标签:字段 art 简单 包含 alt 使用 star dia class
---恢复内容开始---
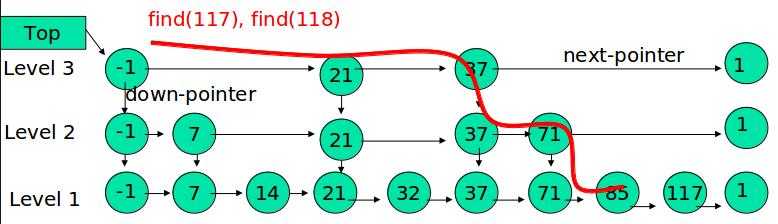
1 find(x) 2 { 3 p = top; 4 while (1) { 5 while (p->next->key < x) 6 p = p->next; 7 if (p->down == NULL) 8 return p->next; 9 p = p->down; 10 } 11 }
1 /*************************** SkipList.java *********************/ 2 3 import java.util.Random; 4 5 public class SkipList<T extends Comparable<? super T>> { 6 private int maxLevel; 7 private SkipListNode<T>[] root; 8 private int[] powers; 9 private Random rd = new Random(); 10 SkipList() { 11 this(4); 12 } 13 SkipList(int i) { 14 maxLevel = i; 15 root = new SkipListNode[maxLevel]; 16 powers = new int[maxLevel]; 17 for (int j = 0; j < maxLevel; j++) 18 root[j] = null; 19 choosePowers(); 20 } 21 public boolean isEmpty() { 22 return root[0] == null; 23 } 24 public void choosePowers() { 25 powers[maxLevel-1] = (2 << (maxLevel-1)) - 1; // 2^maxLevel - 1 26 for (int i = maxLevel - 2, j = 0; i >= 0; i--, j++) 27 powers[i] = powers[i+1] - (2 << j); // 2^(j+1) 28 } 29 public int chooseLevel() { 30 int i, r = Math.abs(rd.nextInt()) % powers[maxLevel-1] + 1; 31 for (i = 1; i < maxLevel; i++) 32 if (r < powers[i]) 33 return i-1; // return a level < the highest level; 34 return i-1; // return the highest level; 35 } 36 // make sure (with isEmpty()) that search() is called for a nonempty list; 37 public T search(T key) { 38 int lvl; 39 SkipListNode<T> prev, curr; // find the highest nonnull 40 for (lvl = maxLevel-1; lvl >= 0 && root[lvl] == null; lvl--); // level; 41 prev = curr = root[lvl]; 42 while (true) { 43 if (key.equals(curr.key)) // success if equal; 44 return curr.key; 45 else if (key.compareTo(curr.key) < 0) { // if smaller, go down, 46 if (lvl == 0) // if possible 47 return null; 48 else if (curr == root[lvl]) // by one level 49 curr = root[--lvl]; // starting from the 50 else curr = prev.next[--lvl]; // predecessor which 51 } // can be the root; 52 else { // if greater, 53 prev = curr; // go to the next 54 if (curr.next[lvl] != null) // non-null node 55 curr = curr.next[lvl]; // on the same level 56 else { // or to a list on a lower level; 57 for (lvl--; lvl >= 0 && curr.next[lvl] == null; lvl--); 58 if (lvl >= 0) 59 curr = curr.next[lvl]; 60 else return null; 61 } 62 } 63 } 64 } 65 public void insert(T key) { 66 SkipListNode<T>[] curr = new SkipListNode[maxLevel]; 67 SkipListNode<T>[] prev = new SkipListNode[maxLevel]; 68 SkipListNode<T> newNode; 69 int lvl, i; 70 curr[maxLevel-1] = root[maxLevel-1]; 71 prev[maxLevel-1] = null; 72 for (lvl = maxLevel - 1; lvl >= 0; lvl--) { 73 while (curr[lvl] != null && curr[lvl].key.compareTo(key) < 0) { 74 prev[lvl] = curr[lvl]; // go to the next 75 curr[lvl] = curr[lvl].next[lvl]; // if smaller; 76 } 77 if (curr[lvl] != null && key.equals(curr[lvl].key)) // don‘t 78 return; // include duplicates; 79 if (lvl > 0) // go one level down 80 if (prev[lvl] == null) { // if not the lowest 81 curr[lvl-1] = root[lvl-1]; // level, using a link 82 prev[lvl-1] = null; // either from the root 83 } 84 else { // or from the predecessor; 85 curr[lvl-1] = prev[lvl].next[lvl-1]; 86 prev[lvl-1] = prev[lvl]; 87 } 88 } 89 lvl = chooseLevel(); // generate randomly level 90 newNode = new SkipListNode<T>(key,lvl+1); // for newNode; 91 for (i = 0; i <= lvl; i++) { // initialize next fields of 92 newNode.next[i] = curr[i]; // newNode and reset to newNode 93 if (prev[i] == null) // either fields of the root 94 root[i] = newNode; // or next fields of newNode‘s 95 else prev[i].next[i] = newNode; // predecessors; 96 } 97 } 98 }
---恢复内容结束---
标签:字段 art 简单 包含 alt 使用 star dia class
原文地址:https://www.cnblogs.com/steve-jiang/p/9206589.html