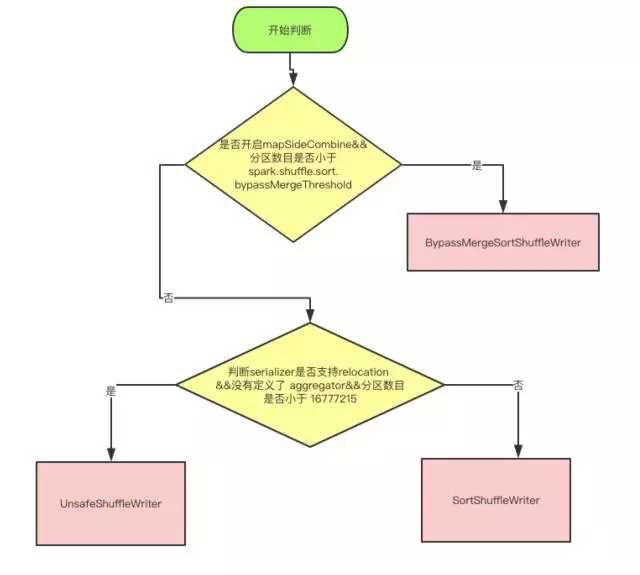
上面是使用哪种 writer 的判断依据, 是否开启 mapSideCombine 这个判断,是因为有些算子会在 map 端先进行一次 combine, 减少传输数据。 因为 BypassMergeSortShuffleWriter 会临时输出Reducer个(分区数目)小文件,所以分区数必须要小于一个阀值,默认是小于200。
UnsafeShuffleWriter需要Serializer支持relocation,Serializer支持relocation:原始数据首先被序列化处理,并且再也不需要反序列,在其对应的元数据被排序后,需要Serializer支持relocation,在指定位置读取对应数据。
BypassMergeSortShuffleWriter和Hash Shuffle中的HashShuffleWriter实现基本一致, 唯一的区别在于,map端的多个输出文件会被汇总为一个文件。 所有分区的数据会合并为同一个文件,会生成一个索引文件,是为了索引到每个分区的起始地址,可以随机 access 某个partition的所有数据。
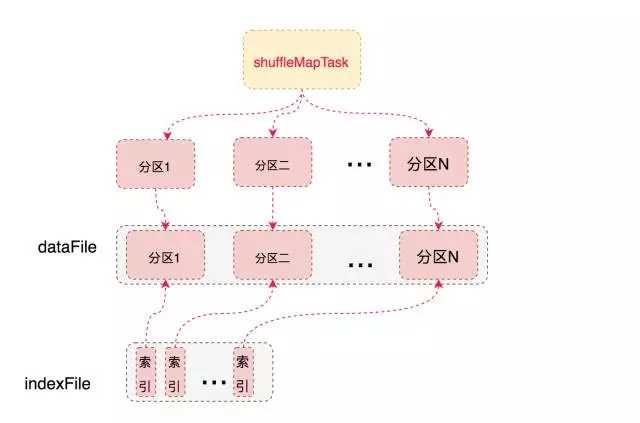
但是需要注意的是,这种方式不宜有太多分区,因为过程中会并发打开所有分区对应的临时文件,会对文件系统造成很大的压力。
具体实现就是给每个分区分配一个临时文件,对每个 record的key 使用分区器(模式是hash,如果用户自定义就使用自定义的分区器)找到对应分区的输出文件句柄,直接写入文件,没有在内存中使用 buffer。 最后copyStream方法把所有的临时分区文件拷贝到最终的输出文件中,并且记录每个分区的文件起始写入位置,把这些位置数据写入索引文件中。
我们可以先考虑一个问题,假如我有 100亿条数据,但是我们的内存只有1M,但是我们磁盘很大, 我们现在要对这100亿条数据进行排序,是没法把所有的数据一次性的load进行内存进行排序的,这就涉及到一个外部排序的问题,我们的1M内存只能装进1亿条数据,每次都只能对这 1亿条数据进行排序,排好序后输出到磁盘,总共输出100个文件,最后怎么把这100个文件进行merge成一个全局有序的大文件。我们可以每个文件(有序的)都取一部分头部数据最为一个 buffer, 并且把这 100个 buffer放在一个堆里面,进行堆排序,比较方式就是对所有堆元素(buffer)的head元素进行比较大小, 然后不断的把每个堆顶的 buffer 的head 元素 pop 出来输出到最终文件中, 然后继续堆排序,继续输出。如果哪个buffer 空了,就去对应的文件中继续补充一部分数据。最终就得到一个全局有序的大文件。
如果你能想通我上面举的例子,就差不多搞清楚sortshufflewirter的实现原理了,因为解决的是同一个问题。
SortShuffleWriter 中的处理步骤就是
使用 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 在内存中进行排序, 排序的 K 是(partitionId, hash(key)) 这样一个元组。
如果超过内存 limit, 我 spill 到一个文件中,这个文件中元素也是有序的,首先是按照 partitionId的排序,如果 partitionId 相同, 再根据 hash(key)进行比较排序
如果需要输出全局有序的文件的时候,就需要对之前所有的输出文件 和 当前内存中的数据结构中的数据进行 merge sort, 进行全局排序
和我们开始提的那个问题基本类似,不同的地方在于,需要对 Key 相同的元素进行 aggregation, 就是使用定义的 func 进行聚合, 比如你的算子是 reduceByKey(+), 这个func 就是加法运算, 如果两个key 相同, 就会先找到所有相同的key 进行 reduce(+) 操作,算出一个总结果 Result,然后输出数据(K,Result)元素。
SortShuffleWriter 中使用 ExternalSorter 来对内存中的数据进行排序,ExternalSorter内部维护了两个集合PartitionedAppendOnlyMap、PartitionedPairBuffer, 两者都是使用了 hash table 数据结构, 如果需要进行 aggregation, 就使用 PartitionedAppendOnlyMap(支持 lookup 某个Key,如果之前存储过相同key的K-V 元素,就需要进行 aggregation,然后再存入aggregation后的 K-V), 否则使用 PartitionedPairBuffer(只进行添K-V 元素),
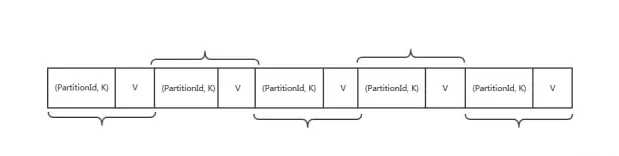
我们可以看上图, PartitionedAppendOnlyMap 中的 K 是(PatitionId, K)的元组, 这样就是先按照partitionId进行排序,如果 partitionId 相同,再按照 hash(key)再进行排序。
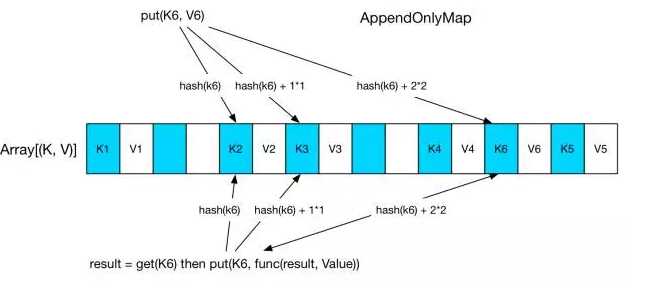
首先看下 AppendOnlyMap, 这个很简单就是个 hash table,其中的 K 是(PatitionId, hash(Key))的元组, 当要 put(K, V) 时,先 hash(K) 找存放位置,如果存放位置已经被占用,就使用 Quadratic probing 探测方法来找下一个空闲位置。对于图中的 K6 来说,第三次查找找到 K4 后面的空闲位置,放进去即可。get(K6) 的时候类似,找三次找到 K6,取出紧挨着的 V6,与先来的 value 做 func,结果重新放到 V6 的位置。
下面看下 ExternalAppendOnlyMap 结构, 这个就是内存中装不下所有元素,就涉及到外部排序,
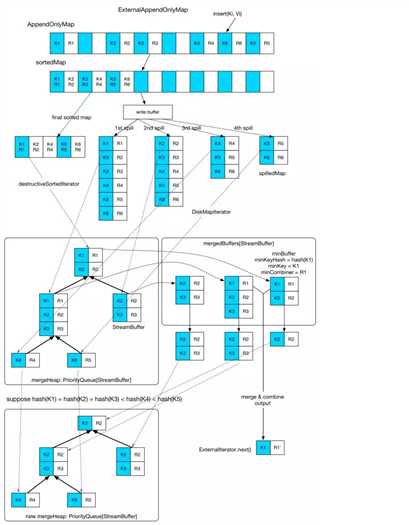
上图中可以看到整个原理图,逻辑也很简单, 内存不够的时候,先spill了四次,输出到文件中的元素都是有序的,读取的时候都是按序读取,最后跟内存剩余的数据进行 全局merge。
merge 过程就是 每个文件读取部分数据(StreamBuffer)放到 mergeHeap 里面, 当前内存中的 PartitionedAppendOnlyMap 也进行 sort,形成一个 sortedMap 放在 mergeHeap 里面, 这个 heap 是一个 优先队列 PriorityQueue, 并且自定义了排序方式,就是取出堆元素StreamBuffer的head元素进行比较大小,
val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {
// Use the reverse of comparator.compare because PriorityQueue dequeues the max
override def compare(x: Iter, y: Iter): Int = -comparator.compare(x.head._1, y.head._1)
})
这样的话,每次从堆顶的 StreamBuffer 中 pop 出的 head 元素就是全局最小的元素(记住是按照(partitionId,hash(Key))排序的), 如果需要 aggregation, 就把这些key 相同的元素放在一个一个 mergeBuffers 中, 第一个被放入 mergeBuffers 的 StreamBuffer 被称为 minBuffer,那么 minKey 就是 minBuffer 中第一个 record 的 key。当 merge-combine 的时候,与 minKey 有相同的Key的records 被 aggregate 一起,然后输出。
如果不需要 aggregation, 那就简单了, 直接把 堆顶的 StreamBuffer 中 pop 出的 head 元素 返回就好了。
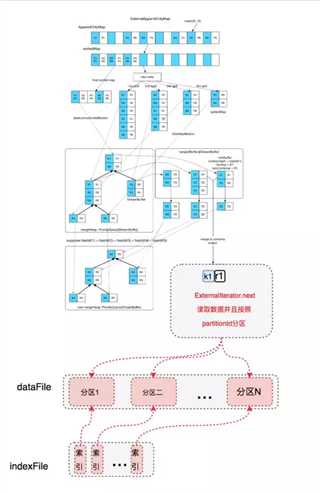
最终读取的时候,从整个 全局 merge 后的读取迭代器中读取的数据,就是按照 partitionId 从小到大排序的数据, 读取过程中使用再按照 分区分段, 并且记录每个分区的文件起始写入位置,把这些位置数据写入索引文件中。
UnsafeShuffleWriter 里面维护着一个 ShuffleExternalSorter, 用来做外部排序, 外部排序就是要先部分排序数据并把数据输出到磁盘,然后最后再进行merge 全局排序, 既然这里也是外部排序,跟 SortShuffleWriter 有什么区别呢, 这里只根据 record 的 partition id 先在内存 ShuffleInMemorySorter 中进行排序, 排好序的数据经过序列化压缩输出到换一个临时文件的一段,并且记录每个分区段的seek位置,方便后续可以单独读取每个分区的数据,读取流经过解压反序列化,就可以正常读取了。
整个过程就是不断地在 ShuffleInMemorySorter 插入数据,如果没有内存就申请内存,如果申请不到内存就 spill 到文件中,最终合并成一个 依据 partition id 全局有序 的大文件。
SortShuffleWriter 和 UnsafeShuffleWriter 对比
| 区别 | UnsafeShuffleWriter | SortShuffleWriter |
|---|---|---|
| 排序方式 | 最终只是 partition 级别的排序 | 先 partition 排序,相同分区 key有序 |
| aggregation | 没有反序列化,没有aggregation | 支持 aggregation |
没有指定 aggregation 或者key排序, 因为 key 没有编码到排序指针中,所以只有 partition 级别的排序
原始数据首先被序列化处理,并且再也不需要反序列,在其对应的元数据被排序后,需要Serializer支持relocation,在指定位置读取对应数据。 KryoSerializer 和 spark sql 自定义的序列化器 支持这个特性。
分区数目必须小于 16777216 ,因为 partition number 使用24bit 表示的。
因为每个分区使用 27 位来表示 record offset, 所以一个 record 不能大于这个值。
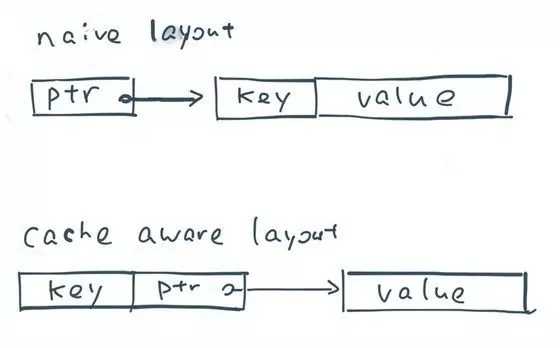
我们不妨看向对记录排序的例子。一个标准的排序步骤需要为记录储存一组的指针,并使用quicksort 来互换指针直到所有记录被排序。基于顺序扫描的特性,排序通常能获得一个不错的缓存命中率。然而,排序一组指针的缓存命中率却很低,因为每个比较运算都需要对两个指针解引用,而这两个指针对应的却是内存中两个随机位置的数据。
那么,我们该如何提高排序中的缓存本地性?其中一个方法就是通过指针顺序地储存每个记录的sort key。我们使用 8个字节(partition id 作为 key, 和数据真正的指针)来代表一条数据,放在一个 sort array 中,每次对比排序的操作只需要线性的查找每对pointer-key,从而不会产生任何的随机扫描。 这样如果对所有记录的 partion 进行排序的时候, 直接对这个数据里面的进行排序,就好了,极大的提高了性能。
当然 这里对数据排序, UnsafeShuffleWriter 使用的是 RadixSort, 这个很简单,我就不介绍了, 不同清楚的可以参考下 这个文档 http://bubkoo.com/2014/01/15/sort-algorithm/radix-sort/
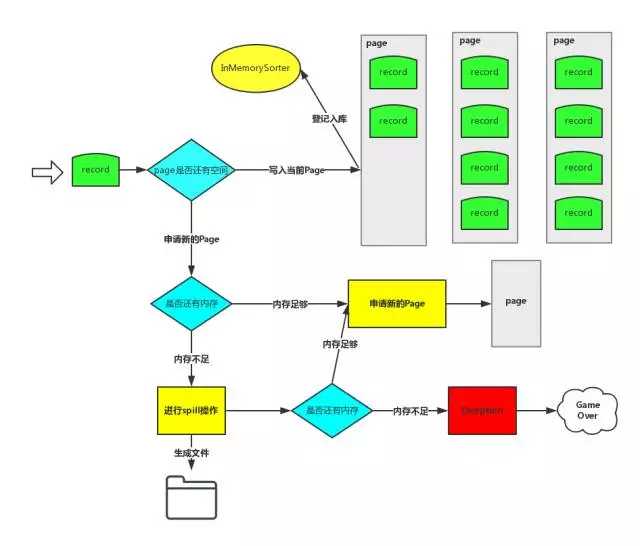
上面是申请内存的过程,申请到的内存作为 一个 page 记录在 allocatedPages 中,spill的时候进行 free 这些内存, 有一个当前使用的 currentPage, 如果不够用了,就继续去申请。
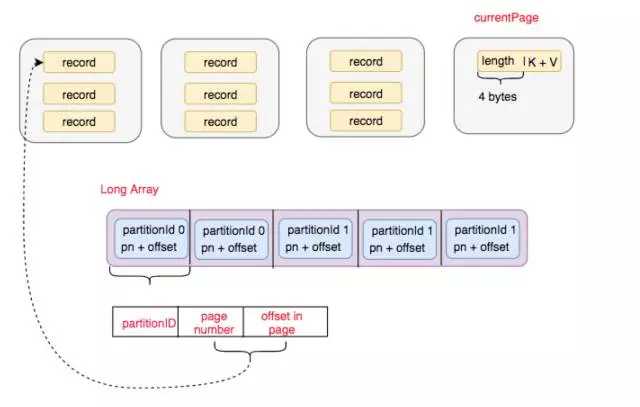
大家可以看下上面的图, 每次插入一条 record 到page 中, 就把 partionId + pageNumber + offset in page, 作为一个元素插入到 LongArray 中, 最终读取数据的时候, 对LongArray 进行 RadixSort 排序, 排序后依次根据指针元素索引原始数据,就做到 partition 级别有序了。
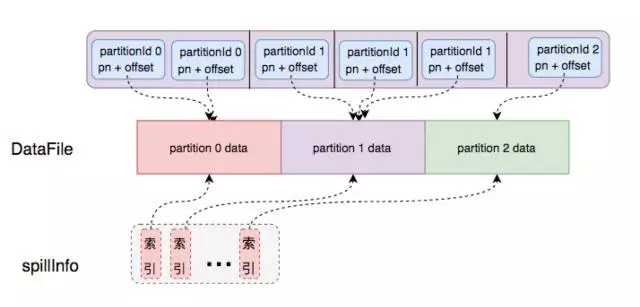
spill 文件的时候, UnsafeShuffleInMemorySorter 生成一个数据迭代器, 会返回一个根据partition id 排过序迭代器,该迭代器粒度每个元素就是一个指针,对应 PackedRecordPointer 这个数据结构, 这个 PackedRecordPointer 定义的数据结构就是 [24 bit partition number][13 bit memory page number][27 bit offset in page] 然后到根据该指针可以拿到真实的record, 在一开始进入UnsafeShuffleExternalSorter 就已经被序列化了,所以在这里就纯粹变成写字节数组了。一个文件里不同的partiton的数据用fileSegment来表示,对应的信息存在 SpillInfo 数据结构中。
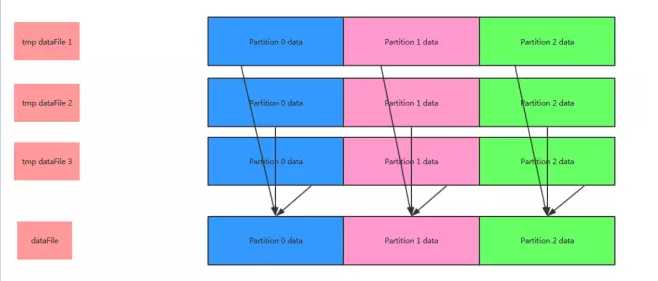
每个spill 文件的分区索引都保存在 SpillInfo 数据结构中, Task结束前,我们要做一次mergeSpills操作, 如果 fastMergeEnabled 并且压缩方式支持 concatenation of compressed data, 就可以直接 简单地连接相同分区的压缩数据到一起,而且不用解压反序列化。使用一种高效的数据拷贝技术,比如 NIO’s transferTo 就可以避免解压和 buffer 拷贝。
彻底搞懂spark的shuffle过程(shuffle write)
标签:unsafe EAP 使用 location 不同 res 表示 key ble
原文地址:https://www.cnblogs.com/itboys/p/9201750.html